{kind=link}
{kind=link}
{kind=link}
{kind=link}




When you begin writing serious CGI applications, you will hopefully find that the majority of your coding time is spent designing the program and dealing with the small details. You should be using a CGI programming library-either written by someone else or by yourself-that takes care of the repetitive parsing details for you.
Nevertheless, there are certain strategies you can use to simplify your programming duties and to increase the power and efficiency of your applications. Additionally, there are several common techniques for performing common tasks people want to perform using CGI applications. You have hopefully seen and learned some of these strategies and techniques from the many examples in this book.
This chapter presents some of these strategies and techniques. It begins with a discussion of some basic programming paradigms, and tries to provide a good context and approach to programming CGI applications. It then goes on to list some strategies that apply specifically to CGI programming: when to use CGI programs and how to design a powerful and useful application. To demonstrate these strategies, I extend the guestbook CGI application from Chapter 5, "Input." Finally, you learn some practical programming tips and techniques.
Good programming is not simply understanding the syntax of a computer language; it's understanding the problem and providing a clear and effective solution. When you are learning a new tool such as CGI, you can easily forget the bottom line: you are developing an application that solves a problem. The principles of good programming apply to good CGI programming as well.
Bjarne Stroustrup, the creator of C++, identified three stages of good programming:
| Tip |
I cannot overemphasize the importance of careful planning before you work on an application. Fight the tendency to start programming immediately; first analyze the problem and work on designing a solution. In the long run, time spent designing the program will save you time later from debugging and possibly rewriting your software. |
Programming CGI applications presents some different challenges you might not have experienced from your other programming experience. CGI programming places a greater emphasis on robustness, simplicity, and efficiency. Not only does the quality and power of your code depend on it, so does the security and speed. CGI applications are network, multiuser applications, not single-user programs running on a single machine.
| Tip |
There is a principle in computer programming called KISS: "Keep It Simple, Stupid." |
Keeping everything simple is extremely important in CGI programming. One CGI pitfall you will see in Chapter 9, "CGI Security," and other chapters is that certain commands that are completely innocent as a single-user program are serious security risks as a multiuser, network program. Additionally, CGI programs are often on Web sites that are getting thousands of hits a day. If your CGI programs are unnecessarily big or take up too much memory, you could see a performance drop on your server. It is more important for your programs to do only what you want them to do, nothing more.
Another thing you need to worry about when programming a network application is file locking. On a single-user application, you don't need to worry about two programs writing to the same file simultaneously because only one program is running at the same time. However, on a multiuser system, there is a good possibility that more than one person tries to write to a file at the same time. If this happens, you could lose data. Approaching the problem as a multiuser, networking problem will help you see important issues such as these.
Finally, programming Internet applications such as CGI programs is challenging because the standards are constantly evolving. Sometimes, these standards don't seem to make a lot of sense, and you can get away with doing less. Why should you bother worrying about the standards when less will work?
Here are two examples. First, HTML files consist of tags such as <html>, <head>, and <body>. Although the HTML specification requires the presence of these tags, most browsers will interpret HTML just fine without them. Why should you spend the extra effort and disk space typing in these "extra" tags?
First, there is no guarantee that all browsers that follow the proper HTML specification will properly interpret your files if you don't include them. This might or might not be an important factor for you because the browser your users use will display them correctly.
Second, you cannot take advantage of some of the features that using these tags provide. There's usually a reason for everything, whether you are aware of it or not. As you learned in Chapter 3, "HTML and Forms," you can use several tags that must be enclosed within the <head> tags to perform special tasks. If, one day, you decide you want to use <meta http-equiv> tags or <isindex> tags, and none of your HTML documents have <head> tags, you need to exert a greater effort to fix your Web pages in order to take advantage of some of these special features. Had you followed the standards and used these tags in the first place, you could easily adapt your pages whenever you wanted to use new features.
The next example is the requirement to end HTTP and CGI headers with a CRLF rather than simply an LF. Why use the following:
printf("Content-Type: text/html\r\n\r\n");
when the following works just as well:
printf("Content-Type: text/html\n\n");
I will argue both ways in this case. On the one hand, while using only LF might work for your specific server, there is no guarantee that all servers will parse these headers correctly. Why not include the extra two characters to improve the portability of your software? On the other hand, I have seen a problem with Perl scripts on DOS and Windows machines. On these platforms, the Perl code
print "Content-Type: text/plain\r\n";
print "Pragma: no-cache\r\n\r\n";
print "hello!\n";
produces
Content-Type: text/plainLF
LF
Pragma: no-cacheLF
LF
LF
LF
hello!LF
instead of the correct
Content-Type: text/plainCRLF
Pragma: no-cacheCRLF
CRLF
hello!LF
Windows and DOS platforms have two modes: text and binary. By default, Perl on these platforms is in text mode that interprets the carriage return (\r) and line feed (\n) both as line feeds. In order to fix the code, you would use the following:
binmode(STDOUT);
print "Content-Type: text/plain\r\n";
print "Pragma: no-cache\r\n\r\n";
print "hello!\n";
Although the extra binmode helps guarantee portability in this case, it is also extraneous code that is useless for Perl on a UNIX platform. All factors being equal, I decided that for the sake of this book, I would use LF to end my Perl headers, especially because every server platform I know supports this.
In general, you should try and follow the standards if at all possible. There are usually good justifications for these standards, even though you might not be aware of them. However, you might sometimes find yourself in the situation in which choosing what works is much easier than strictly following the standard. There is nothing inherently wrong with this approach, and it might make life a lot easier for you, which is ultimately the goal of computer software.
The first step you should always take in CGI programming is to identify the problem. You might find that many of the tasks you hope to solve using a CGI program have a better alternative solution. For example, suppose you want your home page to have a different image every hour. Using CGI, you could write a program that determined the time and outputted the appropriate image. Call this program time-image.cgi. Then, your HTML home page would have the following tag:
<img src="/cgi-bin/time-image.cgi">
Every time someone accesses this page, the server runs time-image.cgi. Each time, the CGI program computes the current time, loads the appropriate image, and sends that to stdout. The server parses the CGI headers and redirects the output back to the Web browser. If your Web page is accessed 10,000 times a day, time-image.cgi goes through the same steps 10,000 times.
Is there a better solution to your problem? In this case, there is. If you have 24 different images, one for each hour of the day, and you want a different image every hour, your HTML file could have the following tag:
<img src="/images/current_image.gif">
Write a program that runs every hour and that copies the appropriate picture to current_image.gif. Instead of having a single process running 10,000 times a day, you achieve the same effect running one program 24 times in one day.
As another example, suppose you want to make your current Web server statistics available to anyone over the Web. Once again, you could write a CGI program that, when called, would process your server's logs and send the results back to the browser. However, processing server logs can require huge computing resources, especially if your logs are very large. Instead of recomputing the statistics every time someone wants to see them, you are better off computing the statistics periodically, perhaps once a day, and making the results available in an HTML file.
There are often many ways to approach a specific problem, and there is no need to limit yourself to one approach. Before committing to writing a CGI program, ask yourself if there is another, better way of solving the problem.
Assuming you have determined that a CGI application is best suited for solving your problem, you should consider the following strategies. First, take advantage of some of the many existing programming libraries that handle most of the repetitive work such as parsing CGI input. You learn about two very good libraries in this book: cgihtml for C programmers and cgi-lib.pl for Perl. There are other excellent libraries, for Perl and C as well as many other languages. If you dislike using other people's code for whatever reason, then you should consider writing your own library for tackling these problems and reusing that. If you find yourself rewriting code for decoding URL-encoded strings every time you write a CGI application, you are wasting your time.
Write programs that are general. You might have several very similar programming tasks you need to solve. Instead of writing a separate program for each task, see if you can abstract each problem and find common elements between some of these tasks. If there are common elements, you can probably solve several programming tasks with one, general program. For example, many people commonly use CGI to decode form input and save the results to a file. Writing a program for each separate form seems rather foolish if you are doing the same thing for each form. You should instead write one general form-processing program that parses the form and saves it to a user-specified file in a user-specified format.
Writing general applications is especially advantageous for the Internet service provider. If you are a service provider, you might be reluctant to allow your users to run CGI programs for security reasons. Most users want the ability to parse forms and save or mail the information, a guestbook, and possibly a counter. If you provide general applications that all of your users can use, you might be able to avoid letting anyone else have CGI access.
Don't make any false assumptions about your problem. A common mistake in C is to assign statically allocated buffers. For example, suppose you had a form that asked for your age:
<form action="/cgi-bin/age.cgi" method=GET>
Age? <input name="age" size=3 maxsize=3>
</form>
If age.cgi is in C, you might assume that because no one has greater than a three-digit age and because your form doesn't enable anyone to input an age greater than three digits, you can define age in your program as
char age[3];
However, this is not a safe assumption and the consequences can be severe. The preceding form uses the GET method. There is no way to prevent a user from bypassing your form by using the URL:
http://myserver.org/cgi-bin/age.cgi?age=9999
Changing to the POST method doesn't solve the problem. I could still create their own form pointing to http://myserver.org/cgi-bin/age.cgi that did not have a maxsize limit on age. I could even directly connect to your Web server and enter the data using HTTP commands.
% telnet myserver.org 80
Trying 127.0.0.1...
Connected to myserver.org.
Escape character is '^]'.
POST /cgi-bin/age.cgi
Content-Length: 8
age=9999
The consequences of your false assumption is not just your program crashing. Because it is a network application, malicious users can potentially exploit this weakness in your program to gain unauthorized access to your system. (For more information on this and how to prevent it, see Chapter 9.) You were probably not aware of this fact if you are not already an experienced network programmer or security expert. Other potential loopholes like this exist as well, of which you are very likely not aware.
Rather than subject yourself to such risks or even the most basic risk of all-your program not working-you are better off not making these kinds of assumptions, even if it means you have a more difficult programming task. Spending a little extra time making sure your software can handle any contingency will improve the robustness of your software and help prevent any unwanted surprises.
Finally, CGI is closely tied to HTML and HTTP. The better you understand both protocols, the more powerful applications you can write. For example, suppose you want to write a CGI program called form.cgi that would display a form if it received no input or would otherwise parse the form. If you know that form.cgi resides in /cgi-bin, you would probably print the HTML.
printf("<form action=\"/cgi-bin/form.cgi\" method=POST>\n");
Suppose you decide to change the name from form.cgi to bigform.cgi. Or suppose you moved it into a different CGI directory. If you didn't know any better, you would have to change your code every time your program name changed or the location of your CGI program changed. Here, knowledge of HTML would have saved you some trouble. If you don't define an action parameter in the <form> tag, it defines the current URL as the action parameter. Therefore, if you instead used the following line you would not have to worry about changing the code every time you changed the location or name of the program:
printf("<form method=POST>\n");
I am constantly discovering uses for HTML or HTTP features of which I was previously unaware-from avoiding caching to using multiple form submit buttons. Knowledge of the HTTP and HTML protocols will give you many more tools for programming more powerful CGI applications.
How could you improve the guestbook application from Chapter 5
using the principles
described in this chapter? That guestbook, written in C, took
user input from a form and appended it to the end of an HTML file.
If guestbook was called without any input, it would provide a
basic form for adding entries. If it tried to write to a non-existent
guestbook file, it would create a new one using a basic header
file.
Although this guestbook is more than satisfactory for most applications, there are several ways you can improve it. First, the format of the guestbook HTML file is hard coded in the guestbook program. This is adequate for one person or group's Web site, but if you are an access provider who wants to provide a general guestbook application to several different accounts, you want to allow the user to specify the format of the guestbook HTML file.
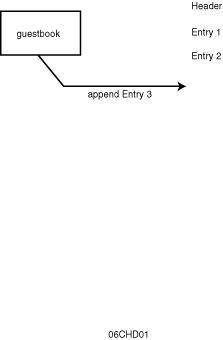
Because the guestbook appends directly to the guestbook HTML file,
appending the proper HTML footer to the end of the HTML document
is more challenging. The current program assumes a guestbook HTML
file that consists of a header and possibly some other entries,
as shown in Figure 6.1. Adding new data
means simply appending to that HTML file. However, the HTML footer
is noticeably missing. Although almost every browser will still
interpret the HTML file properly, having your CGI program output
improper HTML is unsatisfactory.
Figure 6.1 : The old guestbook model.
One possible solution is to parse the current HTML guestbook and
separate it into its three elements: the header, the entries,
and the footer (as shown in Figure 6.2).
Then, you could rewrite the header and the entries, append the
new entry, and append the footer. This is a complex programming
task, especially in C, and is less efficient than just appending
to a file. This solution seems to be more complex than necessary,
and it seems wiser to use what works in this case rather than
what is technically correct.
Figure 6.2 : Aproposed model for improving the old guestbook.
Another possible solution is to have three different files: a header file, an entries file, and a footer file. Guestbook would append the new, formatted entry to the entries file, and then create a fourth file-the guestbook HTML file-by combining the three files. Although this is an adequate solution and not as difficult to program, it also seems unnecessarily more complex without adding much new functionality other than outputting proper HTML.
You can solve both of these problems and add several new features
by storing the guestbook entries in a database rather than directly
appending them to an HTML file. The database stores all of the
entries in an intermediary format from which you can easily generate
HTML files (as shown in Figure 6.3). This
has several advantages. First, users can choose whatever format
they want for the HTML-style guestbook. You no longer need to
worry about adding a footer, because the guestbook generates all
of the information from scratch. There is no need to parse an
already existing file for header, entries, and footer information
because all of that information is stored separately anyway. You
can organize your guestbook files any way you please. For example,
your HTML generator could create one guestbook file per month
or just one large guestbook file. Your previous guestbook did
not have this flexibility. If you decide you want to change the
look of your guestbook, all you have to do is modify your program
and reload the page in your browser.
Figure 6.3 : Model for the new guestbook.
Storing the entries in a database requires one extra step, however: generating HTML files from the database. Separating this task from the CGI program is preferable in this case. In addition to the benefits listed previously, you also have the ability to moderate a guestbook and remove offending entries if you so desire before making the guestbook publicly available for the rest of the world to see. You could run the intermediary program periodically to automatically generate the HTML files. Additionally, while you would provide an intermediary program to process the database for your beginner users, advanced users have the option of writing their own systems for parsing the database.
The following lists the specifications for the new guestbook application:
For this application, I develop an HTML generator-guestbook2html-that converts the database to an HTML style of your choice, specified by a template file. Because guestbook2html is primarily a text parser, I write it in Perl. Modifying the C code of the original guestbook to the preceding specifications is not a difficult task, so I keep the CGI program written in C.
How should you format your database? Because you are limiting yourself to converting the information stored in the database to another format rather than performing a complex query, a flat-file database is an easy and excellent choice. I delimit each field using ampersands (&), so I must also make sure that any ampersands in the input are encoded. The function encode_string() in Listing 6.1 URL encodes ampersands, percents (%), and newlines (\n). Because I encode newlines, I can represent each entry on one line in the file. A sample guestbook database is shown in Listing 6.2.
| Note |
For more information on programming CGI using databases, see Chapter 12, "Databases." |
Listing 6.1. encode_string().
char *encode_string(char *str) /* encode &, %, and \n */
{
int i,j;
char *tempstr = malloc(sizeof(char) * (strlen(str) * 3) + 1);
char encoded_char[3];
j = 0;
for(i = 0; i < strlen(str); i++) {
switch (str[i]) {
case '%': case '&': case '\n':
sprintf(encoded_char,"%%%02x",str[i]);
tempstr[j] = encoded_char[0];
tempstr[j+1] = encoded_char[1];
tempstr[j+2] = encoded_char[2];
j += 3;
break;
default:
tempstr[j] = str[i];
j++;
break;
}
}
tempstr[j] = '\0';
return tempstr;
}
Listing 6.2. Sample guestbook database.
828184052&Eugene Kim&eekim@hcs.harvard.edu&http://hcs.harvard.edu/~eekim/
Â&I like your new guestbook!%0aIt works much better than the old one.
828184118&Jessica Kim&&&%26lt;Hi big brother!%26gt;
828522375&Sujean Kim&sujekim@othello.ucs.indiana.edu&&Howdy little bro.
ÂEveryone else in the family was%0adropping by, so I thought I would too.
Other than the new encoding function, you only need to make a few more minor changes to guestbook.c. First, you need to modify the append() function so that it appends to the database rather than to an HTML file. You might notice that in the specifications I said the location of the database could be specified in the PATH_INFO environment variable of the CGI program, whereas in the old guestbook program, it is in the PATH_TRANSLATED variable. The PATH_TRANSLATED variable limits the location of the database to somewhere within the Web document directory tree. This is potentially undesirable because you might not want anyone with a Web browser to access the raw database, especially if you plan to moderate it. I use the PATH_INFO variable instead and force the user to include a full path for the database location so the user is not limited to storing the database within the Web document directory tree.
The last minor modification is to the datestamp function, date_and_time(). Rather than return a formatted time string, it is easier to return the raw time and store it as a long integer. The HTML generating program can parse this integer itself and format the datestamp in whatever format the user wishes.
The complete code for the new and improved guestbook is in Listing 6.3. If you compare this with the guestbook in Chapter 5, you will notice that the new guestbook is about the same size and not terribly more complex, yet it is quite a bit more powerful and functional.
Listing 6.3. guestbook.c.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <time.h>
#include "cgi-lib.h"
#include "html-lib.h"
#include "string-lib.h"
#define DEFAULT_GUESTBOOK "/home/eekim/Web/guestbook"
short file_exist(char *filename)
{
FILE *stuff;
if ((stuff = fopen(filename,"r")) == 0)
return 0;
else {
fclose(stuff);
return 1;
}
}
void lock_file(char *filename)
{
FILE *lock;
lock = fopen(filename,"w");
/* write process ID here; UNIX only */
fprintf(lock,"%d\n",getpid());
fclose(lock);
}
void unlock_file(char *filename)
{
unlink(filename);
}
void wait_for_lock(char *filename)
{
FILE *lock;
while (file_exist(filename)) {
fclose(lock);
sleep(2);
}
}
char *encode_string(char *str) /* encode &, %, and \n */
{
int i,j;
char *tempstr = malloc(sizeof(char) * (strlen(str) * 3) + 1);
char encoded_char[3];
j = 0;
for(i = 0; i < strlen(str); i++) {
switch (str[i]) {
case '%': case '&': case '\n':
sprintf(encoded_char,"%%%02x",str[i]);
tempstr[j] = encoded_char[0];
tempstr[j+1] = encoded_char[1];
tempstr[j+2] = encoded_char[2];
j += 3;
break;
default:
tempstr[j] = str[i];
j++;
break;
}
}
tempstr[j] = '\0';
return tempstr;
}
time_t date_and_time()
{
return time(NULL);
}
void cgi_error()
{
html_header();
html_begin("Error: Can't write to guestbook");
h1("Error: Can't write to guestbook");
printf("<hr>\n");
printf("There has been an error. Please report this to\n");
printf("our web administrator. Thanks!\n");
html_end();
exit(1);
}
void append(char *fname, char *name, char *email, char *url, char *message)
{
FILE *guestfile;
char *LOCKFILE;
LOCKFILE = malloc(sizeof(char) * (strlen(fname) + 5) + 1);
strcpy(LOCKFILE,fname);
strcat(LOCKFILE,".LOCK");
wait_for_lock(LOCKFILE);
lock_file(LOCKFILE);
if ((guestfile = fopen(fname,"a")) == NULL) {
unlock_file(LOCKFILE);
cgi_error();
}
fprintf(guestfile,"%d&%s&%s&%s&%s\n",date_and_time(),name,email,url,message);
fclose(guestfile);
unlock_file(LOCKFILE);
}
void print_form()
{
html_header();
html_begin("Add Entry to Guestbook");
h1("Add Entry to Guestbook");
printf("<hr>\n");
printf("<form method=POST>\n");
printf("<p>Enter your name:\n");
printf("<input type=text name=\"name\" size=25><br>\n");
printf("<p>Enter your e-mail address:\n");
printf("<input type=text name=\"email\" size=35><br>\n");
printf("<p>Enter your WWW home page:\n");
printf("<input type=text name=\"url\" size=35></p>\n");
printf("<p>Enter your comments:<br>\n");
printf("<textarea name=\"message\" rows=5 cols=60>\n");
printf("</textarea></p>\n");
printf("<input type=submit value=\"Submit comments\">\n");
printf("<input type=reset value=\"Clear form\">\n");
printf("</form>\n<hr>\n");
html_end();
}
void print_thanks()
{
html_header();
html_begin("Thanks!");
h1("Thanks!");
printf("<p>We've added your comments. Thanks!</p>\n");
html_end();
}
int main()
{
llist entries;
char *where;
if (read_cgi_input(&entries)) {
/* read appropriate variables */
if (PATH_INFO)
where = newstr(PATH_INFO);
else
where = newstr(DEFAULT_GUESTBOOK);
append(where,
encode_string(replace_ltgt(cgi_val(entries,"name"))),
encode_string(replace_ltgt(cgi_val(entries,"email"))),
encode_string(replace_ltgt(cgi_val(entries,"url"))),
encode_string(replace_ltgt(cgi_val(entries,"message"))) );
print_thanks();
}
else
print_form();
list_clear(&entries);
}
guestbook2html must parse the database, decode the fields, and
generate HTML files based on a template file. The guestbook2html
presented here-shown in Listing 6.4-is a fairly simple HTML generator
provided mainly to demonstrate how to write such a program. From
the command line, you specify five files: the database file, a
template file, a header file, a footer file, and the name of the
HTML file. The template file is pure HTML code with a few special
embedded markers that will be replaced by the actual entry fields.
The markers are represented by a dollar sign ($)
followed by the field name. Valid markers are defined in Table
6.1.
| Marker | Corresponding Field |
| $name | Name |
| E-mail address | |
| $url | Home page URL |
| $mesg | Comments |
| $date | Date of entry |
| $time | Time of entry |
If you want to include a dollar sign in the template file, you
would precede it with a backslash (/$).
Similarly, you would represent a single backslash as two backslashes
(//). The complete Perl code
for guestbook2html is in Listing 6.4. Using the template file
in Listing 6.5, guestbook2html produces a page similar to Figure 6.4.
Figure 6.4 : Rendered output of guestbook2html.
Listing 6.4. guestbook2html (Perl).
#!/usr/local/bin/perl
($database,$template,$header,$footer,$html) = @ARGV;
# read template into list
open(TMPL,$template) || die "$!\n";
@TEMPLATE = <TMPL>;
close(TMPL);
# open HTML file
open(HTML,">$html") || die "$!\n";
# print header
open(HEAD,$header) || die "$!\n";
while (<HEAD>) {
print HTML;
}
close(HEAD);
# open database and parse
open(DBASE,$database) || die "$!\n";
while ($record = <DBASE>) {
$record =~ s/[\r\n]//g;
($datetime,$name,$email,$url,$mesg) = split(/\&/,$record);
undef %dbase;
$dbase{'name'} = &decode($name);
$dbase{'email'} = &decode($email);
$dbase{'url'} = &decode($url);
$dbase{'mesg'} = &decode($mesg);
$dbase{'date'} = ('Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep',
'Oct','Nov','Dec')[(localtime($datetime))[4]]." ".
(localtime($datetime))[3].", 19".
(localtime($datetime))[5];
$hour = (localtime($datetime))[2];
if (length($hour) == 1) {
$dbase{'time'} = "0";
}
$dbase{'time'} .= $hour.":";
$minute = (localtime($datetime))[1];
if (length($minute) == 1) {
$dbase{'time'} .= "0";
}
$dbase{'time'} .= $minute;
# write to output file according to template
foreach $line (@TEMPLATE) {
$templine = $line;
if ($templine =~ /\$/) {
# form variables
$templine =~ s/^\$(\w+)/$dbase{$1}/;
$templine =~ s/([^\\])\$(\w+)/$1$dbase{$2}/g;
}
print HTML $templine;
}
}
close(DBASE);
# print footer
open(FOOT,$footer) || die "$!\n";
while (<FOOT>) {
print HTML;
}
close(FOOT);
# close HTML file
close(HTML);
sub decode {
local($data) = @_;
$data =~ s/%([0-9a-fA-F]{2})/pack("c",hex($1))/ge;
return $data;
}
Listing 6.5. Sample template file for guestbook2html.
<p>From: <b>$name</b>,
<a href="mailto:$email">
$email</a><br>
Posted on: $date, $time</p>
<p>$mesg</p>
<hr>
Although this new guestbook program is more flexible and functional than the old version, there is still room for improvement. For example, the current guestbook assumes four specific fields. You could modify guestbook to accept any field specified in the HTML form. The confirmation message is still hard coded in this version. You could have the guestbook read a configuration file that specified locations for a customized add and confirmation form. Finally, there are many ways to improve guestbook2html, ranging from allowing several different date formats to generating guestbook files for each month.
There is always room for improvement. Nevertheless, this guestbook is an excellent example of designing and implementing good CGI applications. I decided what the requirements were, what features I wanted, and how to best implement these features before actually writing the program. As demonstrated with guestbook2html, it is not always necessary to include all of the desired functionality within the CGI program. If you follow these basic guidelines and carefully plan your project, you are sure to write excellent CGI applications.
This chapter closes with a discussion of some practical challenges you might experience when programming CGI. Many of the techniques described here have already been demonstrated in previous chapters; many more of them are used in Part III, "Real-World Applications." This section begins with some general issues and then describes several very specific problems and solutions.
A common concern for information providers and CGI programmers is the performance of the application. How fast and efficient can you make an application, and what other steps can you take to improve your performance? First, realize that the speed and efficiency of your CGI program is very likely not the limiting factor in the overall performance when someone attempts to access your site. The most important factors on any Web site are network bandwidth, RAM, and the speed of your hard disk. A slow network connection or hard disk can easily counteract any performance gain you obtain by using some of the CGI tricks you are about to learn. Additionally, the entire process of running a CGI program tends to be a slow and inefficient one. Just waiting for the server to receive the connection, set up the environment variables and the appropriate file handles, and run the CGI program often contributes to the greatest percentage of waiting time.
Before you spend a lot of time implementing all sorts of optimizations, you should consider whether the performance gain is worth the time spent. One of the misconceptions when choosing a language for programming CGI is that a low-level, compiled language such as C will give you much better performance than Perl. Because of the many other factors, this is not always the case. Sometimes, the performance gain is not worth the extra hours programming an application in C, when you could have saved several hours programming the application in Perl with equivalent performance.
In general, compiled C programs are smaller and more resource-efficient, and there will be times when the difference is noticeable. On my 486DX33 running Linux (on which I do much of my Web development), the compiled counter program in C from Chapter 5 is about 5KB. The Perl binary on my system is about 450KB, 90 times larger. Because I have a slow hard drive and low memory, I notice the difference in performance between a C and equivalent Perl CGI application. However, on faster machines with a decent SCSI hard drive, I rarely notice any performance difference between a C and Perl application, even though the Perl application is still noticeably larger. Unless your needs are fairly unique, I don't recommend choosing C as your primary programming language over Perl simply because your C programs are smaller. There are usually much better reasons for choosing one language over another, the best being personal preference.
There are other small things you can do to improve the performance of your applications. Every time you access your hard disk, whether you are reading from and writing to files or are running another program, your application will slow down. Normally, the server parses the output of your CGI program, which takes up some extra time. You can avoid this step by instead using an nph CGI program, which talks directly to the browser. Once again, you must consider all performance factors before deciding whether to implement any of these suggested optimizations. The extra flexibility of, for example, opening and parsing a configuration file, is almost always definitely worth a minute loss of speed, a loss that in all likelihood is not noticeable.
One of the difficulties of dealing with multiuser programs on a system such as UNIX is handling various file permissions and ownership issues. By default, most UNIX servers are configured to run CGI programs as the nonexistent user nobody, a user that usually doesn't have permission to write anywhere on the file system except perhaps in the /tmp directory. Often, CGI programs that read or write files mysteriously don't work even though there is nothing wrong with the code because the permissions or ownerships of files and directories are not correctly set.
Tackle this problem from two directions. First, make sure your program dies gracefully if it is unable to read or write from a file. Here's how it looks using cgi-lib.pl in Perl:
require 'cgi-lib.pl';
open(FILE,"/path/to/file") || &CgiDie("Error","Can't open file.");
Here's the same example using cgihtml in C:
#include <stdio.h>
#include "html-lib.h"
FILE *file;
if ((file = fopen("/path/to/file","r"))==0) {
fprintf(stderr,"CGI Error: Can't open file.\n");
html_header();
html_begin("Error");
h1("Error");
printf("<p>Can't open file.</p>\n");
html_end();
exit(1);
}
Now, if your CGI program fails to read or write to a file, you can immediately diagnose it. The second thing you should do is to devise a good system of permissions, ownership, and directories. Normally, because the CGI program runs as nobody and because no directories are owned by nobody, files need to be world-readable and directories world-writeable. Although for most people, making a configuration or other type of file world-readable isn't a problem, many are reluctant to create a world-writeable directory, and for good reason. You could change the ownership of a directory to nobody, but this is usually beyond the privileges of the average user because only root can change the ownership of a directory to another person.
One way to handle this problem is to create a group specifically for Web programs called httpd or something similar. Users who write CGI programs should be a member of this group, and you should run the Web server as group httpd. Now, your CGI programs can read from and write to any directories that are group-readable or -writeable, a more satisfactory solution for most.
If changing the permissions of your directory or files is not a feasible option, you can make your program setuid. I recommend you avoid this option unless you have no other choice. There are many inherent dangers associated with running a program as another person, especially as root. The server and CGI programs normally run as nobody so that they cannot accidentally destroy or access other users' files. A bug in a program running as another user can mean potentially destructive consequences for that user's files. Unless you are absolutely sure of what you are doing and have weighed your other options carefully, I don't recommend making your programs setuid (allowing other users to run as the owner of the program).
Regardless of how you tackle the problem of directory and file permissions, you still need to consider the permissions of the files you have created. For example, suppose your CGI program runs as user nobody and group httpd and writes a file to a directory that is group httpd and group writeable. That file will be owned by user nobody and group httpd and in all likelihood, will only be user readable and writeable:
drwxrwx--- jessica httpd data/
-rw------- nobody httpd data/file
If you are user jessica, you will not be able to read the file file. It does you little good that the CGI program can write to a file if you cannot read that file. To prevent problems like this, use the umask() function, which determines the permissions of the new file. In order to determine the umask value, subtract the value of the file permissions in octal notation (see sidebar) from 777. For example, if you want a file that is user- and group-readable and -writeable (660), the umask value would be
777 - 660 = 117
The umask function in C is
#include <sys/stat.h>
umask(117);
while in Perl it is simply
umask(117);
By carefully planning and properly configuring your permissions and ownerships, you can prevent frustration stemming from malfunctioning CGI programs.
In UNIX, every file belongs to an owner and a group. More than one user can belong to a group. Additionally, every file has three sets of permissions: one for the file's owner, one for the file's group, and one that applies to everyone else other than the file's owner and group. You either have permission to read a file, write to a file, or execute (run) a file.
If you look at a file using the UNIX command
ls -l filename
you will see something like this:
-rwxrwxrwx owner group filename
The first item, -rwxrwxrwx, tells you the permissions of the file. The second and third items are the owner and group of the file. The first letter of the first item tells you whether it is a file or a directory. The next three characters denote the owner's permissions, the subsequent three denote the group's permissions, and the final three represent everyone else's permissions. For example, a world-readable, user-writeable file owned by jessica and group people would look like the following:
-rw-r--r-- jessica people filename
To change the ownership of a file, use the command
chown owner filename
Only root may change the ownership of a file. To change the group of a file, use the following:
chgrp group filename
You can change a file to another group only if you are a member of that group.
Finally, to change the permissions of a file, you use the command
chmod permissions filename
The permissions can either be a comma-delimited list of values or an octal value. User permissions are represented by the letter u, group by the letter g, and other by the letter o. All three sets of permissions are represented by the letter a. Read, write, and execute permissions are represented by the letters r, w, and x, respectively. To make a file world-readable, you could do either of the following:
chmod u+r,g+r,o+r filename
chmod a+r filename
To turn off the write permission for "other" of a file, use the following:
chmod o-r filename
Using plus (+) or minus (-) signs only add or remove a permission. For example, if you had the following file:
-rw-r----- filename
and you typed the following command:
chmod g+w filename
the permissions would be
-rw-rw---- filename
If you wanted to change the permissions of this file so that the group could only write to it, you would use
chmod g=w filename
which would result in
-rw--w---- filename
You can also represent the permission as a numerical value. Read is represented by a 4, write by a 2, and execute by a 1. Permissions for the user is represented by 100, the group by 10, and other by 1. To determine the permissions, you sum the permission values multiplied by the owner value. For example, a file that is user readable only is 400. A file that is user and group readable and writeable is 660 (400 + 200 + 40 + 20). A file that is world readable and executable and user writeable is 755 (400 + 200 + 100 + 40 + 10 + 4 + 1).
There are two other permissions types: setuid and the sticky bit. An executable file that is setuid runs as either its owner (setuid) or its group (setgid) when run. For example, a program owned by user jessica and setuid, when run, would run as jessica. If the program were owned by group people and is setgid executable, it would run as group people. To make a file setuid or setgid executable, use:
chmod u+s filename
chmod g+s filename
The equivalent numerical value for setuid is 4000 and the value for setgid is 2000.
The sticky bit has two roles: one for shared executable files and one for directories. The first is highly specialized and for my purposes, unimportant. When you set the sticky bit on a world-writeable directory, the directory becomes append-only. Anyone can write to that directory, but only the person who owns the file can delete files within that directory. To set the sticky bit, type the following:
chmod a+t directoryname
The numerical value for the sticky bit is 1000.
When you access a CGI program from a Web browser, and you press the Stop button, how do you make sure the CGI program stops? Normally, the CGI program sends the output to the server, which sends the output to the browser. When you press the browser's Stop button, the browser closes the connection to the server, and the server receives a write error because it no longer can send data through that connection. However, most servers do not send a signal to the CGI program stating that the connection is closed.
If the program doesn't have a bug, it will eventually quit normally. However, if there is a bug in the program-perhaps an infinite loop-or if the program is performing a time- and resource-consuming action, that process can exist for a very long time. It would be nice if the server sent some signal to the CGI program to die, but most servers do not.
You can handle this problem several ways. The easiest is to make your program an nph program. Because nph programs speak directly to the client, if the browser closes the connection and the CGI program tries to send output to the browser, it will receive a broken pipe signal-SIGPIPE. In Perl, you can trap this using the following:
$SIG{'PIPE'} = myexit;
sub myexit {
# cleanup and exit
exit 1;
}
The equivalent in C is
#include <unistd.h>
#include <signal.h>
void myexit()
{
/* cleanup and exit */
exit(1);
}
int main()
{
signal(SIGPIPE,myexit);
}
When your program receives this signal, it will run the routine myexit(), which will exit the program. This, however, works only if your program attempts to send data to the browser. If there is some bug in your program such as an infinite loop, then your program might never attempt to write to the browser, and it will never receive the pipe signal.
If you know your program should take only a few seconds to finish running, you can have your program ring an alarm after several seconds. If your program receives an alarm signal, in all likelihood your program is hanging, and you should send an error message and exit. In C and Perl, you set an alarm using the alarm() function.
#include <unistd.h>
#include <signal.h>
#include "html-lib.h"
void myexit()
{
html_header();
html_begin("Error");
h1("Error");
printf("<p>CGI Timed Out</p>\n");
html_end();
exit(1);
}
int main()
{
alarm(30); /* set off an alarm in 30 seconds */
signal(SIGALRM,myexit);
}
In Perl:
require 'cgi-lib.pl';
$SIG{'ALRM'} = CgiDie("Error","CGI Timed Out");
alarm(30);
I set the alarm to ring after 30 seconds. Because I know that these programs should take no longer than a few seconds to finish processing, I can be sure that if I receive a CGI Timed Out error from the browser that there is some bug in the program.
This still does not resolve the problem if you know that the CGI program is doing a time-consuming task and is going to take a long time to process. However, if this is the case, you probably don't want to keep the connection open as the program works. For example, you might implement a long and complex database search CGI program as follows:
These steps are straightforward, and the structure is equivalent to most CGI applications. However, if the second step-the database search-takes several hours, the browser needs to keep an open connection with the server for several hours while the program performs its search. This is not only inconvenient for the user, it hogs network resources for several hours and could limit the number of hits your server is capable of handling.
One way to approach this problem is to have the CGI program save the database request to a queue file and have the database program run periodically on the queue, e-mailing the results to the user when it is finished. As you learned earlier, sometimes it is better and easier not to use CGI or to use it in a limited fashion. However, if you're not worried about distributing the processor load on your UNIX machine, a better alternative might be the following:
You might try and implement such a program in Perl like this:
#!/usr/local/bin/perl
require 'cgi-lib.pl';
# read form fields
&ReadParse(*input);
# now fork
if (($child=fork)==0) {
# in child process
exec("/path/to/databasesearch");
exit(1);
}
# send response
print &PrintHeader,&HtmlTop("Forked");
print "<p>Job forked. You'll receive the results by e-mail.</p>\n";
print &HtmlBot;
However, when you try to run this program, the browser will still hang and wait for databasesearch to finish. To prevent your program from waiting for the forked process to finish, you need to close all open file descriptors-including stdin, stdout, and stderr-before running the new process. This is because the child process inherits all open file descriptors when it forks, and the parent program is unable to continue until it regains control of those file descriptors. The proper implementation is
#!/usr/local/bin/perl
require 'cgi-lib.pl';
# read form fields
&ReadParse(*input);
# now fork
if (($child=fork)==0) {
# close file descriptors
close(STDOUT);
close(STDIN);
close(STDERR);
# in child process
exec("/path/to/databasesearch");
exit(1);
}
# send response
print &PrintHeader,&HtmlTop("Forked");
print "<p>Job forked. You'll receive the results by e-mail.</p>\n";
print &HtmlBot;
Your program now forks databasesearch and sends the successful HTML response immediately.
Multiuser programs face another difficulty you probably have not faced with single-user programs. When two programs attempt to write to a file at the same time, you can damage the data. To prevent this, you need to "lock" the file. There are various system routines that enable you to lock a file, but these are usually platform-specific. A more portable scheme for locking files is to create a lock file-as simple as an empty text file-before writing to a file. If a lock file exists, no other programs should attempt to write to this file. This requires more careful programming because if you forget to check for a lock file before writing to a file, the existence of the lock file is essentially irrelevant. However, having to program with more care is probably a more desirable than undesirable effect, and you end up with a portable application that does not depend on system routines.
Good CGI programming encompasses the same skills as programming any good software. Spend time analyzing the problem and determining the best possible solution. Sometimes, you will discover that a better solution exists to a problem that does not require CGI. A minimalist approach is especially important for CGI programs that are essentially network programs.
Many people on the Internet have generously donated their work for free on the Internet. Take advantage of these vast resources, and learn from the programming styles and techniques of others. I have devoted over half of this book to examples while I managed to summarize the essentials of the CGI protocol in one appendix (Appendix A, "CGI Reference"). Study examples in this book and wherever you can find them. You will learn to recognize both good and bad programming styles; hopefully, you will retain only the good.