{kind=link}
{kind=link}




Because of CGI programs, not only can you provide information over the World Wide Web, but you can receive it as well. In order to create interactive CGI applications, you must understand how CGI input works.
In this chapter, you first explore a brief history and introduction to CGI input. Then, the two ways to obtain input-through environment variables and the standard input-are discussed. Next, some strategies for parsing and storing CGI input for processing are explained. Finally, you see a few example applications.
One of the early proposed uses of the World Wide Web was as a front end to search databases over the Internet. A database interface required some way for the user to input keywords. Consequently, the <ISINDEX> tag was born.
As discussed in Chapter 3, "HTML and Forms," the <ISINDEX> tag essentially functions as a marker designed to tell the browser to get input from the user and send it back to the server. The browser determines how it prompts for the input. Because most graphical browsers display a form field somewhere on the page, some of the original versions of browsers, such as the original NCSA Mosaic, would actually open a new window and prompt the user for keywords. The <ISINDEX> tag does not give the HTML author control over the presentation of the page; it simply makes sure the user has some mechanism for submitting keywords.
After the user enters keywords, the browser sends the information back to the server by appending the keywords to the URL request. For example, suppose that you are at the following address and that index.html has an <ISINDEX> tag:
http://myserver.org/index.html
Suppose you enter the keywords avocado basketball in the ISINDEX box. The browser would then access the URL.
http://myserver.org/index.html?avocado+basketball
The URL and the keywords are separated by a question mark (?), and each keyword is separated by a plus sign (+). Other non-alphanumeric characters are encoded using the standard URL encodings as defined by RFC1738 (discussed more in the next section, "How CGI Input Works").
How the server treats a request like the preceding example depends on the server. Most servers pass the parsed keywords to the URL as command-line arguments (argv). If the URL is pointing to a script rather than a document, then you could parse the command-line arguments and process the input. Listing 5.1 shows an example program that processes <ISINDEX> input passed to the command line.
Listing 5.1. fake-dbase-search, a CGI program to process <ISINDEX> input.
#!/usr/bin/perl
if ($#ARGV == -1) {
&print_form;
}
else {
&print_results(@ARGV);
}
sub print_form {
print <<EOM;
Content-Type: text/html
<html> <head>
<title>Search Fake Database</title>
<isindex>
</head>
<body>
<h1>Search Fake Database</h1>
<p>This program pretends to search a database for the keywords you enter.
It uses the ISINDEX tag to receive user input.
</body> </html>
EOM
}
sub print_results {
local(@keywords) = @_;
print <<EOM;
Content-Type: text/html
<html> <head>
<title>Search results</title>
</head>
<body>
<h1>Search results</h1>
<p>You entered the following keywords:
<ul>
EOM
foreach (@keywords) {
print " <li>$_\n";
}
print <<EOM;
</ul>
<p>Had this been a real database search program, you could have
inserted code that would have searched a database for the keywords
you specified.
</body> </html>
EOM
}
When you access the following URL, there are no command-line arguments appended to the URL, so fake-dbase-search prints a form with an <ISINDEX> tag:
http://myserver.org/cgi-bin/fake-dbase-search
Suppose you entered the keywords patents software. The browser would then access the following URL:
http://myserver.org/cgi-bin/fake-dbase-search?patents+software
Now, fake-dbase-search has command-line arguments patents and software. In this example, fake-dbase-search simply prints what was entered. If you were writing a real database interface, you could replace the print_results function with one that actually searches a database for the keywords and returns the search results.
| Tip |
In Listing 5.1, the HTML document with the <ISINDEX> tag is embedded in the fake-dbase-search program. You can separate the form and the search program by using the <BASE> tag. Save the HTML from the print_form function into the HTML document search.html. Normally, if you tried to enter the keyword garbage, the browser would request the following: http://myserver.org/search.html?garbage Because search.html is just an HTML document, the appended parameters are ignored, and you see the HTML document with the <ISINDEX> tag again. Now, insert the following within the <head> tags: <BASE HREF="http://myserver.org/cgi-bin/fake-dbase-search"> Now, when you access the HTML document and fill out the keywords, the browser sends the following request, which will process your request correctly: http://myserver.org/cgi-bin/fake-dbase-search?garbage More information on the <BASE> tag appears in Chapter 3. |
Note |
Some servers (such as certain versions of the CERN server) enable you to specify a program to process all <ISINDEX> requests. For example, you could configure your server to use the program called search-dbase to process all <ISINDEX> requests. When the server receives a request such as http://myserver.org/search.html?hello+there the server would run the program search-dbase for the keywords hello and there, regardless of whether a different <BASE> URL was specified or not. |
For a while, the <ISINDEX> tag was the sole means of obtaining user input; however, it was unsatisfactory in this role for a number of reasons. First, <ISINDEX> does not offer the Web author any control over how the interface should look. A text field might not be the most desirable interface; you, the author, might prefer to offer a menu of options from which the user should choose. Second, <ISINDEX> enables you to store only one variable-the keywords. Finally, how the server deals with the input from the <ISINDEX> tag is implementation-specific. A more flexible means of processing input seemed desirable.
Consequently, HTML forms (described in Chapter 3) and CGI were introduced to extend this input functionality. CGI enables you to process input values for several different variables, whereas the HTML forms offer the document designer flexibility in designing the interface.
To best understand how CGI input works, think of what you are trying to achieve.
You have two types of data: the form data and information about the browser and server. Information about the browser and server are available through environment variables passed to the CGI program. The form data gets passed in one of two ways, either through an environment variable-called the GET method-or through the standard input (stdin)-called the POST method. You learn why the two methods exist and the differences between them in "GET Versus POST," later in this chapter.
Regardless of whether any form data is being passed to the CGI program or not, every CGI application receives information about both the browser and the server through environment variables.
If you use UNIX or DOS, you might already know about environment variables. When you run a program, it has an environment space where it can store variables. A common environment variable on most systems is the PATH variable, which tells the operating system where to search for applications.
The environment variables defined for CGI applications provide
information such as the
following:
A certain set of environment variables are always set by servers abiding by the CGI protocol. Also, a few other environment variables exist which, while not defined in the CGI protocol, are often passed to the CGI program.
Tip |
To get environment variables using C, use the function getenv() (from stdlib.h). For example, to assign the value of the environment variable QUERY_STRING to the string forminput, use #include <stdlib.h> Perl defines an associative array-%ENV-that stores the environment variables. The array is keyed by the name of the variable. $forminput = $ENV{'QUERY_STRING'}; |
| Tip |
The C library, cgihtml, stores all of the CGI environment variables for you in global macros. For example, when you include the cgi-lib.h header file, you can access the QUERY_STRING environment variable via the string QUERY_STRING. #include "cgi-lib.h" |
This section defines the most general of the environment variables, those that every CGI script will need to be able to read input from the server.
GATEWAY_INTERFACE describes the version of the CGI protocol being used. The current version of the protocol is 1.1, so the value of this variable is almost always CGI/1.1.
SERVER_PROTOCOL describes the version of the HTTP protocol. Most servers understand version 1.0, hence this value is usually HTTP/1.0.
REQUEST_METHOD is either equal to GET or POST, depending on the method used to send the data to the CGI program.
This section defines those variables that can contain the actual input data being passed from the server to the CGI program.
The user can specify a path value (relative to the document root) when he or she accesses a CGI program by appending a slash (/) followed by the path information. For example, if you access the following URL, PATH_INFO for mail.cgi is equal to /images:
http://myserver.org/cgi-bin/mail.cgi/images
PATH_TRANSLATED is the equivalent value of PATH_INFO relative to your file system. If your document root is
/usr/local/etc/httpd/htdocs
and you access the following URL, PATH_TRANSLATED is equal to /usr/local/etc/httpd/htdocs/images:
http://myserver.org/cgi-bin/mail.cgi/images
PATH_TRANSLATED will also parse user HTML paths (for example, paths preceded by a tilde (~)) and aliased paths correctly.
This variable contains input data if the server is sending data using the GET method. It will always contain the value of the string following the URL and separating question mark, regardless of how information is being passed to the CGI program. For example, if you access the following:
http://myserver.org/cgi-bin/mail.cgi?static
directly from the command line, the value of QUERY_STRING is static even though the information is being passed directly and is not a series of name/value pairs. You learn how to take advantage of QUERY_STRING later in "GET Versus POST."
CONTENT_TYPE contains a MIME type that describes how the data is being encoded. By default, CONTENT_TYPE will be
application/x-www-form-urlencoded
Note that this is the same MIME type normally specified in the ENCTYPE parameter of the <form> tag (as described in Chapter 3).
One other value that browsers are starting to support is the multipart/form-data MIME type, used for HTTP file uploading. This value is described in detail in Chapter 14, "Proprietary Extensions."
CONTENT_LENGTH stores the length of the input being passed to the CGI program. This variable is defined only when the server is using the POST method. For example, if the following is your input string, then CONTENT_LENGTH is 24 because there are 24 characters in this string:
name=sujean°ree=music
This section defines environment variables that deal with information about the server.
SERVER_SOFTWARE is the name and version of the server you are using.
SERVER_NAME is the name of the machine running your server.
This is the e-mail address of the administrator of your Web server. Not all servers define this variable.
This is the port on which your server is running. The default port for Web servers is 80.
This is the name of the CGI program. You can use SCRIPT_NAME to write a CGI program that reacts differently depending on the name used to call it. For example, you could write a CGI program that would display a picture of a cat if SCRIPT_NAME was cat or a picture of a dog if SCRIPT_NAME was dog. The CGI program would be the same, but you would save it twice: one time as cat and the other as dog.
This is the value of the document root on your server. For example, if your document root is /usr/local/etc/httpd/, the value of DOCUMENT_ROOT is /usr/local/etc/httpd/.
This section defines environment variables that deal with information about the client (browser).
This is the name of the machine currently requesting or passing information to your CGI program. For example, if someone at toyotomi.student.harvard.edu is browsing your Web site, the value of REMOTE_HOST passed to the CGI program is toyotomi.student.harvard.edu.
This is the IP address of the client machine. For example, if someone at IP address 140.247.187.95 is currently browsing your Web site, the value of REMOTE_ADDR is 140.247.187.95. Both REMOTE_HOST and REMOTE_ADDR can be useful for writing programs that will respond differently depending on the point from which you are browsing the Web site. REMOTE_ADDR tends to be a more reliable value, because not all machines on a TCP/IP network like the Internet have host names, but all of them will have an IP address.
If you have entered a valid username to browse an access-restricted area on the server, your username is stored in REMOTE_USER. By default, REMOTE_USER is empty. If you access a page with access restrictions, the server first checks REMOTE_USER to see if you have authenticated yourself already. If not, it responds with a status code of 401 (for more information on status codes, see Chapter 4, "Output"). When the client receives this status code, it prompts you for the appropriate information, usually a username and a password.
If you enter a valid username and password, your username is stored in REMOTE_USER. The next time you try and access those pages, the server checks REMOTE_USER, finds a value, and enables you to see the appropriate pages.
Some servers have group authentication as well as user authentication. With group authentication, you usually enter your username, and the server looks to see whether you belong to the appropriate group. If you do, it stores that value in REMOTE_GROUP and enables you to access the appropriate documents. Not all servers support this form of authentication.
AUTH_TYPE defines the authorization scheme being used, if any. The most common authentication scheme is Basic.
Although the server and CGI program can determine the name of the client machine and address currently connected, it normally cannot determine the user on the client machine accessing your pages. A network protocol known as the IDENT protocol enables querying servers to determine which users from which machines are connecting to your server. (More information about the IDENT protocol is available in RFC931.) If your server supports IDENT, it will pass to REMOTE_IDENT the username of the person accessing your server.
Most servers don't support IDENT because it is an additional load on the server and because most clients don't support the IDENT protocol. Even if the client does support IDENT, you have no way of knowing whether it is giving you the correct information or not. Unless you can be sure that the clients are providing the correct IDENT information and you absolutely need this type of service, you don't need a server that supports IDENT; consequently, you will not need to deal with REMOTE_IDENT.
Many browsers pass additional information about their capabilities to the server, which in turn passes this information to the CGI program in the form of environment variables. These variables are prefixed with HTTP_.
HTTP_ACCEPT contains a list of MIME types that the browser is capable of interpreting itself. Each MIME type is separated by a comma. For example, a graphical browser that can display both GIF and JPEG images might list the following:
image/gif, image/jpeg in HTTP_ACCEPT
HTTP_ACCEPT is a useful environment variable for content negotiation. For example, you can determine whether or not a browser is a graphical browser or a text browser by searching HTTP_ACCEPT for an image MIME type.
| Note |
Unfortunately, many browsers do not take advantage of HTTP_ACCEPT as a general scheme for telling the server its capabilities. For example, the Netscape browser supports several of the HTML version 3.0 tags. The appropriate way to pass this information would be text/html; version=3.0 Unfortunately, Netscape (and many other browsers that support these extended HTML tags) does not pass this information. In order to do any advanced content negotiation, you need to determine the browser type and version, and you need to know what most browsers are capable of doing. |
This variable stores the browser name, version, and usually its platform. Normally, the format of HTTP_USER_AGENT is
Browser/Version (Operating System)
Tip |
Some browsers have special features and extended HTML tags that other browsers don't have. One type of CGI application determines whether you are using a certain browser by checking the HTTP_USER_AGENT. If you are using the browser, it sends a special page; otherwise, it sends a standard page. Some common HTTP_USER_AGENT values are Lynx/2.4.2 Mozilla is the nickname for Netscape Navigator, currently the most popular Web browser. Some browsers that support HTML v3.0 extensions will also send Mozilla as the HTTP_USER_AGENT so that your content-negotiation programs that check this variable will work properly. Some browsers also don't send any value at all for HTTP_USER_AGENT. It's preferable to write well-written, general HTML documents rather than a special page for every type of browser. |
HTTP_REFERER stores the URL of the previous page that referred you to the current URL. For example, if you have a page
http://myserver.org/toc.html
with a link to
http://myserver.org/chapter1.html
and you click on that link, the value of HTTP_REFERER is
http://myserver.org/toc.html
Tip |
It's good practice to include a link back to the previous page on your HTML documents. Unfortunately, several pages might be linked to your CGI program, and you don't want to put a link back to each of them. You can use HTTP_REFERER to dynamically create the correct link. In Perl, this might look like the following: print "<a href=\"$ENV{'HTTP_REFERER'}\">Go Back to Previous Page</a>\n"; |
Many Web browsers now tell the server what languages they support. This information gets passed to the CGI program in the HTTP_ACCEPT_LANGUAGE environment variable. For example, a value of en signifies that the Web browser understands English.
The CGI environment variables alone provide a wealth of information for the CGI application. In Chapter 10, "Basic Applications," several simple applications are given, some of which use only environment variables and CGI output.
As a brief example, extend the graphical counter program from Chapter 4 to use environment variables. The biggest problem with counter.cgi from Chapter 4 is its lack of flexibility. The location of the counter data file that stores the number of accesses is hard coded into the program. Ideally, you want one counter program that can keep track of access counts for all of your pages.
In order to extend the counter.cgi program, the PATH_TRANSLATED environment variable is used to specify which document you want to track. To do this, you would specify the location of the document you want to track following the URL. For example, if you want to display the access count for index.html, located in the document root, you would include the filename after the program's location in the <img> tag.
<img src="/cgi-bin/counter.cgi/index.html">
In this case, PATH_INFO is /index.html. Assuming your document root is /usr/local/etc/httpd/htdocs, PATH_TRANSLATED is
/usr/local/etc/httpd/htdocs/index.html
Call the file that stores the counter data the value of PATH_TRANSLATED plus .COUNT. In this example, the data file would be
/usr/local/etc/httpd/htdocs/index.html.COUNT
In the same vein, the lock file would be called
/usr/local/etc/httpd/htdocs/index.html.LOCK
What has to change in the old counter.cgi? First, the default values for DATAFILE and LOCKFILE have no use. You don't want a default value at all. If the user doesn't specify a file to keep track of, then counter.cgi should return an error. In order to determine the values for DATAFILE and LOCKFILE, check the PATH_TRANSLATED environment variable.
The new counter.cgi is in Listing 5.2. Notice that the code changed minimally. All it required were some minor changes to the increment() function.
Listing 5.2. New and improved counter.cgi.
/* counter.cgi.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "html-lib.h"
#define COUNTER_WIDTH 7
#define DIGIT_WIDTH 8
#define DIGIT_HEIGHT 12
static char *digits[10][12] = {
{"0x7e", "0x7e", "0x66", "0x66", "0x66", "0x66",
"0x66", "0x66", "0x66", "0x66", "0x7e", "0x7e"},
{"0x18", "0x1e", "0x1e", "0x18", "0x18", "0x18",
"0x18", "0x18", "0x18", "0x18", "0x7e", "0x7e"},
{"0x3c", "0x7e", "0x66", "0x60", "0x70", "0x38",
"0x1c", "0x0c", "0x06", "0x06", "0x7e", "0x7e"},
{"0x3c", "0x7e", "0x66", "0x60", "0x70", "0x38",
"0x38", "0x70", "0x60", "0x66", "0x7e", "0x3c"},
{"0x60", "0x66", "0x66", "0x66", "0x66", "0x66",
"0x7e", "0x7e", "0x60", "0x60", "0x60", "0x60"},
{"0x7e", "0x7e", "0x02", "0x02", "0x7e", "0x7e",
"0x60", "0x60", "0x60", "0x66", "0x7e", "0x7e"},
{"0x7e", "0x7e", "0x66", "0x06", "0x06", "0x7e",
"0x7e", "0x66", "0x66", "0x66", "0x7e", "0x7e"},
{"0x7e", "0x7e", "0x60", "0x60", "0x60", "0x60",
"0x60", "0x60", "0x60", "0x60", "0x60", "0x60"},
{"0x7e", "0x7e", "0x66", "0x66", "0x7e", "0x7e",
"0x66", "0x66", "0x66", "0x66", "0x7e", "0x7e"},
{"0x7e", "0x7e", "0x66", "0x66", "0x7e", "0x7e",
"0x60", "0x60", "0x60", "0x66", "0x7e", "0x7e"},
};
short file_exist(char *filename)
{
FILE *stuff;
if ((stuff = fopen(filename,"r")) == 0)
return 0;
else {
fclose(stuff);
return 1;
}
}
void lock_file(char *filename)
{
FILE *lock;
lock = fopen(filename,"w");
/* write process ID here; UNIX only */
fprintf(lock,"%d\n",getpid());
fclose(lock);
}
void unlock_file(char *filename)
{
unlink(filename);
}
void wait_for_lock(char *filename)
{
FILE *lock;
while (file_exist(filename)) {
fclose(lock);
sleep(2);
}
}
void cgi_error(char *msg)
{
html_header();
html_begin(msg);
h1(msg);
printf("<hr>\n");
printf("There has been an error. Please report this to\n");
printf("our web administrator. Thanks!\n");
html_end();
exit(1);
}
int increment(char *pathandfile)
{
FILE *data;
char number_string[10]; /* won't have a number greater than 9 digits */
char *DATAFILE, *LOCKFILE;
int number;
if ( (pathandfile == NULL) || !(file_exist(pathandfile)) )
cgi_error("Invalid File Specified");
DATAFILE = malloc(sizeof(char) * (strlen(pathandfile) + 6) + 1);
strcpy(DATAFILE,pathandfile);
strcat(DATAFILE,".COUNT");
LOCKFILE = malloc(sizeof(char) * (strlen(pathandfile) + 5) + 1);
strcpy(LOCKFILE,pathandfile);
strcat(LOCKFILE,".LOCK");
/* read data */
if ((data = fopen(DATAFILE,"r")) == NULL) {
if ((data = fopen(DATAFILE,"w")) == NULL)
cgi_error("Can't Write to File");
strcpy(number_string,"0");
fprintf(data,"%s\n",number_string);
}
else
fgets(number_string,10,data);
fclose(data);
number = atoi(number_string);
number++;
wait_for_lock(LOCKFILE);
lock_file(LOCKFILE);
/* write new value */
if ((data = fopen(DATAFILE,"w")) == 0) {
unlock_file(LOCKFILE); /* don't leave any stale locks */
cgi_error("Can't Write To File");
}
fprintf(data,"%d\n",number);
fclose(data);
unlock_file(LOCKFILE);
return number;
}
int main()
{
int number = increment(getenv("PATH_TRANSLATED"));
int i,j,numbers[COUNTER_WIDTH];
/* convert number to numbers[] */
for (i = 1; i <= COUNTER_WIDTH; i++) {
numbers[COUNTER_WIDTH - i] = number % 10;
number = number / 10;
}
/* print the CGI header */
printf("Content-Type: image/x-xbitmap\r\n\r\n");
/* print the width and height values */
printf("#define COUNTER_WIDTH %d\n",COUNTER_WIDTH * DIGIT_WIDTH);
printf("#define counter_height %d\n",DIGIT_HEIGHT);
/* now print the bitmap */
printf("static char counter_bits[] = {\n");
for (j = 0; j < DIGIT_HEIGHT; j++) {
for (i = 0; i < COUNTER_WIDTH; i++) {
printf("%s",digits[numbers[i]][j]);
if ((i < COUNTER_WIDTH - 1) || (j < DIGIT_HEIGHT - 1))
printf(", ");
}
printf("\n");
}
printf("}\n");
}
Form data consists of a list of name/value pairs. Before transmitting this data to the server and the CGI program, the browser encodes the information using a scheme called URL encoding (specified by the MIME type application/x-www-form-urlencoded). The encoding scheme consists of the following:
For example, suppose you have the following name/value pairs:
name | Eugene Eric Kim |
age | 21 |
eekim@hcs.harvard.edu |
In order to encode these pairs, you first need to replace the non-alphanumeric characters. In this example, only one character exists, @, which you replace with %40. So now you have
name | Eugene Eric Kim |
age | 21 |
eekim%40hcs.harvard.edu |
Now, replace all spaces with plus signs.
name | Eugene+Eric+Kim |
age | 21 |
eekim%40hcs.harvard.edu |
Separate each name and value with an equals sign:
name=Eugene+Eric+Kim
age=21
email=eekim%40hcs.harvard.edu
Finally, separate each pair with an ampersand:
name=Eugene+Eric+Kim&age=21&email=eekim%40hcs.harvard.edu
The Content-Length is equal to the number of characters in this encoded string. This example has 57 characters, so the Content-Length is 57.
After your string is encoded, you have two ways to send that information to the server and the CGI application. You could either append the information to the URL (the GET method) or send it via the standard input (the POST method).
| Note |
By default, if you do not specify the method in the <form> tag, the browser assumes the GET method. |
For example, in order to pass the string
name=Eugene+Eric+Kim&age=21&email=eekim%40hcs.harvard.edu
to the CGI program process.cgi, the browser would append a question mark to the end of the URL followed by the string
http://myserver.org/cgi-bin/process.cgi?name=Eugene+Eric+Kim&age=21
Â&email=eekim%40hcs.harvard.edu
Everything in the URL after the question mark is stored in the variable QUERY_STRING. Then, process.cgi must parse the string into something usable.
The GET method has a few inherent problems. First, the length of the encoded string is limited by the maximum allowable size of the environment variable QUERY_STRING. Although the exact value varies from system to system, you generally cannot have a string longer than 1KB (1024 characters). Consequently, the GET method does not work for large form input.
Second, the GET method is aesthetically displeasing. URLs can be long and ugly; however, the problem is not just cosmetic, but practical as well. Your server access log files normally store the value of each URL accessed; if your URLs are long, your log files will be very large as well. Many server log analyzers say how many times a specific URL has been accessed. The same URL might get counted multiple times if different inputs are appended to it. Finally, those who access your site might be concerned about their privacy. They might not want people to be able to see what input values they enter for certain forms. For example, if you have a CGI front end to a database using the GET method, the server will log all query input strings. Users might be uncomfortable with the idea of having all of their queries logged.
| Note |
Both the GET and ISINDEX methods send their requests to the server by appending a question mark and an input string to the end of a URL. How does the server differentiate between the two? Remember, one limitation of ISINDEX is that it accepts only one value. Consequently, this one value needs no identifying name, so you never see an equals sign in an ISINDEX request. When the server receives the URL request, it looks for an equals sign. If it doesn't find one, it assumes the request is an ISINDEX request and acts accordingly (usually by parsing the input string and passing it to a program as command-line parameters). Regardless of whether the request is of the GET method or an ISINDEX request, the encoded input value is stored, unparsed, in the environment variable QUERY_STRING. If you opened the following URL: http://myserver.org/cgi-bin/mail.cgi?eekim%40hcs.harvard.edu the value eekim%40hcs.harvard.edu would be stored in QUERY_STRING, while the parsed value eekim@hcs.harvard.edu would get passed to the command-line argument. You can pass parameters to QUERY_STRING and pass input using the POST method at the same time, a useful technique for making your CGI programs more general and more powerful. |
Mainly because of the GET method's physical constraints, one other means of transmitting input from browser to server exists: the POST method. When the server receives information from the browser via the POST method, the server passes the information to the CGI program by sending data to the standard input (stdin). The server also passes the length of the encoded input string to the environment variable CONTENT_LENGTH. POST does not have the constraints that GET has. (You learn about the exact mechanism for passing the input string from the browser to the server using the POST method in Chapter 8, "Client/Server Issues.")
Why use the GET method when the POST method seems to have no real constraints? The capability to specify an input string in the URL is useful for quickly sending information to a CGI program. Storing information on the URL is also useful for storing state information about the URL. Maintaining state with CGI programs appears in Chapter 13, "Multipart Forms and Maintaining State."
After a CGI program receives the encoded form input, it needs to parse the string and store it so that you can use the data. Because you know the data is in the form of a bunch of name/value pairs, you could design a fairly primitive data structure that stored these name/value pairs in an easily accessible manner. This data structure, along with your parsing routines, could then be used in all of your CGI programs.
Several people have written libraries in many different languages that parse CGI input and store the values in a data structure. The steps for parsing are straightforward in any language.
Caution |
Decoding order is important. Suppose you have the following name/value pairs: y = x The encoded string for this is y%3D=x&xmin=-5&xmax=5 If you decoded the hexadecimal values first, you would get y==x&xmin=-5&xmax=5 Because two equal signs appear in the first record, how the parser reacts to this string is fairly unpredictable. There is a good chance that it will guess wrong and give you garbled values. |
The first step of the parsing requires separating the name/value pairs into records; thus, a data structure that defines these records is necessary. Although you can use almost any data structure, you want to take into consideration the nature of the input and the capabilities and constraints of your language.
For example, in Perl, the most obvious data structure to use is Perl's built-in associative arrays. The associative array would store the input values keyed by their corresponding names. Steve Brenner's cgi-lib.pl uses this approach. Another approach for Perl 5 users is to create a Perl 5 CGI object and a method that retrieves the values stored in this object. Lincoln Stein's CGI.pm Perl 5 package works this way.
Choosing and implementing a data structure in C is more complex because C doesn't have any built-in data structures. Because most CGI programs are not processing enormous amounts of data, a good data structure is a simple linked list, which is what the original cgihtml library uses. If you know you will process much larger amounts of data, you might want to consider using a different data structure, one that uses some sort of hashing algorithm.
Unless you are writing a very specialized application, you should be able to use someone else's parsing and data structure code for processing CGI input. The following sections discuss two libraries in detail-cgi-lib.pl for Perl and cgihtml for C.
In cgi-lib.pl, you use the ReadParse function to store the name/value pairs in an associative array. The code for ReadParse is in Listing 5.3.
Listing 5.3. ReadParse (from Steve Brenner's cgi-lib.pl).
sub ReadParse {
local (*in) = @_ if @_;
local ($i, $key, $val);
# Read in text
if (&MethGet) {
$in = $ENV{'QUERY_STRING'};
} elsif (&MethPost) {
read(STDIN,$in,$ENV{'CONTENT_LENGTH'});
}
@in = split(/[&;]/,$in);
foreach $i (0 .. $#in) {
# Convert plus's to spaces
$in[$i] =~ s/\+/ /g;
# Split into key and value.
($key, $val) = split(/=/,$in[$i],2); # splits on the first =.
# Convert %XX from hex numbers to alphanumeric
$key =~ s/%(..)/pack("c",hex($1))/ge;
$val =~ s/%(..)/pack("c",hex($1))/ge;
# Associate key and value
$in{$key} .= "\0" if (defined($in{$key})); # \0 is the multiple separator
$in{$key} .= $val;
}
return scalar(@in);
}
More than one name/value pair can have the same name. If this occurs, ReadParse stores all of the values in the same associative array entry, separated by a null character.
The minimal code for parsing any form input is shown in Listing 5.4. All of the input data gets stored in the associative array %input keyed by name. If you want to access the value with the name phone, you would access $input{'phone'}.
Listing 5.4. Minimal Perl code using cgi-lib.pl.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
&ReadParse(*input);
Using ReadParse, you can write a simple Perl test script called query-results.cgi that returns the parsed name/value pairs. The code for query-results.cgi is in Listing 5.5.
Listing 5.5. Query-results.cgi in Perl.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
&ReadParse(*input);
print &PrintHeader,&HtmlTop("Query Results"),"<dl>\n";
foreach $name (keys(%input)) {
foreach (split("\0", $in{$name})) {
($value = $_) =~ s/\n/<br>\n/g;
print "<dt><b>$name</b>\n";
print "<dd><i>$value</i><br>\n";
}
}
print "</dl>\n",&HtmlBot;
In query-results.cgi, parsing the input requires only one line of code because someone else has already written the function for you. A good CGI programming library will simplify your programming tasks so that you never need to worry about parsing input.
| Tip |
The cgi-lib.pl library comes with the PrintVariables function that prints the name and value pairs in HTML form. Therefore, you can simplify query-results.cgi even further, as seen in Listing 5.6. |
Listing 5.6. Simpler query-results.cgi using cgi-lib.pl.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
&ReadParse(*input);
print &PrintHeader,&HtmlTop("Query Results"),&PrintVariables(%input),&HtmlBot;
A complete reference to cgi-lib.pl is in Appendix D, "cgi-lib.pl Reference Guide."
Processing CGI input in C is more complex than it is in Perl; consequently, cgihtml is more complex internally. As you will shortly see, however, your CGI programs in C can be just as simple as the ones in Perl from the preceding section.
First, you need to define a data structure. cgihtml defines a linked list in llist.h as seen in Listing 5.7.
Listing 5.7. Linked list in llist.h (from Eugene Kim's cgihtml).
typedef struct {
char *name;
char *value;
} entrytype;
typedef struct _node {
entrytype entry;
struct _node* next;
} node;
typedef struct {
node* head;
} llist;
Every entry in the linked list stores the name and value pairs
separately, as shown in Figure 5.1. In
order to access a value, you need to go through each entry in
the list from the beginning and look at every name until you reach
the correct one. Because most CGI programs have a relatively small
number of name/value pairs, you have no reason to sacrifice this
small and simple data structure for a more complex and efficient
one.
Figure 5.1 : A graphical depiction of the type llist
The read_cgi_input() function (listed in Listing 5.8) is equivalent to cgi-lib.pl's ReadParse function, except that it places the name/value pairs in the linked list. read_cgi_input() uses the functions x2c() and unescape_url() to decode the URL-encoded characters. Both of these functions come from the NCSA example code.
Listing 5.8. read_cgi_input().
/* x2c() and unescape_url() stolen from NCSA code */
char x2c(char *what)
{
register char digit;
digit = (what[0] >= 'A' ? ((what[0] & 0xdf) - 'A')+10 : (what[0] - '0'));
digit *= 16;
digit += (what[1] >= 'A' ? ((what[1] & 0xdf) - 'A')+10 : (what[1] - '0'));
return(digit);
}
void unescape_url(char *url)
{
register int x,y;
for (x=0,y=0; url[y]; ++x,++y) {
if((url[x] = url[y]) == '%') {
url[x] = x2c(&url[y+1]);
y+=2;
}
}
url[x] = '\0';
}
int read_cgi_input(llist* entries)
{
int i,j,content_length;
short NM = 1;
char *input;
entrytype entry;
node* window;
list_create(entries);
window = (*entries).head;
/* get the input */
if (REQUEST_METHOD == NULL) {
/* perhaps add an HTML error message here for robustness sake;
don't know whether CGI is running from command line or from
web server. In fact, maybe a general CGI error routine might
be nice, sort of a generalization of die(). */
fprintf(stderr,"caught by cgihtml: REQUEST_METHOD is null\n");
exit(1);
}
if (!strcmp(REQUEST_METHOD,"POST")) {
if (CONTENT_LENGTH != NULL) {
content_length = atoi(CONTENT_LENGTH);
input = malloc(sizeof(char) * content_length + 1);
if (fread(input,sizeof(char),content_length,stdin) != content_length) {
/* consistency error. */
fprintf(stderr,"caught by cgihtml: input length < CONTENT_LENGTH\n");
exit(1);
}
}
else { /* null content length */
/* again, perhaps more detailed, robust error message here */
fprintf(stderr,"caught by cgihtml: CONTENT_LENGTH is null\n");
exit(1);
}
}
else if (!strcmp(REQUEST_METHOD,"GET")) {
if (QUERY_STRING == NULL) {
fprintf(stderr,"caught by cgihtml: QUERY_STRING is null\n");
exit(1);
}
input = newstr(QUERY_STRING);
content_length = strlen(input);
}
else { /* error: invalid request method */
fprintf(stderr,"caught by cgihtml: REQUEST_METHOD invalid\n");
exit(1);
}
/* parsing starts here */
if (content_length == 0)
return 0;
else {
j = 0;
entry.name = malloc(sizeof(char) * content_length + 1);
entry.value = malloc(sizeof(char) * content_length + 1);
for (i = 0; i < content_length; i++) {
if (input[i] == '=') {
entry.name[j] = '\0';
unescape_url(entry.name);
if (i == content_length - 1) {
strcpy(entry.value,"");
window = list_insafter(entries,window,entry);
}
j = 0;
NM = 0;
}
else if ( (input[i] == '&') || (i == content_length - 1) ) {
if (i == content_length - 1) {
entry.value[j] = input[i];
j++;
}
entry.value[j] = '\0';
unescape_url(entry.value);
window = list_insafter(entries,window,entry);
j = 0;
NM = 1;
}
else if (NM) {
if (input[i] == '+')
entry.name[j] = ' ';
else
entry.name[j] = input[i];
j++;
}
else if (!NM) {
if (input[i] == '+')
entry.value[j] = ' ';
else
entry.value[j] = input[i];
j++;
}
}
return 1;
}
}
read_cgi_input() does not have the same problems that ReadParse did of multiple values with the same name because each name/value pair is stored in its own entry.
When you use read_cgi_input() you must first declare a linked list (see Listing 5.9 for an example). Also, when the program is complete you need to remember to clear the linked list using the list_clear() function.
Listing 5.9. Using read_cgi_input().
#include "cgi-lib.h"
int main()
{
llist entries;
read_cgi_input(&entries);
list_clear(&entries);
}
| Note |
llist.h is included in cgi-lib.h, so you don't need to include it in the main program. |
You can write query-results.cgi in C using cgihtml, as shown in Listing 5.10.
Listing 5.10. Query-results.cgi using cgihtml.
#include <stdio.h>
#include "cgi-lib.h"
#include "html-lib.h"
int main()
{
llist entries;
node *window;
read_cgi_input(&entries);
html_header();
html_begin("Query Results");
window = entries.head;
printf("<dl>\n");
while (window != NULL) {
printf(" <dt><b>%s</b>\n",(*window).entry.name);
printf(" <dd> %s\r\n",replace_ltgt((*window).entry.value));
window = (*window).next;
}
printf("</dl>\r\n");
html_end();
list_clear(&entries);
}
The C version of query-results.cgi does the equivalent of the Perl version in almost as few lines.
Rather than using linked list routines to access name/value pairs, you can use the function cgi_val(). The proper syntax for cgi_val() is
cgi_val(entries,name);
where entries is the linked list of entries and name is the name. For example, to print the value of the entry "phone" from the linked list entries, you would use
printf("%s\n",cgi_val(entries,"phone"));
| Tip |
cgihtml also provides a function called print_entries() that prints all of the name/value pairs in an HTML list. A simplified version of query-results.cgi in C is shown in Listing 5.11. |
Listing 5.11. Simplified query-results.cgi using cgihtml.
#include "cgi-lib.h"
#include "html-lib.h"
int main()
{
llist entries
read_cgi_input(&entries);
html_header();
html_begin("Query Results");
print_entries(entries);
html_end();
list_clear(&entries);
}
Using a good programming library can make writing CGI in any language very easy.
A complete reference guide to cgihtml is located in Appendix E, "cgihtml Reference Guide."
Receiving and interpreting CGI input is not too difficult, especially with the aid of programming libraries such as cgi-lib.pl, cgihtml, and others. You will have more difficulty deciding how to best take advantage of the tools that you have.
In general, if you have CGI programs that solely process data from an HTML form, use the POST method. You have no reason not to use the POST method if all you do is process the information sent by a form.
When you are processing form input, remember some of the quirks of certain form elements such as radio buttons. If radio buttons and checkboxes remain unchecked, their names will not get sent to the CGI program. On the other hand, with every other type of input field, if the field is empty, a name with an empty corresponding value is sent.
For example, the form in Listing 5.12 provides one text field and one checkbox. If you enter edward in the text field and leave the checkbox unchecked, the input string looks like
text=edward
If you check the checkbox as well, the string becomes
text=edward&box=on
In the first case, as far as the CGI program is concerned, the checkbox doesn't even exist. In the second case, you see a value for your checkbox. In yet another scenario, suppose you leave the text field empty, but check the checkbox. The string looks like the following:
text=&box=on
Even though you left the text field empty, the field name is still passed with an empty value.
Listing 5.12. Sample-form.html.
<html> <head>
<title>Sample Form</title>
</head>
<body>
<h1>Sample Form</h1>
<form method=POST action="/cgi-bin/query-results.cgi">
<p>Text Field: <input type=text name="text"><br>
<input type=checkbox name="box" value="on">Just say no?
<input type=submit>
</form>
</body> </html>
When you are writing your CGI program, you want to make sure your program handles such fields correctly and is robust enough not to fail when it receives unexpected input. Don't assume you know exactly what fields are going to get filled. Make sure the name/value pairs you expect exist before you process them, and make sure you properly deal with any unexpected input.
You can write more flexible CGI programs by using the QUERY_STRING and the POST method simultaneously. For example, you might want to write an e-mail gateway called mail.cgi that would e-mail the POSTed results of a form to an e-mail address specified by the QUERY_STRING. An example of this process appears in Chapter 10, in which there is an example of a mail gateway program.
The QUERY_STRING and PATH_INFO environment variables work well for keeping track of the state of your forms. This topic is discussed in great detail in Chapter 11,"Gateways." In general, know what environment variables are available and what they do; you will often find interesting uses of these variables in your programs.
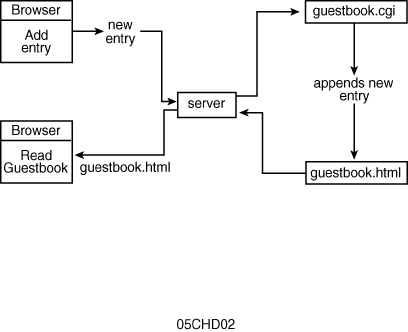
You now know enough about the protocol to write a full-fledged CGI application. This section starts by discussing a common application found over the World Wide Web: a guestbook.
You want to provide a forum so visitors to your Web site can sign in, make comments about your Web site, and read other visitors' comments. A guestbook application consists of two pieces:
Figure 5.2 contains a diagram of how you
might design a guestbook application.
You need only one CGI application: one that accepts the input and adds the new entry to the guestbook. The following lists the specifications for a simple guestbook:
You can use the PATH_TRANSLATED environment variable to specify alternative locations of the guestbook file. You can use the same file-locking routines you used in counter.cgi. In order to filter out HTML tags, you can replace the less-than (<) and greater-than (>) symbols with the appropriate escaped HTML (< and >, respectively).
This guestbook example will be developed in C. The Perl equivalent looks almost exactly the same, and with the specifications listed earlier, Perl doesn't offer many advantages over C (other than being a simpler language). The routines in cgihtml will handle most of the routine input and output. You will notice that parts of counter.cgi are reused, and that much of guestbook.c looks very similar to parts of counter.cgi.
The following cgihtml routines will be included:
One new function is needed: a date and time-stamping function. You can use the standard C functions from <time.h>; the function is listed in Listing 5.13. It uses strftime() to format the string containing the current date and time.
Listing 5.13. Date_and_time().
char *date_and_time()
{
time_t tt;
struct tm *t;
char str = malloc(sizeof(char) * 80 + 1);
tt = time(NULL);
t = localtime(&tt);
strftime(str,80,"%A, %B %d, %Y, %I:%M %p",t);
return str;
}
Use another function called append() (see Listing 5.14), which will append the provided values onto the guestbook. The code isn't much different from the increment() function from counter.cgi, other than outputting different values and appending rather than writing.
Listing 5.14. append().
void append(char *fname, char *name, char *email, char *url, char *message)
{
FILE *guestfile;
wait_for_lock(LOCKFILE);
lock_file(LOCKFILE);
if (!file_exist(fname)) {
guestfile = fopen(fname,"w");
print_header(guestfile);
}
else {
if ((guestfile = fopen(fname,"a")) == NULL) {
unlock_file(LOCKFILE);
cgi_error();
}
}
fprintf(guestfile,"<p><b>From:</b> ");
if (strcmp(url,""))
fprintf(guestfile,"<a href=\"%s\">",url);
fprintf(guestfile,"%s\n",name);
if (strcmp(url,""))
fprintf(guestfile,"</a>\n");
if (strcmp(email,""))
fprintf(guestfile,"<a href=\"mailto:%s\"><%s></a>\n",email,email);
fprintf(guestfile,"<br>");
fprintf(guestfile,"<b>Posted on:</b> %s</p>\n",date_and_time());
fprintf(guestfile,"<pre>\n%s</pre>\n",message);
fprintf(guestfile,"<hr>\n");
unlock_file(LOCKFILE);
fclose(guestfile);
}
append() does not add any closing HTML </body> or </html> tags. Modifying append() so that it does would require searching the file for the end of the last entry, removing the current footer, adding the new entry, and appending the footer again. This process is more complicated than it's worth, so instead of abiding by good HTML rules, the example excludes the closing HTML tags.
The format for each new entry is also hard-coded by the append() function. Although this format might be suitable for most people, it might not be suitable for others. Both this and the HTML footer dilemma are covered when you revisit the guestbook program in Chapter 6, "Programming Strategies."
The complete source code to the guestbook program is in Listing 5.15.
Listing 5.15. Guestbook.c.
/* guestbook.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <time.h>
#include "cgi-lib.h"
#include "html-lib.h"
#include "string-lib.h"
#define DEFAULT_GUESTBOOK "/home/eekim/Web/html/guestbook.html"
#define LOCKFILE "/home/eekim/Web/guestbook.LOCK"
short file_exist(char *filename)
{
FILE *stuff;
if ((stuff = fopen(filename,"r")) == 0)
return 0;
else {
fclose(stuff);
return 1;
}
}
void lock_file(char *filename)
{
FILE *lock;
lock = fopen(filename,"w");
/* write process ID here; UNIX only */
fprintf(lock,"%d\n",getpid());
fclose(lock);
}
void unlock_file(char *filename)
{
unlink(filename);
}
void wait_for_lock(char *filename)
{
FILE *lock;
while (file_exist(filename)) {
fclose(lock);
sleep(2);
}
}
char *date_and_time()
{
time_t tt;
struct tm *t;
char str = malloc(sizeof(char) * 80 + 1);
tt = time(NULL);
t = localtime(&tt);
strftime(str,80,"%A, %B %d, %Y, %I:%M %p",t);
return str;
}
void print_header(FILE *guestfile)
{
fprintf(guestfile,"<html> <head>\n");
fprintf(guestfile,"<title>Guestbook</title>\n");
fprintf(guestfile,"</head>\n");
fprintf(guestfile,"<body>\n");
fprintf(guestfile,"<h1>Guestbook</h1>\n");
fprintf(guestfile,"<hr>\n");
}
void cgi_error()
{
html_header();
html_begin("Error: Can't write to guestbook");
h1("Error: Can't write to guestbook");
printf("<hr>\n");
printf("There has been an error. Please report this to\n");
printf("our web administrator. Thanks!\n");
html_end();
exit(1);
}
void append(char *fname, char *name, char *email, char *url, char *message)
{
FILE *guestfile;
wait_for_lock(LOCKFILE);
lock_file(LOCKFILE);
if (!file_exist(fname)) {
guestfile = fopen(fname,"w");
print_header(guestfile);
}
else {
if ((guestfile = fopen(fname,"a")) == NULL) {
unlock_file(LOCKFILE
cgi_error();
);
}
}
fprintf(guestfile,"<p><b>From:</b> ");
if (strcmp(url,""))
fprintf(guestfile,"<a href=\"%s\">",url);
fprintf(guestfile,"%s\n",name);
if (strcmp(url,""))
fprintf(guestfile,"</a>\n");
if (strcmp(email,""))
fprintf(guestfile,"<a href=\"mailto:%s\"><%s></a>\n",email,email);
fprintf(guestfile,"<br>");
fprintf(guestfile,"<b>Posted on:</b> %s</p>\n",date_and_time());
fprintf(guestfile,"<pre>\n%s</pre>\n",message);
fprintf(guestfile,"<hr>\n");
unlock_file(LOCKFILE);
fclose(guestfile);
}
void print_form()
{
html_header();
html_begin("Add Entry to Guestbook");
h1("Add Entry to Guestbook");
printf("<hr>\n");
printf("<form method=POST>\n");
printf("<p>Enter your name:\n");
printf("<input type=text name=\"name\" size=25><br>\n");
printf("<p>Enter your e-mail address:\n");
printf("<input type=text name=\"email\" size=35><br>\n");
printf("<p>Enter your WWW home page:\n");
printf("<input type=text name=\"url\" size=35></p>\n");
printf("<p>Enter your comments:<br>\n");
printf("<textarea name=\"message\" rows=5 cols=60>\n");
printf("</textarea></p>\n");
printf("<input type=submit value=\"Submit comments\">\n");
printf("<input type=reset value=\"Clear form\">\n");
printf("</form>\n<hr>\n");
html_end();
}
void print_thanks()
{
html_header();
html_begin("Thanks!");
h1("Thanks!");
printf("<p>We've added your comments. Thanks!</p>\n");
html_end();
}
int main()
{
llist entries;
char *where;
if (read_cgi_input(&entries)) {
/* read appropriate variables */
if (PATH_TRANSLATED)
where = newstr(PATH_TRANSLATED);
else
where = newstr(DEFAULT_GUESTBOOK);
append(where,
replace_ltgt(cgi_val(entries,"name")),
replace_ltgt(cgi_val(entries,"email")),
replace_ltgt(cgi_val(entries,"url")),
replace_ltgt(cgi_val(entries,"message")) );
print_thanks();
}
else
print_form();
list_clear(&entries);
}
To use the guestbook, modify DEFAULT_GUESTBOOK to whatever suits your system, compile, and install the program in the correct directory. You can either create your own HTML document for adding entries or use the default one in the guestbook program. If you use the default, then just call the program to add an entry.
http://myserver.org/cgi-bin/guestbook
If the URL for your guestbook is
http://myserver.org/~joe/guestbook.html
call the following:
http://myserver.org/cgi-bin/guestbook/~joe/guestbook.html
If you make your own form, it should contain the elements name, email, url, and message.
If you want to create your own header and general style for the HTML guestbook, create the HTML file; otherwise, guestbook will use its own default, simple header.
CGI input consists of receiving general information about the server and client and parsing the input submitted via an HTML form. Form input is encoded before being sent to the CGI program; the CGI application must parse the data.
This chapter contains a great deal of code, mostly to demonstrate at a very low level how to process form input. You, however, will almost never have to implement these parsing routines yourself; several libraries exist for a variety of programming languages that will do the parsing for you. Using these libraries (such as cgi-lib.pl for Perl and cgihtml for C), you can write a robust, fairly powerful CGI application in relatively few lines.