{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




You might have noticed that the CGI, HTML, and HTTP standard protocols are broad, flexible, and fairly powerful. Using a fairly small set of features under a limited client/server model, you can write some very sophisticated applications. However, there remain limitations and room for improvement.
Both HTML and HTTP are evolving standards, constantly changing to meet the demands of the growing number of Web users. Manipulating some of these new features requires using CGI applications in innovative ways. Although the CGI protocol itself does not seem to be changing, you can constantly find new ways to use CGI to take advantage of those features of the World Wide Web that are changing.
This chapter is called "Proprietary Extensions" mainly to acknowledge the role of commercial software companies in enhancing Web technologies. Companies such as Netscape Communications, Sun Microsystems, and Microsoft Corporation have proposed many of these new extensions and features and are largely responsible for the rapid development of new technologies. However, the title "Proprietary Extensions" is somewhat of a misnomer. Many of the extensions described in this chapter are being proposed as Internet standards. HTML is basically an evolving standard, and so many of these proposed extensions are widely used, that they should be considered standards even though they are not officially acknowledged as such.
| Note |
When and how does a protocol become a standard? A group called the Internet Engineering Task Force (IETF), a subgroup of a commercial organization called the Internet Society, has a well-defined system of proposal and approval of standard Internet protocols. This system often takes a long time and several drafts. In the meantime, rather than wait, many people will often implement protocols that have not yet been officially approved as standards. This is not necessarily an undesirable effect because it helps the standard evolve with the needs of the Internet community. However, it is a difficult trend for developers who want to write applications that will work with almost all other software and that will not become quickly outdated. The best way to keep track of the various protocols specific to the Web is to check the W3 Consortium's Web site, headed by Tim Berners-Lee, the inventor of the World Wide Web. It's located at <URL:http://www.w3.org/>. |
This chapter describes some of the more common Web extensions. You first learn extensions to HTML, including client-side imagemaps, frames, and some other browser-specific extensions. You then learn Netscape's server-side push and how you can use server-side push to create inline animation. You learn how to maintain state using HTTP cookies. Finally, you see an example of server extension: NCSA and Apache Web servers' capability to use a special CGI program to print customized error messages.
| Note |
I don't discuss some of the new Web client technologies such as Java and JavaScript in this chapter; their scope is much too broad to discuss them in any detail in this book. I mention and briefly discuss both technologies in Chapter 8, "Client/Server Issues." |
Perhaps the most dynamic Web technology is HTML, which is a constantly evolving technology. Many have proposed extensions to the current standard, and a large number of these extensions are widely supported by most Web browsers. Netscape is largely responsible for many of these proposed extensions, and because the Netscape browser is the most widely used on the Web, many other browsers have adopted these extensions as well. Microsoft is also beginning to develop new extensions and has introduced a few original ones of its own, implemented in its Internet Explorer browser.
Four extensions are described in this section: client-side imagemaps, HTML frames, client-side pull, and some miscellaneous extensions. Client-side imagemaps were originally proposed by Spyglass, and many browsers have since adopted this standard. HTML frames and client-side pull are both Netscape proposals; although these features have not been widely implemented on other browsers, many Web authors take advantage of these extensions because of the popularity of the Netscape browser. Finally, the miscellaneous extensions discussed are some of Microsoft's proposed HTML tags to improve the multimedia capabilities of the Web.
In Chapter 15, "Imagemaps," you learn the most common way to implement imagemaps: using a server-side application such as the CGI program imagemap. However, even though there is an advantage to using a server application for customized imagemap applications (such as the tictactoe program in Chapter 15), a server-based imagemap is a slow operation by nature. The imagemap CGI program works as follows:
In order to determine where to go next, the browser needs to make
two different requests. It is much more efficient to define where
to go next within the HTML document so that the browser needs
to make only one request, as shown in Figure 14.1.
A client-side imagemap contains the mapping information within
an HTML document so that the browser can figure out where to go
according to where the user clicked on the image.
To specify that an image is part of a client-side imagemap, you use the parameter USEMAP with the <image> tag:
<IMG SRC=" . . . " USEMAP=" . . . ">
The value of USEMAP is the location of the map information. Map information is specified using the <map> tag:
<MAP NAME=" . . . "> </MAP>
NAME is the identifier of this map. The value of NAME is referenced by USEMAP the same way you would reference an <a name> tag, preceded by a pound sign (#). For example, the client-side imagemap
<img src="buttons.gif" usemap="#buttonbar">
would correspond to the map information in the same HTML page labeled with this:
<map name="buttonbar">
You can store the map information in a separate file from the actual imagemap. For example, if you had a button bar that was the same on all of your pages, you might want to store the map information in the file buttonbar.html surrounded by the tags <map name="buttonbar"> and </map>. Then, to reference your button bar in your documents, you would use this:
<img src="buttons.gif" usemap="buttonbar.html#buttonbar">
Within the <map> tags, you store the definitions of your map using the <area> tag. The <area> tag relates an area on the image to another document. Here is the proper format for the <area> tag:
<AREA [SHAPE=" . . . "] COORDS=" . . . " [HREF=" . . . "] [NOHREF] [ALT=" . . . "]>
SHAPE defines the shape of the area. By default, if you do not specify a SHAPE parameter, <area> assumes a rectangular shape. The possible shapes you can define depend on the browser. Shapes commonly defined by browsers are RECT, CIRCLE, and POLYGON. COORDS contains a comma- delimited list of coordinates that define the boundaries of your area. A rectangular area requires four numbers to describe it: the x and y coordinates of the upper-left and lower-right corner. Thus, the COORDS value of a rectangular shape would take the following form:
upperleft_x,upperleft_y,lowerright_x,lowerright_y
COORDS for a circle take this format:
center_x,center_y,radius
Polygons take a list of coordinates of each vertex. Although there is no theoretical limit to the number of vertices you can define for your polygon, there is a practical limit. HTML does not enable parameter values larger than 1024 characters.
HREF specifies where to go if the user has clicked in the area specified by that <area> tag. If you do not specify an HREF parameter or if you specify NOHREF, then the browser will ignore any clicks within that area. This is not a very useful parameter because the browser will simply ignore clicks in any undefined region. If you don't want the browser to do anything if the user clicks on a certain region, just don't define that region.
ALT is a text description of the specified area and is used by text browsers that cannot view images. If you view a client-side imagemap from a text browser, you'll see a list of names (specified by the ALT parameter in each <area> tag). Clicking one of these names takes you to the URL specified in HREF.
If you define two areas that intersect, the first area defined takes precedence. For example, with the following imagemap the rectangular region bounded by (30,0) and (50,50) is covered by both regions:
<img src="map.gif" usemap="#mymap">
<map name="mymap">
<area coords="0,0,50,50" href="one.html">
<area coords="30,0,80,50" href="two.html">
</map>
If a user clicks anywhere inside this common region, then he or she will go to one.html, because that is the first <area> tag specified.
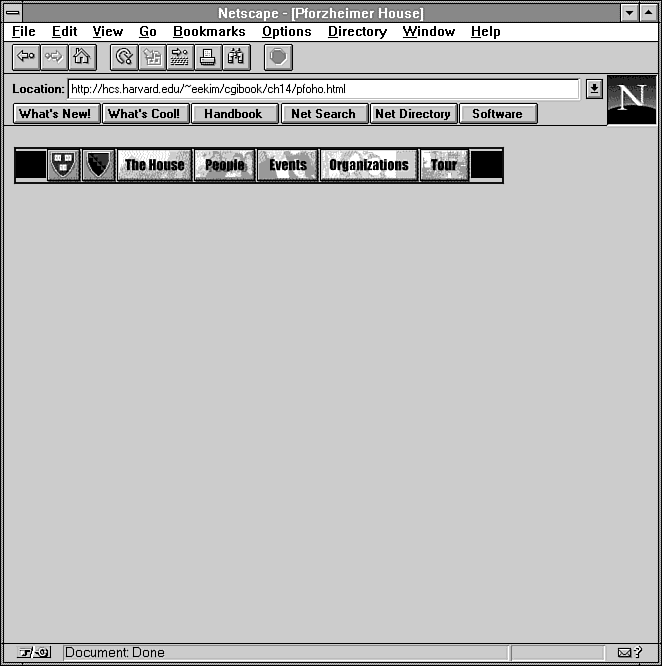
Listing 14.1 contains some sample HTML for a client-side imagemap.
Figure 14.2 shows how this imagemap looks
from a browser.
Figure 14.2 : The rendered client-side imagemap from Listing 14.1.
Listing 14.1. A sample client-side imagemap.
<html> <head>
<title>Pforzheimer House</title>
</head>
<body>
<a href="/cgi-bin/imagemap/~pfoho/imagemaps/pfoho-buttons.map">
<img src="/~pfoho/images/pfoho-buttons.gif" alt="[Short Cuts]"
ISMAP USEMAP="#pfoho-buttons"></a>
<map name="pfoho-buttons">
<area href="http://www.harvard.edu/" coords="31,0,65,33"
alt="Harvard University">
<area href="index.html" coords="66,0,100,33" alt="Pforzheimer House">
<area href="house/" coords="101,0,177,33" alt="The House">
<area href="people/" coords="178,0,240,33" alt="People">
<area href="events/" coords="241,0,303,33" alt="Events">
<area href="orgs/" coords="304,0,403,33" alt="Organizations">
<area href="tour/" coords="404,0,453,33" alt="Tour">
</map>
</body> </html>
The standard Web browser consists of one window that displays
the HTML or other documents. Netscape has introduced extensions
that enable you to divide up this single window into multiple
"frames," where each frame essentially acts as a separate
window. Figure 14.4 later in this chapter
is an example of a standard Web page using frames. Using frames,
you can keep common elements of your Web site on the browser window
at all times while the user browses through the other documents
on your site in a separate frame.
Frames follow a very similar syntax to HTML tables. To specify a frame, you use the tag <frameset>, which replaces the <body> tag in an HTML document.
<html>
<head>
</head>
<frameset>
</frameset>
</html>
The format of the <frameset> tag is
<FRAMESET ROWS|COLS=" . . . "> </FRAMESET>
The <frameset> tag takes either the ROWS or COLS attribute. The value of the ROWS attribute specifies how to divide the browser window into rows, just as the COLS attribute specifies how to divide the window into columns. The ROWS and COLS attributes take a list of values that describe the division of the particular frameset. You can specify the height of a frame row or the width of a frame column as a percentage of the window size, by pixel size, or by whatever is left.
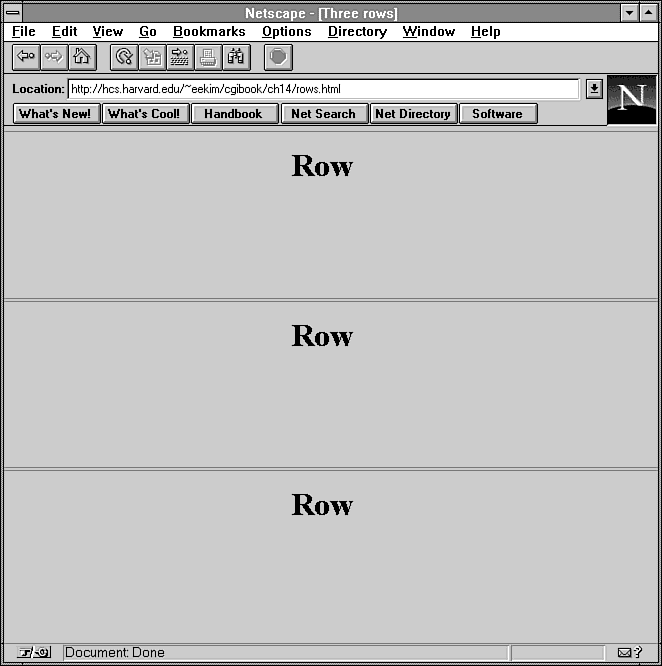
For example, suppose you wanted to divide up a window into three
rows of equal width, as shown in Figure 14.3.
If you assume that the browser window is 300 pixels high, you
could use this:
Figure 14.3 : Dividing the brower window into three rows.
<frameset rows="100,100,100">
Unfortunately, you can almost never guarantee the height of the browser; therefore, this is not usually a good specification. (It is useful if you have a fixed-size graphic within one of the frames.) You could instead specify the percentage of the current window each row should take.
<frameset rows="33%,33%,34%">
Note that the sum of the percentages in the ROWS attribute must equal 100%. If the values do not add up to 100% and there are no other types of values, then the percentages are readjusted so that the sum is 100%. For example:
<frameset rows="30%,30%">
is equivalent to
<frameset rows="50%,50%">
Using this tag, the size of the frames will readjust when the browser is resized. Although this method works well, there is an even simpler method.
<frameset rows="*,*,*">
The asterisk (*) tells the frame to use relative sizes for determining the size of the rows. The three asterisks mean that each row should split the available height evenly. If you want to make the first row twice as big as the other two rows, you could use this:
<frameset rows="2*,*,*">
You can mix different value types in the ROWS or COLS attribute. For example, the following will create one row 100 pixels high and split the remaining space in half for the remaining two rows:
<frameset rows="100,*,*">
If you use the following, the first row would take up 20 percent of the window height, the second row would take up 30 percent, and the last row would use up the rest of the space:
<frameset rows="20%,30%,*">
The number of values in the ROWS or COLS parameter determines the number of rows or columns within a frameset. Within the <frameset> tags, you define each frame using another <frameset> tag that will further divide that frame, or you can use the <frame> tag to specify attributes of that frame. Here is the <frame> tag's format:
<FRAME [SRC=" . . . " NAME=" . . . " MARGINWIDTH=" . . . " MARGINHEIGHT=" . . . "
SCROLLING="no|yes|auto" NORESIZE]>
If you do not specify any attributes within the <frame> tag, you'll just see an empty frame. SRC specifies the document that goes in that frame. NAME is the name of the frame. The NAME is useful because it enables you to force the output of CGI programs to appear in specific frames. MARGINWIDTH and MARGINHEIGHT are aesthetic tags that define the width of the margins between the content of the document and the border of the frame. SCROLLING determines whether or not a scrollbar should appear within the frame. By default, SCROLLING is set to auto, meaning that a scrollbar appears only when necessary. You can set it to always appear (yes) or to never appear (no). Finally, by default, the user can change the size of the frames from his or her browser. Specifying NORESIZE disables this feature.
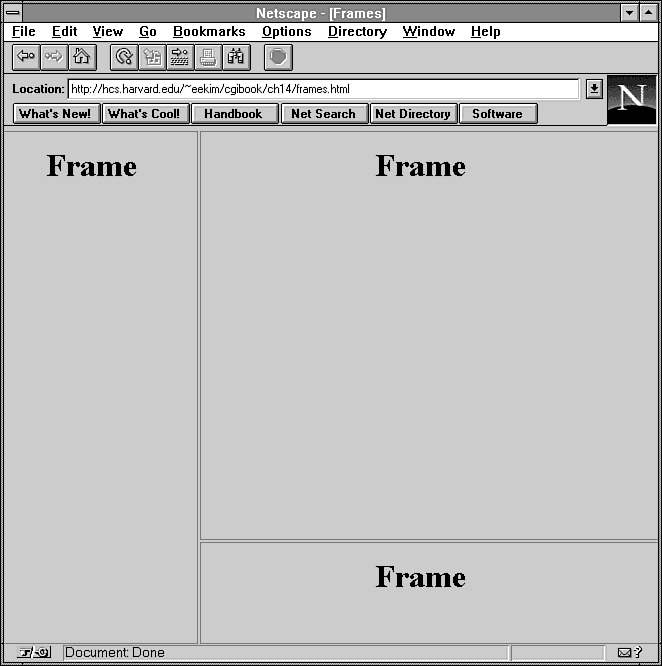
Listing 14.2 contains a sample HTML document that defines several
empty frames. Figure 14.4 shows what
frames.html looks like from your browser.
Listing 14.2. The frames.html program.
<html> <head>
<title>Frames</title>
</head>
<frameset cols="30%,70%">
<frame>
<frameset rows="80%,20%">
<frame>
<frame>
</frameset>
</frameset>
</html>
You can describe an alternative HTML document within the <frameset> tags that browsers that do not understand frames will display. To do this, embed the HTML within the tags <NOFRAMES> </NOFRAMES>. These tags should go between the <frameset> tags. Listing 14.3 contains an example of a frame with alternate HTML.
Listing 14.3. The alt-frames.html program.
<html> <head>
<title>Frames</title>
</head>
<frameset cols="30%,70%">
<noframes>
<h1>Frames</h1>
<p>This HTML document contains frames. You need a frames-enabled
browser such as Netscape v2.0 or greater to view them.</p>
</noframes>
<frame>
<frameset rows="80%,20%">
<frame>
<frame>
</frameset>
</frameset>
</html>
How do you redirect output to one of these frames? There are two
situations in which you might want to redirect output, and two
ways to handle these situations. The first possibility is that
you have clicked a link-either an <a
href>, a <form>
submit button, or a client-side imagemap <area>-and
you want the retrieved document to appear in one of your frames
or even in a new browser window. You can accomplish this using
the TARGET attribute in either
the <a href>, <form>,
<area>, or <base>
tag. You can specify either the name of a browser, the name of
a frame, or a special variable (listed in Table 14.1) in the TARGET
attribute.
| Variable | |
| _blank | Loads the new document in a new, unnamed, blank window. |
| _self | Loads the new document in the current window or frame. This is the default behavior if no TARGET attribute is specified. It can be used to override TARGETs globally defined in the <BASE> tag. |
| _parent | Loads the new document in the <frameset> parent of the current document. If no parent exists, it behaves like _self. |
| _top | Loads the new document in the full body of the window. |
For example, the following frame document splits the screen in half and places doc1.html in the left frame, called "left," and doc2.html in the right frame, called "right":
<html> <head>
<title>Frames</title>
</head>
<frameset cols="*,*">
<frame src="doc1.html" name="left">
<frame src="doc2.html" name="right">
</frameset>
</html>
If doc1.html had the following tag when a user clicks "new document," new.html displays in the left frame:
<a href="new.html">new document</a>
If, however, doc1.html contains
<a href="new.html" target="right">new document</a>
then, when the user clicks "new document," new.html appears in the right frame. Similarly, if doc1.html contains the following and the user clicks "new document" or any other link on that page, the new document appears in the right frame:
<html><head>
<title>First Document</title>
<base target="right">
</head>
<body>
<a href="new.html">new document</a>
</body></html>
Similarly, you can target CGI output by sending the HTTP header Window-target followed by the window or frame name. For example, if you wanted to send the output of a CGI program to the right frame, you could send this:
Window-target: right
Content-Type: text/plain
output from CGI program
Netscape has a feature called client-side pull that enables you to tell the browser to load a new document after a specified amount of time. This has several potential uses. For example, if you provide real-time sports scores on your Web site, you might want the page to automatically update every minute. Normally, if the user wants to see the latest scores, he or she would have to use the browser's reload function. With client-side pull, you can tell the browser either to automatically reload or load a new page after a specified amount of time.
You specify client-side pull by using the Netscape CGI response header Refresh. The following is the format for the header, where n is the number of seconds to wait before refreshing:
Refresh: n[; URL=url]
If you want the document to load another URL after n seconds instead of reloading the current document, you specify it using the parameter URL followed by the URL.
For example, if you had a CGI program called scores.cgi that sends an HTML document with the current sports scores, you could have it tell the Netscape browser to reload every 30 seconds.
#!/usr/local/bin/perl
# scores.cgi
print "Refresh: 30\n";
print "Content-Type: text/html\n\n";
print "<html> <head>\n";
print "<title>Scores</title>\n";
print "</head>\n\n";
print "<body>\n";
print "<h1>Latest Scores</h1>\n";
# somehow retrieve and print the latest scores here
print "</body> </html>\n";
When a Netscape browser calls scores.cgi, it displays the HTML document, waits 30 seconds, and then reloads the document.
If you were serving scores.cgi from http://scores.com/cgi-bin/scores.cgi and you moved the service to http://scores.sports.com/cgi-bin/scores.cgi, you might want the scores.cgi program at scores.com to send the header
Refresh: 30; URL=http://scores.sports.com/cgi-bin/scores.cgi
and a message that says the URL of this service has changed.
#!/usr/local/bin/perl
# replacement scores.cgi for http://scores.com/cgi-bin/scores.cgi
print "Refresh: 30;URL=http://scores.sports.com/cgi-bin/scores.cgi\n";
print "Content-Type: text/html\n\n";
print "<html><head>\n";
print "<title>Scores Service Moved</title>\n";
print "</head>\n\n";
print "<body>\n";
print "<h1>Scores Service Has Moved</h1>\n";
print "<p>This service has moved to";
print "<a href=\"http://scores.sports.com/cgi-bin/scores.cgi\">";
print "http://scores.sports.com/cgi-bin/scores.cgi</a>.\n";
print "If you are using Netscape, you will go to that document\n";
print "automatically in 30 seconds.</p>\n";
print "</body></html>\n";
When the user tries to access http://scores.com/cgi-bin/scores.cgi, it sends the previous message and the Refresh header. If you are using Netscape, your browser waits for 30 seconds and then accesses http://scores.sports.com/cgi-bin/scores.cgi.
Although sending a Refresh header from a CGI program to specify reloading the document might seem useful, sending that header to load another document does not. There isn't a good reason to use the Refresh header for redirection rather than the Location header if you are using a CGI program. For example, you could replace the old scores.cgi program with the following, which simply redirects the browser to the new URL:
#!/usr/local/bin/perl
print "Location: http://scores.sports.com/cgi-bin/scores.cgi\n\n";
This works for all browsers, not just Netscape.
The Refresh header is useful, however, because Netscape properly interprets the <META HTTP-EQUIV> <head> tag. As you might recall from Chapter 3, "HTML and Forms," <META HTTP-EQUIV> enables you to embed HTTP headers within the HTML document. For example, if you had an HTML document (rather than a CGI program) that had the latest scores, you could have it automatically reload by specifying the header using the <META HTTP-EQUIV> tag.
<html> <head>
<title>Sports Scores</title>
<meta http-equiv="Refresh" content="30">
</head>
<body>
<h1>Latest Scores</h1>
<!-- have the latest scores here -->
</body></html>
When Netscape loads this page, it displays it and then reloads the page after 30 seconds. Similarly, you could also have the HTML page load another page after a specified amount of time.
| Tip |
Although for most client-side pull documents you can create an equivalent effect using the <meta http-equiv> tag within an HTML document as you can by sending a Refresh header from a CGI program, you can create interesting applications using the Refresh header, which you can't do using <meta http-equiv>. For example, Netscape's documentation on client-side pull suggests creating a "roulette" CGI application that sends a Refresh header and the location of a random URL on the Internet. After a specified amount of time, the browser reloads the roulette program and takes you to a different random URL. This is impossible to implement using <meta http-equiv> because you have no control over the tags on the random Web sites and these sites more than likely do not contain <meta http-equiv> tags pointing to your roulette program. |
You can use client-side pull to automatically load a sound to accompany an HTML document, thereby implementing "inline" sound. For example, suppose you are the CEO of a company called Kaplan's Bagel Bakery, and you want to have an audio clip that plays automatically when the user accesses your Web page. Assuming your URL is http://kaplan.bagel.com/ and the audio clip is located at http://kaplan.bagel.com/intro.au, your HTML file might look like this:
<html><head>
<title>Kaplan's Bagel Bakery</title>
<meta http-equiv="Refresh" content="0;URL=http://kaplan.bagel.com/intro.au">
</head>
<body>
<h1>Kaplan's Bagel Bakery</h1>
<p>Welcome to our bagel shop!</p>
</body></html>
When you access this HTML file from Netscape, it immediately loads and plays the intro.au sound clip. You don't have to worry about the sound clip continuously loading because the sound clip will not have a Refresh header.
You can create some potentially useful applications using client-side pull, but you should use it in moderation. HTML documents that constantly reload can be annoying as well as a resource drain on both the server and client side. There are more efficient and aesthetic ways of implementing inline animation than using client-side pull.
Many of the custom extensions and techniques described in this chapter were created to improve the multimedia and visual capabilities of the World Wide Web. Microsoft provides three extensions to HTML that extend the multimedia capability of its Internet Explorer browser.
The tag <bgsound> enables you to play background sounds while the user is viewing a page.
<BGSOUND SRC=" . . . " [LOOP="n|infinite"]>
SRC is the relative location of either a WAV or AU sound file. By default, the sound plays only once. You can change this by defining LOOP to be either some number (n) or infinite.
Internet Explorer has two tags that offer some form of animation. The first, <marquee>, enables you to have scrolling text along your Web browser:
<MARQUEE [BGCOLOR=" . . . " DIRECTION="RIGHT|LEFT" HEIGHT="n|n%"
WIDTH="n|n%" BEHAVIOR=[SCROLL|SLIDE|ALTERNATE]
LOOP="n|infinite" SCROLLAMOUNT="n" SCROLLDELAY="n"
HSPACE="n" VSPACE="n" ALIGN="top|middle|bottom"]>
</MARQUEE>
The text between the <marquee> tags will scroll across the screen. DIRECTION specifies the direction the text moves, either left or right. HEIGHT and WIDTH can either be a pixel number or percentage of the entire browser window. BEHAVIOR specifies whether the text scrolls on and off the screen (scroll), slides onto the screen and stops (slide), or bounces back and forth within the marquee (alternate). SCROLLAMOUNT defines the number of pixels to skip every time the text moves, and SCROLLDELAY defines the number of milliseconds before each move. HSPACE and VSPACE define the margins in pixels. ALIGN specifies the alignment of the text within the marquee.
In order to include inline animations in Microsoft Audio/Visual format (*.AVI) in Internet Explorer, you use an extension to the <img> tag:
<IMG DYNSRC="*.AVI" [LOOP="n|infinite" START="fileopen|,mouseover"
CONTROLS]>
DYNSRC contains the location of the *.avi file (just as SRC contains the location of the graphic file). LOOP is equivalent to LOOP in both <bgcolor> and <marquee>. If CONTROLS is specified, video controls are displayed underneath the video clip, and the user can rewind and watch the clip again. START can take two values: fileopen or mouseover. If fileopen is specified, the video plays as soon as the file is accessed. If mouseover is specified, the video plays every time the user moves the mouse over the video. You can specify both at the same time, separating the two values with a comma.
As an alternative to client-side pull for generating dynamically changing documents, Netscape developed a protocol for server-side push applications. A server-side push application maintains an open connection with the browser and continuously sends several frames of data to the browser. The browser displays each data frame as it receives it, replacing the previous frame with the current one.
In order to tell the browser to expect a server-side push application, the CGI application sends the MIME type multipart/x-mixed-replace as the Content-Type. This MIME type is an experimental, modified version of the registered MIME type multipart/mixed.
| Note |
The MIME type multipart/mixed is used to send a document consisting of several different data types as one large document. Mail readers and other MIME applications use this to send information such as text and graphics together as one single entity of information. |
The MIME type multipart/x-mixed-replace follows the same format as multipart/mixed. You specify the MIME type followed by a semicolon (;) and the parameter boundary, which specifies a separator string. This string separates all of the different data types in the entity, and it can be any random string containing valid MIME characters. For example:
Content-Type: multipart/x-mixed-replace;boundary=randomstring
--randomstring
When the browser reads this header, it knows that it will be receiving several blocks of data from the same connection, so it keeps the connection open and waits to receive the data. The browser reads and displays everything following-randomstring until it reads another instance of-randomstring. When it receives this closing-randomstring string boundary, it continues to keep the connection open and waits for new information. It replaces the old data with the new data as soon as it receives it until, once again, it reaches another boundary string. Each data block within the two boundary strings has its own MIME headers that specify the type of data. This way, you can send multiple blocks of different types of data, from images to text files to sound.
Each boundary string is defined as two dashes (--) followed by the boundary value specified in the multipart/x-mixed-replace header. The last data block you want to send ends with two dashes, followed by the boundary value, followed by another two dashes. However, there is no need to have a final data block. The server-side push application can continue to send information indefinitely. At any time, the user can stop the flow of data by clicking the browser's Stop button.
For example, suppose you had the five text files listed in Listings 14.4 through 14.8.
Listing 14.4. The first text file.
|
|
|
|
|
Listing 14.5. The second text file.
/
/
/
/
/
Listing 14.6. The third text file.
- - - - -
Listing 14.7. The fourth text file.
\
\
\
\
\
Listing 14.8. The fifth text file.
|
|
|
|
|
To force the browser to display all five of these text files in succession as quickly as possible, you would write a CGI program that sends the following to the browser:
Content-Type: multipart/x-mixed-replace;boundary=randomstring
--randomstring
Content-Type: text/plain
|
|
|
|
|
--randomstring
Content-Type: text/plain
/
/
/
/
/
--randomstring
Content-Type: text/plain
-----
--randomstring
Content-Type: text/plain
\
\
\
\
\
--randomstring
Content-Type: text/plain
|
|
|
|
|
--randomstring-
Upon receiving a block of data like this, Netscape prints each text file as soon as it receives it (in this case achieving an animated twirling bar effect.) Each data type contains its own Content-Type header that specifies the type of data between that header and the string boundary. In this example, each block of data is a plain text file; thus, the Content-Type: text/plain header. Notice also that the final data block ends with two dashes, followed by the boundary value, followed by another two dashes (--randomstring--). In this example, all of the blocks of data are the same type; however, this does not have to be the case. You could replace text with images or sound.
A common application of server-side push is to create inline animation that sends several GIF files in succession, creating animation. For example, if you had two GIF frames of an animated sequence (frame1.gif and frame2.gif), a server-side push program that sent each of these frames might look like this:
#!/usr/local/bin/perl
print "Content-Type: multipart/x-mixed-replace;boundary=blah\n\n";
print "-blah\n";
print "Content-Type: image/gif\n\n";
open(GIF,"frame1.gif");
print <GIF>;
close(GIF);
print "\n-blah\n";
print "Content-Type: image/gif\n\n";
open(GIF,"frame2.gif");
print <GIF>;
close(GIF);
print "\n-blah--\n";
Writing a general animation program that loads several GIF images and repeatedly sends them using server-side push is easy in principle. All it requires is a loop and several print statements. However, in reality, you might get choppy or slow animation. In the case of server-side push animations, you want to do everything you can in order to make the connection and the data transfer between the server and client as fast as possible. For some very small animations on a very fast connection, any code improvements might not be noticeable; however, on slower connections with more frames, more efficient code greatly enhances the quality of the animation.
The best way to prevent choppiness in your server-side push animations is to unbuffer the output. Normally, when you do a print in Perl or a printf() in C, the data is buffered before it is printed to the stdout. If the internal buffer size is large enough, there might be a slight delay as the program waits for the buffer to fill up before sending the information to the browser. Turning off buffering prevents these types of delays. Here's how to turn off buffering in Perl for stdout:
select(stdout);
$| = 1;
In C:
#include <stdio.h>
setbuf(stdout,NULL);
Normally, the server also buffers output from the CGI program before sending it to the client. This is undesirable for the same reason internal buffering is undesirable. The most portable way to overcome this buffering is to use an nph CGI program that speaks directly to the client and bypasses the server buffering. There is also another very minimal performance gain because the headers of the CGI output are not parsed, although this gain is nil for all practical purposes.
| Note |
For more information on buffering, see Chapter 6, "Programming Strategies." |
I wrote two general server-side push animation programs in Perl
and C (nph-animate.pl and nph-animate.c, respectively) that send
a finite number of individual GIF files continuously to the browser.
All of the GIF files must have the same prefix and exist in the
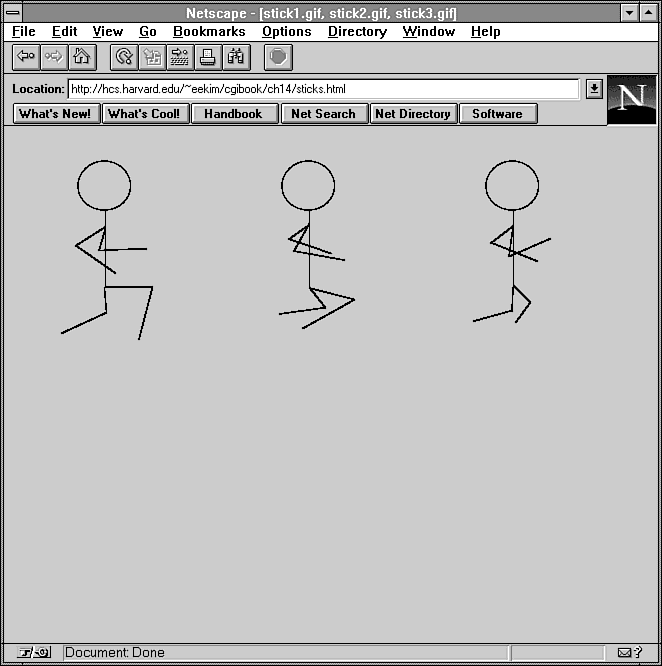
same directory somewhere within the Web document tree. For example,
if you have three GIF files, stick1.gif, stick2.gif, and stick3.gif
(see Figure 14.5), located in the directory
/images relative to the document
root, you would include these files as an inline animation within
your HTML document using this:
Figure 14.5 : Three GIF files: stick1.gif, stick2.gif, and stick3.gif.
<img src="/cgi-bin/nph-animate/images/stick?3">
nph-animate assumes that all of the images are GIF files and end in the prefix .gif. It also assumes that they are numbered 1 through some other number, specified in the QUERY_STRING (thus, the 3 following the question mark in the previous reference).
The Perl code for nph-animate.pl (shown in Listing 14.9) is fairly straightforward. It turns off buffering, reads the location and number of files, prints an HTTP header (because it is an nph script) and the proper Content-Type header, and then sends the GIFs one-by-one, according to the previous specifications. In order to make sure the script dies if the user clicks the browser's Stop button, nph-animate.pl exits when it receives the signal SIGPIPE, which signifies that the program can no longer send information to the browser (because the connection has been closed).
Listing 14.9. nph-animate.pl: a push animation program written in Perl.
#!/usr/local/bin/perl
$SIG{'PIPE'} = buhbye;
$| = 1;
$fileprefix = $ENV{'PATH_TRANSLATED'};
$num_files = $ENV{'QUERY_STRING'};
$i = 1;
print "HTTP/1.0 200 Ok\n";
print "Content-Type: multipart/x-mixed-replace;boundary=whatever\n\n";
print "-whatever\n";
while (1) {
&send_gif("$fileprefix$i.gif");
print "\n-whatever\n";
if ($i < $num_files) {
$i++;
}
else {
$i = 1;
}
}
sub send_gif {
local($filename) = @_;
local($filesize);
if (-e $filename) {
print "Content-Type: image/gif\n\n";
open(GIF,$filename);
print <GIF>;
close(GIF);
}
else {
exit(1);
}
}
sub buhbye {
exit(1);
}
I use several system-specific, low-level routines in the C version of nph-animate (shown in Listing 14.10) for maximum efficiency. It will work only on UNIX systems, although porting it to other operating systems should not be too difficult.
First, instead of using <stdio.h> functions, I use lower-level input and output functions located in <sys/file.h> on BSD-based systems and in <sys/fcntl.h> on SYSV-based systems. If write() cannot write to stdout (if the user has clicked the browser's Stop button and has broken the connection), then nph-animate.c exits.
Reading the GIF file and writing to stdout requires defining a buffer size. I read the entire GIF file into a buffer and write the entire file at once to stdout. Even with the inherent delay in loading the file to the buffer, it should be faster than reading from the file and writing to stdout one character at a time. In order to determine how big the file is, I use the function fstat() from <sys/stat.h>, which returns file information for files on a UNIX system.
Listing 14.10. nph-animate.c: a push animation program written in C.
#include <sys/file.h> /* on SYSV systems, use <sys/fcntl.h> */
#include <sys/stat.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#define nph_header "HTTP/1.0 200 Ok\r\n"
#define multipart_header \
"Content-Type: multipart/x-mixed-replace;boundary=whatever\r\n\r\n"
#define image_header "Content-Type: image/gif\r\n\r\n"
#define boundary "\n-whatever\n"
void send_gif(char *filename)
{
int file_desc,buffer_size,n;
char *buffer;
struct stat file_info;
if ((file_desc = open(filename, O_RDONLY)) > 0) {
fstat(file_desc,&file_info);
buffer_size = file_info.st_size;
buffer = malloc(sizeof(char) * buffer_size + 1);
n = read(file_desc,buffer,buffer_size);
if (write(STDOUT_FILENO,buffer,n) < 0)
exit(1);
free(buffer);
close(file_desc);
}
else
exit(1);
}
int main()
{
char *picture_prefix = getenv("PATH_TRANSLATED");
char *num_str = getenv("QUERY_STRING");
char *picture_name;
int num = atoi(num_str);
int i = 1;
char i_str[strlen(num_str)];
if (write(STDOUT_FILENO,nph_header,strlen(nph_header))<0)
exit(1);
if (write(STDOUT_FILENO,multipart_header,strlen(multipart_header))<0)
exit(1);
if (write(STDOUT_FILENO,boundary,strlen(boundary))<0)
exit(1);
while (1) {
if (write(STDOUT_FILENO,image_header,strlen(image_header))<0)
exit(1);
sprintf(i_str,"%d",i);
picture_name = malloc(sizeof(char) * (strlen(picture_prefix) +
strlen(i_str)) + 5);
sprintf(picture_name,"%s%s.gif",picture_prefix,i_str);
send_gif(picture_name);
free(picture_name);
if (write(STDOUT_FILENO,boundary,strlen(boundary))<0)
exit(1);
if (i < num)
i++;
else
i = 1;
}
}
Using nph-animate, I include an inline animation of my stick figures
(stick1.gif, stick2.gif, and stick3.gif) running within an HTML
document, as shown in Figure 14.6.
Figure 14.6 : The stick figure running within an HTML document.
Perhaps one of the most popular features people want to see on the Web is the capability to upload as well as download files. The current draft of the HTTP 1.0 protocol (February, 1996) defines a means for uploading files using HTTP (PUT), but very few servers have actually implemented this function.
| Note |
For more information about Web server protocols (HTTP), see Chapter 8, "Client/Server Issues." To see the file uploading using forms proposal, see RFC1867. |
Web develpers have proposed a means of uploading files using the form's POST mechanism. At the time of the printing of this book, the only browser that has implemented this feature is Netscape v2.0 or greater. Here, I describe how Netscape has implemented file uploading as well as how to implement this feature using CGI programs.
| Caution |
Netscape has implemented file uploading a bit differently from the specifications in RFC1867. The most notable difference is the absence of a Content-Type header to describe each data block. This section is tailored to Netscape's implementation, because Netscape is the only browser that has implemented this feature so far. I highly encourage you to read both RFC1867 and your browser's documentation to make sure you are properly supporting file upload. |
In order to use file upload, you must define ENCTYPE in the <form> tag to be the MIME type "multipart/form-data".
<FORM ACTION=" . . . " METHOD=POST ENCTYPE="multipart/form-data">
This MIME type formats form name/value pairs as follows:
Content-Type: multipart/form-data; boundary=whatever
-whatever
Content-Disposition: form-data; name="name1"
value1
-whatever
Content-Disposition: form-data; name="name2"
value2
--whatever-
This is different from the normal URL encoding of form name/value pairs, and for good reason. For regular, smaller forms consisting mostly of alphanumeric characters, this seems to send a lot of extraneous information-all of the extra Content-Disposition headers and boundaries. However, large binary files generally consist of mostly non-alphanumeric characters. If you try to send a file using the regular form URL encoding, the size of the transfer will be much larger because the browser encodes the many non-alphanumeric characters. The previous method, on the other hand, does not need to encode any characters. If you are uploading large files, the size of the transfer will not be much larger than the size of the files.
In order to allow the user to specify the filename to upload, you use the new input type file:
<INPUT TYPE=FILE NAME="...">
In this case, NAME is not
the filename, but the name associated with that field. For example,
if you use a form such as upload.html (shown in Listing 14.11),
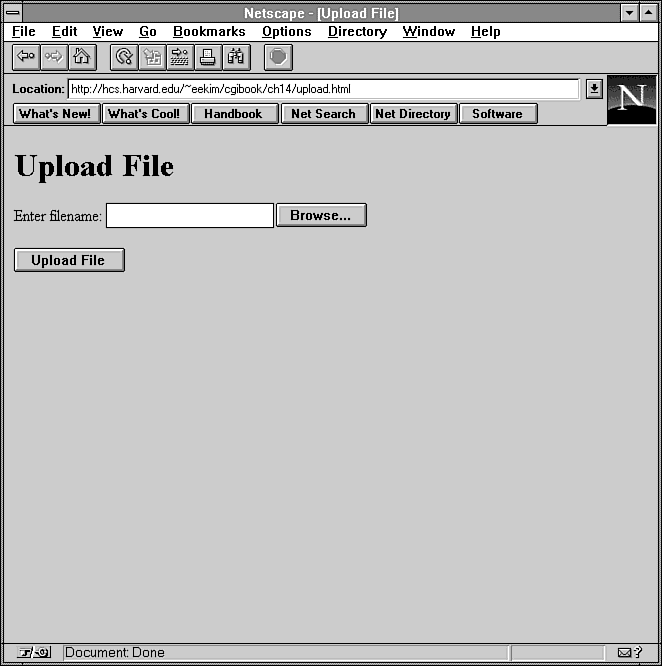
your browser will look like Figure 14.7.
Figure 14.7 : The brower prompts the user to enter the filename of the file to upload.
Listing 14.11. The form upload.html.
<html><head>
<title>Upload File</title>
</head>
<body>
<h1>Upload File</h1>
<form action="/cgi-bin/upload.pl" method=POST enctype="multipart/form-data">
<p>Enter filename: <input type=file name="filename"></p>
<p><input type=submit value="Upload File"></p>
</form>
</body></html>
You can either directly type the complete path and filename of the file you want to upload in the text field, or you can click the Browse button and select the file using Netscape's File Manager. After you enter the filename and press Submit, the file is encoded and sent to the CGI program specified in the ACTION parameter of the <form> tag (in this case, upload.pl).
Suppose you have a text file (/home/user/textfile) that you want to upload. If you enter this into the file field of the form and press Submit, the browser sends something like the following to the server:
Content-Type: multipart/form-data; boundary=whatever
Content-Length: 161
-whatever
Content-Disposition: form-data; name="filename"; filename="textfile"
contents of your textfile
called "textfile" located in /home/user.
--whatever-
Notice that the filename-stripped of its path-is located in the Content-Disposition header, and that the contents of your text file follow the blank line separating the header from the contents. When the server receives this data, it places the values of the Content-Type and Content-Length headers into the environment variables CONTENT_TYPE and CONTENT_LENGTH, respectively. It then sends all of the data following the first blank line, including the first boundary line, to the stdin. Your CGI program should be able to parse this data and perform the desired actions.
The concept of any person uploading files to your server conjures up many fears about security. The file upload protocol deals with security in several ways. First, only the name of the file is sent to the browser, not the path. This is to address potential privacy concerns. Second, you must type the filename and press the Submit button in order to submit a file. The HTML author cannot include a hidden input field that contains the name of a file that is potentially on the client's machine. If this were possible, then people browsing the Web risk the danger of allowing malicious servers to steal files from the client machines. This is not possible under the current implementation because the user must explicitly type and approve any files he or she wants to upload to the server.
Parsing data of type multipart/form-data is a challenging task because you are dealing with large amounts of data, and because there is no strict standard protocol yet. Only time can solve the latter problem, and if you need to write CGI programs that implement file uploading, you'll want to prepare yourself for changes in the standard.
There are good strategies for dealing with the problem of large data size. In order to best demonstrate the challenges of parsing multipart/form-data encoded data and to present strategies and solutions, I present the problem as posed to a Perl programmer. The problem is much more complex for the C programmer, who must worry about data structures, dynamically allocating memory, and writing proper parsing routines; however, the same solutions apply.
Forget for a moment the size of the data and approach this problem as a Perl programmer with no practical limits. How would you parse this data? You might read the CONTENT_LENGTH variable to determine how much data there is and then read the entire contents of stdin into a buffer called $buffer.
$length = $ENV{'CONTENT_LENGTH'};
read(STDIN,$buffer,$length);
This loads the entire data block into the scalar variable $buffer. At this stage, parsing the data is fairly simple in Perl. You could determine what the boundary string is, split the buffer into chunks of data separated by the boundary string, and then parse each individual data chunk.
However, what if someone is uploading a 30MB file? This means you need at least 30MB of spare memory to load the contents of stdin into the variable $buffer. This is an impractical demand. Even if you have enough memory, you probably don't want one CGI process to use up 30MB of memory.
Clearly, you need another approach. The one I use in the program upload.pl (shown in Listing 14.12) is to read the stdin in chunks and then write the data to a temporary file to the hard drive. After you are finished creating the temporary file, you can parse that file directly. Although it requires an additional 30MB of space on your hard drive, this is much more likely and more practical than needing that equivalent of RAM. Additionally, if there is some error, you can use the temporary file for debugging information.
| Note |
As an alternative, you could read the standard input in chunks and parse each line individually. This is a riskier proposition for a number of reasons: it is more difficult, if there is some error or delay there is no means for recovery, and debugging is difficult. |
Parsing the temporary file is fairly simple. Determine whether the data you are about to parse is a name/value pair or a file using the Content-Disposition header. If it is a name/value pair, parse the pair and insert it into the associative array %input keyed by name. If it is a file, open a new file in your upload directory and write to the file until you reach the boundary string. Continue to do this until you have parsed the entire file.
| Caution |
In UNIX, you need to make sure your upload directory ($UPLOADDIR in upload.pl) has the proper permissions so that the CGI program can write to that directory. |
Listing 14.12 contains the complete Perl code for upload.pl. You need to change two variables: $TMP, the directory that stores the temporary file, and $UPLOADDIR, the directory that contains the uploaded files. upload.pl generates the name of the temporary file by appending the time to the name formupload-. It saves the data to this temporary file, and parses it.
Listing 14.12. The upload.pl program.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
$TMP = '/tmp/';
$UPLOADDIR = '/usr/local/etc/httpd/dropbox/';
$CONTENT_TYPE = $ENV{'CONTENT_TYPE'};
$CONTENT_LENGTH = $ENV{'CONTENT_LENGTH'};
$BUF_SIZ = 16834;
# make tempfile name
do {
$tempfile = $TMP."formupload-".time
} until (!(-e $tempfile));
if ($CONTENT_TYPE =~ /^multipart\/form-data/) {
# save form data to a temporary file
($boundary = $CONTENT_TYPE) =~ s/^multipart\/form-data\; boundary=//;
open(TMPFILE,">$tempfile");
$bytesread = 0;
while ($bytesread < $CONTENT_LENGTH) {
$len = sysread(STDIN,$buffer,16834);
syswrite(TMPFILE,$buffer,$len);
$bytesread += $len;
}
close(TMPFILE);
# parse temporary file
undef %input;
open(TMPFILE,$tempfile);
$line = <TMPFILE>; # should be boundary; ignore
while ($line = <TMPFILE>) {
undef $filename;
$line =~ s/[Cc]ontent-[Dd]isposition: form-data; //;
($name = $line) =~ s/^name=\"([^\"]*)\".*$/$1/;
if ($line =~ /\; filename=\"[^\"]*\"/) {
$line =~ s/^.*\; filename=\"([^\"]*)\".*$/$1/;
$filename = "$UPLOADDIR$line";
}
$line = <TMPFILE>; # blank line
if (defined $filename) {
open(NEWFILE,">$filename");
}
elsif (defined $input{$name}) {
$input{$name} .= "\0";
}
while (!(($line = <TMPFILE>) =~ /^--$boundary/)) {
if (defined $filename) {
print NEWFILE $line;
}
else {
$input{$name} .= $line;
}
}
if (defined $filename) {
close(NEWFILE);
}
else {
$input{$name} =~ s/[\r\n]*$//;
}
}
close(TMPFILE);
unlink($tempfile);
# print success message
print &PrintHeader,&HtmlTop("Success!"),&PrintVariables(%input),&HtmlBot;
}
else {
print &PrintHeader,&HtmlTop("Wrong Content-Type!"),&HtmlBot;
}
In Chapter 13, "Multipart Forms and Maintaining State," I describe three different methods for maintaining state. All three of the methods required the server to send the state information to the client embedded in the HTML document. The client returned the state back to the server either by appending the information to the URL, sending it as a form field, or sending a session ID to the server, which would use the ID to access a file containing the state information.
Netscape proposed an alternative way of maintaining state-HTTP cookies-which has since been adopted by several other browsers, including Microsoft's Internet Explorer. Cookies are name/value pairs along with a few attributes that are sent to and stored by the browser. When the browser accesses the site specified in the cookie, it sends the cookie back to the server, which passes it to the CGI program.
To send a cookie, you use the HTTP response header Set-Cookie.
Set-Cookie: NAME=VALUE; [EXPIRES=date; PATH=path; DOMAIN=domain]
The only required field is the name of the cookie (NAME) and its value (VALUE). Both NAME and VALUE cannot contain either white space, commas, or semicolons. If you need to include these characters, you can URL encode them. EXPIRES is an optional header that contains a date in the following format:
Dayname, DD-MM-YY HH:MM:SS GMT
If you do not specify an EXPIRES header, the cookie will expire as soon as the session ends. If the browser accesses the domain and the path specified by DOMAIN and PATH, it sends the cookie to the server as well. By default, DOMAIN is set to the domain name of the server generating the cookie. You can only set DOMAIN to a value within your own domain. For example, if your server and CGI program is on www.yale.edu, you can set the domain to be www.yale.edu and yale.edu, but not whitehouse.gov. Domains such as .edu or .com are too general, and are consequently not acceptable. If your server is running on a non-standard port number, you must include that port number in the DOMAIN attribute as well.
When the browser connects to a server, it checks its cookies to see if the server falls under any of the domains specified by one of its cookies. If it does, it then checks the PATH attribute. PATH contains a substring of the path from the URL. The most general value for PATH is /; this will force the browser to send the cookie whenever it is accessing any document on the site specified by DOMAIN. If no PATH is specified, then the path of the current document is used as the default.
| Caution |
Netscape v1.1 has a bug that refuses to set a cookie if the PATH attribute is not set. To prevent this and possible bugs in other browsers, it's good practice to include both the DOMAIN and PATH attributes when you are sending a cookie. |
| Tip |
Netscape has an additional cookie attribute, SECURE. If you set this attribute, then Netscape will send the cookie to the server only if it is using a secure protocol (SSL). |
To delete a cookie, send the same cookie with an expiration date that has already passed. The cookie will expire immediately. You can also change the value of cookies by sending the same NAME, PATH, and DOMAIN but a different VALUE. Finally, you can send multiple cookies by sending several Set-Cookie headers.
| Tip |
Netscape and some other browsers will enable you to set HTTP headers using the <meta> tag in your HTML documents. If you know your users are using browsers that support this functionality, programming a state application such as an online catalog can be greatly simplified. You would simply place the product ID in each HTML document as a cookie value: <META HTTP-EQUIV="Set-Cookie" CONTENT="product=1234"> This way, you would only need a CGI program to process all of the cookies when you are ready to order rather than a CGI program to send each cookie. |
When the browser sends the cookie back to the server, it sends it as an HTTP header of the following form:
Cookie: NAME1=VALUE1; NAME2=VALUE2
The server takes the value of this header and places it in the environment variable HTTP_COOKIE, which the CGI program can then parse to determine the value of the cookies.
Although HTTP cookies are an interesting and potentially useful feature, consider several factors before using them. First, because not all browsers have cookie capability, cookies are not useful for general state applications. However, if you are writing an application and you are sure the user will use a cookie-capable browser, there may be some advantage to using cookies.
Finally, there are some practical limitations to cookies. Some browsers will accept only a certain number of cookies per domain (for example, Netscape will accept only 20 cookies per domain and 300 total). An additional limitation is the size of constraint of the HTTP_COOKIE environment variable. If you have a site where you must potentially send many large cookies, you are better off using other state methods.
Several companies have extended some of the standard Web protocols in order to provide new and useful features. Most of these extensions are visual, such as extensions to HTML and server-side push to create inline animations. Other useful features include file upload and maintaining states using HTTP cookies.
Should you use these extensions? If some of these extensions provide a feature you need, and you are sure that your users will use browsers that support these features, then by all means do. However, for general use, remember that these features are not necessarily widely implemented and that the protocol is likely to change rapidly.