{kind=link}
{kind=link}




You are now ready to begin the real learning process: programming useful CGI applications. In this and the other chapters in this section, the techniques and the CGI protocol from the first part of this book are demonstrated by developing and discussing real applications.
This chapter begins with some very basic applications. Most of the examples are relatively small. The purpose is to show how you can apply your basic knowledge to perform powerful tasks. The chapter begins with two small programs written in Perl: a redirection manager and a content negotiation program. Finally, you move on to a larger application. You develop a generic program that parses any form and saves the content to a file, and then you extend it to perform flexible manipulation of the data.
In my two years developing Web sites and applications, I've found myself reusing some small, very simple CGI programs over and over again. Two small CGI programs are reproduced here: a redirection manager and a content negotiation application. These utilities are written in Perl to emphasize the CGI routines rather than the text processing routines; however, if you are running a heavily accessed server, you might want to rewrite these applications in C for more efficient responses.
| Note |
The tasks that these three applications perform are so common that many servers enable you to perform these tasks internally without the extra overhead of a CGI program. For example, among UNIX servers is the Apache server, which internally controls redirection and content negotiation using configuration files. If you have a heavily accessed site that often uses these features, you might want to see whether other servers for your platform support these features internally. |
As an HTML author, you might want to use some of the unique HTML extensions certain browsers support; however, you might be afraid that the pages with extensions look bad on browsers that don't support those extensions. Or, you might have a graphics-heavy Web page, and you would like to send a text-only page to browsers such as lynx that don't support graphics. Ideally, you could write a program that would determine the capabilities of the browser and then send the appropriate page.
This chapter shows a simple version of such a program called cn (which stands for content negotiation). Given the location and prefix of a document (index is the prefix of index.html, for example), cn does the following:
In order to determine what the browser is capable of viewing, cn checks two environment variables: HTTP_ACCEPT and HTTP_USER_AGENT. If you recall from Chapter 5, "Input," HTTP_ACCEPT stores a list of MIME types the browser can view. You can use HTTP_ACCEPT to determine whether the browser is text-only or not by scanning the environment variable for the word image (as in image/gif or image/jpeg). If it finds this word, it assumes the browser is a graphical browser; otherwise, it assumes the browser is text-only.
If the browser is graphical, cn then checks HTTP_USER_AGENT to determine the brand of the browser. This book primarily focuses on Netscape Navigator and Microsoft Internet Explorer. You can easily expand this program to fit your specific browser needs. Netscape and some versions of Internet Explorer store the word Mozilla in HTTP_USER_AGENT; other versions of Internet Explorer store Internet Explorer.
After cn determines the browser type, it then tries to send the appropriate file. The proper HTML files are determined by filename extension. The default, global extension that cn will use if it cannot find any other files is .html. The other extensions are .thtml (for text HTML) and .mhtml (for Mozilla/Microsoft HTML, whatever suits your need). Cn reads the PATH_TRANSLATED environment variable to determine where to look for the files and what the filename prefix is.
For example, suppose you have three different versions of the same HTML document: one standard document, one text-only document, and one that supports Mozilla/Microsoft extensions. The three filenames and locations are
/index.html
/index.thtml
/index.mhtml
In order to tell cn to send one of these three files according to browser type, you reference cn as follows:
<a href="/cgi-bin/cn/index">Go to Index</a>
Assume your document root is /usr/local/etc/httpd/htdocs/. When you click on the preceding link, you run cn with PATH_TRANSLATED /usr/local/etc/httpd/htdocs/index. Cn first checks the HTTP_ACCEPT variable to see if you have a text-only browser; if you do, it tries to send index.thtml. If you have a graphical browser, cn checks to see if you have either Netscape or Internet Explorer running. If you do, it tries to send index.mhtml. If cn can't find either index.thtml or index.mhtml, or if the browser is a non-Netscape/Microsoft graphical browser, cn tries to send index.html. If cn cannot find cn, it sends a File Not Found error message (status code 404).
The following section summarizes the algorithm:
The complete source code for cn is in Listing 10.1.
Listing 10.1. The cn source code.
#!/usr/local/bin/perl
# store environment variables in local variables
$PATH_INFO = $ENV{'PATH_INFO'};
$PATH_TRANSLATED = $ENV{'PATH_TRANSLATED'};
$HTTP_ACCEPT = $ENV{'HTTP_ACCEPT'};
$HTTP_USER_AGENT = $ENV{'HTTP_USER_AGENT'};
$SENT = 0;
if ($PATH_TRANSLATED) {
if ($HTTP_ACCEPT =~ /image/) {
if ( ($HTTP_USER_AGENT =~ /Mozilla/) ||
($HTTP_USER_AGENT =~ /Microsoft/) ) {
if (-e "$PATH_TRANSLATED.mhtml") {
&send_contents("$PATH_TRANSLATED.mhtml");
$SENT = 1;
}
}
}
else { # text-only browser
if (-e "$PATH_TRANSLATED.thtml") {
&send_contents("$PATH_TRANSLATED.thtml");
$SENT = 1;
}
}
if ($SENT == 0) {
if (-e "$PATH_TRANSLATED.html") {
&send_contents("$PATH_TRANSLATED.html");
}
else {
print <<EOM;
Status: 404 File Not Found
Content-Type: text/html
<html> <head>
<title>File Not Found</title>
</head>
<body>
<h1>File Not Found</h1>
<p>Could not find the file (Error 404).</p>
</body> </html>
EOM
}
}
}
else {
print <<EOM;
Status: 403 Forbidden File
Content-Type: text/html
<html> <head>
<title>Forbidden File</title>
</head>
<body>
<h1>Forbidden File</h1>
<p>Could not open file (Error 403).</p>
</body> </html>
EOM
}
sub send_contents {
local($filename) = @_;
print "Content-Type: text/html\n\n";
open(FILE,$filename); # or error
while (<FILE>) {
print;
}
}
The Perl code for cn is about as straightforward as source code gets. All input was from environment variables. No parsing was necessary, so no external programming libraries such as cgi-lib.pl are needed. In order to send the appropriate HTML files, you could use the Location header rather than open the file. Opening the files yourself, however, enables you to check for the existence of files and then look for other files if the ones you wanted didn't already exist. Sending a Location header would have been inefficient because the server would have parsed the header and then once again checked to see whether the file existed or not, something cn had already determined.
Redirection operates similar to telephone call forwarding. With call forwarding, you dial a certain phone number that consequently dials and connects you to another phone number.
If you restructure your Web site and move files around, you might want to specify a redirect for a file at its old location to its new location. For example, if the file mom.html moved from your document root to the directory /parents, you might want to redirect the request from the following:
http://myserver.org/mom.html
to:
http://myserver.org/parents/mom.html
A few options exist for you to handle this problem. You could create the file /mom.html with the following message:
<html> <head>
<title>Mom Moved</title>
</head>
<body>
<h1>Mom Moved</h1>
<p>Mom moved <a href="/parents/mom.html">here</a>.</p>
</body> </html>
Although this idea provides an adequate solution, it requires
more maintenance and is not really the proper way to handle a
redirect. To properly handle a redirect, you send a redirect status
code (see Table 10.1; a complete list is available in Chapter 8,
"Client/Server Issues") and let the browser determine
how to properly retrieve the file at its new location.
| 301 | Moved Permanently | The page is now located at a new URI, specified by the Location header. |
| 302 | Moved Temporarily | The page is temporarily located at a new URI, specified by the Location header. |
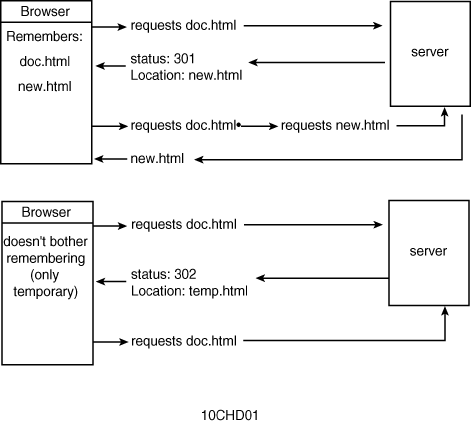
When the browser receives a status code of 301 (Moved Permanently), it redirects all subsequent requests at the old URL to the new location. For example, if you request
http://myserver.org/mom.html
and receive a status code of 301 and the new location:
http://myserver.org/parents/mom.html
it will redirect the request to the latter location. The next time you try to access the first URL, the browser doesn't bother trying the old URL again; it instead directly accesses the new URL.
Upon receipt of status code 302 (Moved Temporarily), the browser redirects only that one specific request; upon subsequent requests, it tries the original URL again. For example, suppose you request the following again:
http://myserver.org/mom.html
This time you receive a status code of 302 along with the new location:
http://myserver.org/parents/mom.html
It once again redirects your request to the latter location, but
the next time you try to access the first URL, it once again tries
to access the URL. Figure 10.1 summarizes
the different browser procedures for the two different redirect
status codes.
Instead of creating a new HTML document that routes to the new URL, you send a status code and Location header to properly redirect a request. You can accomplish this task in two ways. You can configure many servers to redirect specific URLs. Although this has the advantage of very low overhead, your redirect options are limited. Some servers might only enable the Web administrator to configure redirections. Other servers might have limited configurability. For example, you cannot configure the NCSA server to send a status code of 301 instead of 302 with its Redirect feature.
| Tip |
To establish redirection using the NCSA server or a derivative (like Apache), edit the conf/srm.conf file and add the following line: Redirect fakename newURL where fakename is the name of the file you want to redirect relative to your document root and newURL is the new location. The latter must be a complete URL, not just a filename relative to document root. For example: Redirect /mom.html http://myserver.org/parents/mom.html temporarily redirects (using status code 302) all requests for http://myserver.org/mom.html to: http://myserver.org/parents/mom.html Note that the following is not a legal Redirect request because the last parameter must be a proper URL: Redirect /mom.html /parents/mom.html |
The second way to accomplish a redirect is with a CGI program. Although this method is less efficient than having the server directly process the redirect request, a CGI program offers more flexibility. For example, you can write your CGI program so that users can configure their own redirections.
Businesses that provide advertising space on their Web sites can
use a redirection script to log every time someone clicks on an
advertisement to go to another site. For example, suppose you
have an advertisement for Mom and Pop's Candy Store (as depicted
in Figure 10.2). If you click on the
advertisement, you go to Mom and Pop's Web site. Normally, the
HTML document for such an advertisement might look something like
Listing 10.2.
Figure 10.2 : Advertisements for Mom and Pop's Candy Store.
Listing 10.2. advertisement.html.
<html> <head>
<title>Front Page News</title>
</head>
<body>
<h1>Today's Headlines</h1>
<dl>
<dt><b>Harvard Beats Yale!</b>
<dd>In yesterday's football game, Harvard crushed Yale 64-3.
The key play of the game was one Crimson linebacker Elbert
Baquero sacked Bulldog quarterback Tony "the Tornado"
with a minute and a half to play.
<dt><b>Gates Steps Down!</b>
<dd>In a move that shocked the software world, William Gates, III
retired as CEO of Microsoft, stating "I want to kick back and
enjoy my cash with my family." The Board of Directors appointed
Matt Howitt to succeed him.
</dl>
<hr>
<a href="http://www.mnpcandy.com/">
<img src="ad.gif" alt="Go to Mom and Pop's Candy Store's Web Site!">
</a>
<hr>
</body> </html>
Now it's time for you to collect your revenues from the candy store and attempt to renew your contract. Unfortunately, with the Web page in Listing 10.2, you have no way of knowing how many times people actually clicked on the advertisement to go to Mom and Pop's Web site.
| Note |
Although you might have no way of determining how many times people went from your Web site to the candy store's site, the candy store can usually determine this information. Many servers enable you to log the referring pages, provided the browser supplies this information. Unfortunately, not all browsers do supply this information. Besides, you might not want to rely on your customer's Reference logs for that information. The best way to record this information is to use a logging redirection script. |
If you had a program that updated an access file every time someone clicked on that link, and then redirected the person to the new site, you could keep track of how many people visited the site because of the advertisement on your Web page.
The following list provides some specifications for a redirection manager:
This procedure is called CGI program redirect. You can use redirect in two ways. You can either access the redirect program directly, passing its instructions through QUERY_STRING, or you can have your server call redirect every time it cannot find a document.
For example, consider the preceding scenario. You want to log all accesses to Mom and Pop's Web site from the advertisement on your page. Instead of just specifying the URL in the <a href> tag, you could use redirect:
<a href="/cgi-bin/redirect?url=http://www.mnpcandy.
Âcom/&log=/var/logs/redirect.log">
<img src="ad.gif" alt="Go to Mom and Pop's Candy Store's Web Site!">
</a>
Now, every time someone clicks on this advertisement, redirect
would log the request to the
/var/logs/redirect.log file
and would redirect that person to the Candy Store Web site.
To enable users to specify their own redirections without having access to any global configuration file, you need to configure your server to run the redirect program every time it cannot find a file. (See the following note for instructions on how to do this for the NCSA server.)
| Note |
By default, when you try to access a page that doesn't exist on a server, the server sends a Status: 404 header with an accompanying error message. Some servers, including NCSA, enable you to send a customized error message or to run a CGI program in place of the standard response. To specify an alternative HTML error message or CGI error handler, edit the conf/srm.conf file and add the following line: ErrorDocument 404 /alternate.html where alternate.html is your customized error message. If you want to specify the program /cgi-bin/redirect as your error handler, add the following line: ErrorDocument 404 /cgi-bin/redirect The server sends three new environment variables to CGI error handlers: REDIRECT_REQUEST, REDIRECT_URL, and REDIRECT_STATUS. REDIRECT_REQUEST contains the complete browser request, REDIRECT_URL contains the URL the browser tried to access, and REDIRECT_STATUS contains the status code the server wants to return. |
If the server cannot find a file, it will run the redirect program, which searches for a configuration file (.redirect) in the appropriate directory. The configuration file looks something like this:
LOGFILE=/var/logs/redirect.log
STATUS=302
/index.html http://myserver.org/parents/index.html
/mom.html /parents/mom.html 301
LOGFILE specifies where to log requests. If this line is absent, then redirect will not log requests. STATUS contains the default status code for redirection. If STATUS is not specified, redirect assumes a status code of 302 (temporarily moved). Finally, the redirect command follows this form:
document newlocation status
Document is the old document relative to the document root, and newlocation contains the new location of the file. Note that unlike the Redirect option for NCSA servers, newlocation does not have to be a URL. Status is optional; if you include it, it will use that status code.
It is time to begin coding. Figure 10.3 is a flowchart describing the program design. Two parts exist: one that handles redirects if called by the server, and the other that handles redirects specified in QUERY_STRING.
Begin with the easier of the two tasks: the Perl code that will handle redirects if given some CGI input. The task is simple:
The code for this task is in Listing 10.3. The CGI input and output is straightforward. The ReadParse function parses the input. If no URL is specified, redirect sends an error message. If a log file is specified, redirect tries to append to the log file. If it can't append to the log file, it sends an error. If no errors occur, redirect sends a Status and Location header along with some HTML in case the browser does not properly handle redirects.
Listing 10.3. Handling redirects specified in QUERY_STRING.
require 'cgi-lib.pl';
# reads and parses input
&ReadParse(*input);
$logfile = $input{'log'} unless !($input{'log'});
$url = $input{'url'} unless !($input{'url'});
if (!$url) {
&CgiDie("No URL Specified");
}
if ($logfile) {
# try to open and append to $LOGFILE
# if that doesn't work, append to $DEFAULT_LOGFILE
# if that doesn't work, send an error message
open(LOG,">>$logfile") || &CgiDie("Can't Append to Logfile: $logfile");
print LOG "$url\n";
close(LOG);
}
# prints forwarding output in HTML to the user
print "Status: 302 Forwarding to Another URL\n";
print "Location: $url\n\n";
print &HtmlTop("Web Forwarding");
print "<p>Go to: <a href=\"$url\">$url</a></p>\n";
print &HtmlBot;
Now the second part of the program is added: user configurable redirections. The steps are as follows:
Look at the second step for a moment. After you have the REDIRECT_URL, you need to determine where the directory is located. REDIRECT_URL tells you a relative directory in one of two forms:
/somedir/file.html
/~username/somedir/file.html
You need to translate either of these two cases into the appropriate, full pathname. Translating the first case is fairly simple. Append the value of REDIRECT_URL to the value of the DOCUMENT_ROOT environment variable, and then remove the filename. If your document root were /usr/local/etc/httpd/, then
/somedir/file.html
would translate to
/usr/local/etc/httpd/somedir/
The second possibility presents more of a challenge. You need to extract the username, determine where the user's home directory is, append the name of the public HTML directory to this home directory, and then append the rest of the directories. For example, if your home directory was in /home/username and the public HTML directory was in public_html, then
/~username/somedir/file.html
would translate into
/home/username/public_html/somedir/
You can use the getpwnam() function to determine the home directory of the user. A CGI program cannot determine the name of the public HTML directory, so you can make that a user configurable item. The code to extract the directory from REDIRECT_URL is in Listing 10.4.
Listing 10.4. Extracting directory information from REDIRECT_URL.
$public_html = '/public_html';
$config = '.redirect';
if ($redirect_url = $ENV{'REDIRECT_URL'}) {
$request = $redirect_url;
$server_prefix = "http://$ENV{'SERVER_NAME'}:$ENV{'SERVER_PORT'}";
if ($redirect_url =~ /^\/\~/) {
$redirect_url =~ s/^\/\~//;
if ( ($end = index($redirect_url,'/')) < $[ ) {
$end = $];
}
$username = substr($redirect_url,0,$end);
$prefix = &return_homedir($username);
if (!$prefix) {
&CgiDie("Invalid Directory");
}
$start = index($redirect_url,'/');
$end = rindex($redirect_url,'/')+1;
$suffix = $public_html.substr($redirect_url,$start,$end - $start);
}
else {
$prefix = $ENV{'DOCUMENT_ROOT'};
$suffix = substr($redirect_url,0,rindex($redirect_url,'/')+1);
}
$config_loc = $prefix.$suffix.$config;
}
Now that you know where to look for a configuration file, you must open and parse that file. If it doesn't exist, then you just send a regular File not found error message (status code 404). If it does exist, parse it for the options listed earlier. The code for opening and parsing the file is in Listing 10.5. Listing 10.6 contains the function not_found, which sends the appropriate 404 error message.
Listing 10.5. Parsing the configuration file.
if (-e $config_loc) {
open(CONFIG,$config_loc) || &CgiDie("Can't Open Config File");
$FOUND = 0;
while ($line = <CONFIG>) {
$line =~ s/[\r\n]//;
if ($line =~ /^LOG=/) {
($logfile = $line) =~ s/^LOG=//;
}
elsif ($line =~ /^STATUS=30[12]/) {
($status = $line) =~ s/^STATUS=//;
}
else {
($old,$new,$this_status) = split(/ /,$line);
if ($old eq $request) {
if (!$new) {
&CgiDie("No New URL Specified");
}
if (!($new =~ /^http:\/\//)) {
$new = $server_prefix.$new;
}
$FOUND = 1;
if ($logfile) {
open(LOG,">>$logfile") ||
&CgiDie("Can't Append to Logfile:
$logfile");
print LOG "$new\n";
close(LOG);
}
$status = $this_status unless (!$this_status);
$status = 302 unless ($status);
if ( ($status != 301) || ($status != 302) ) {
$status = 302;
}
print "Status: $status\n";
print "Location: $new\n\n";
print &HtmlTop("Request Redirected");
print "<p>Request redirected to:\n";
print "<a href=\"$new\">$new</a></p>\n";
print &HtmlBot;
}
}
}
close(CONFIG);
if (!$FOUND) {
¬_found($request);
}
}
else {
¬_found($request);
}
Listing 10.6. List for File Not Found.
sub not_found {
local($request) = @_;
print "Status: 404 File Not Found\n";
print &PrintHeader,&HtmlTop("File Not Found");
print <<EOM;
print "<p>Error 404: $request could not be found on this server.</p>\n";
print &HtmlBot;
}
You can now put together all of the code into one full-fledged application-redirect-listed in Listing 10.7.
Listing 10.7. Redirect-the finished application.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
$public_html = '/public_html';
$config = '.redirect';
if ($redirect_url = $ENV{'REDIRECT_URL'}) {
$request = $redirect_url;
$server_prefix = "http://$ENV{'SERVER_NAME'}:$ENV{'SERVER_PORT'}";
if ($redirect_url =~ /^\/\~/) {
$redirect_url =~ s/^\/\~//;
if ( ($end = index($redirect_url,'/')) < $[ ) {
$end = $];
}
$username = substr($redirect_url,0,$end);
$prefix = &return_homedir($username);
if (!$prefix) {
&CgiDie("Invalid Directory");
}
$start = index($redirect_url,'/');
$end = rindex($redirect_url,'/')+1;
$suffix = $public_html.substr($redirect_url,$start,$end - $start);
}
else {
$prefix = $ENV{'DOCUMENT_ROOT'};
$suffix = substr($redirect_url,0,rindex($redirect_url,'/')+1);
}
$config_loc = $prefix.$suffix.$config;
if (-e $config_loc) {
open(CONFIG,$config_loc) || &CgiDie("Can't Open Config File");
$FOUND = 0;
while ($line = <CONFIG>) {
$line =~ s/[\r\n]//;
if ($line =~ /^LOG=/) {
($logfile = $line) =~ s/^LOG=//;
}
elsif ($line =~ /^STATUS=30[12]/) {
($status = $line) =~ s/^STATUS=//;
}
else {
($old,$new,$this_status) = split(/ /,$line);
if ($old eq $request) {
if (!$new) {
&CgiDie("No New URL Specified");
}
if (!($new =~ /^http:\/\//)) {
$new = $server_prefix.$new;
}
$FOUND = 1;
if ($logfile) {
open(LOG,">>$logfile") ||
&CgiDie("Can't Append to Logfile: $logfile");
print LOG "$new\n";
close(LOG);
}
$status = $this_status unless (!$this_status);
$status = 302 unless ($status);
if ( ($status != 301) || ($status != 302) ) {
$status = 302;
}
print "Status: $status\n";
print "Location: $new\n\n";
print &HtmlTop("Request Redirected");
print "<p>Request redirected to:\n";
print "<a href=\"$new\">$new</a></p>\n";
print &HtmlBot;
}
}
}
close(CONFIG);
if (!$FOUND) {
¬_found($request);
}
}
else {
¬_found($request);
}
}
else {
&ReadParse(*input);
$logfile = $input{'log'} unless !($input{'log'});
$url = $input{'url'} unless !($input{'url'});
if (!$url) {
&CgiDie("No URL Specified");
}
if ($logfile) {
# try to open and append to $LOGFILE
# if that doesn't work, append to $DEFAULT_LOGFILE
# if that doesn't work, send an error message
open(LOG,">>$logfile")
|| &CgiDie("Can't Append to Logfile: $logfile");
print LOG "$url\n";
close(LOG);
}
print "Status: 302 Forwarding to Another URL\n";
print "Location: $url\n\n";
print &HtmlTop("Web Forwarding");
print "<p>Go to: <a href=\"$url\">$url</a></p>\n";
print &HtmlBot;
}
sub return_homedir {
local($username) = @_;
local($name,$passwd,$uid,$gif,$quota,$comment,$gcos,$dir,$shell) =
getpwnam($username);
return $dir;
}
sub not_found {
local($request) = @_;
print "Status: 404 File Not Found\n";
print &PrintHeader,&HtmlTop("File Not Found");
print <<EOM;
print "<p>Error 404: $request could not be found on this server.</p>\n";
print &HtmlBot;
}
The majority of redirect's source code is dedicated to determining where the configuration file is located and to parsing the file. Determining where the configuration file is located depends on your ability to manipulate the appropriate server variables. As usual, the CGI input and output routines seem almost trivial in this program; the real substance lies in determining how to take advantage of the environment variables and of parsing configuration files.
One of CGI's most important contributions to the World Wide Web is its capability to collect input from the user. Although many CGI programs depend on this input to determine what to send back (for example, a search front-end to a database), perhaps the most basic use of CGI is to simply collect the information from the user and store it somewhere for the provider to look at later.
You see these types of applications all over the Web, ranging from forms soliciting comments to online voting booths to guestbooks. You can reduce all of these applications to these steps:
Instead of writing a separate application every time you need to collect data, you can write one generic forms parser that performs the preceding three steps. Such an application is developed here, starting with the most basic type of program and later extending it so that any user can easily configure it. Chapter 11, "Gateways," extends the program further so that it e-mails the results rather than store the information on disk.
| Tip |
With many browsers, you don't even need a CGI application to act as a generic form parser. If you specify a mailto: reference in the action parameter of the form tag, when the user submits the form, the encoded input will be e-mailed to the person specified in the action parameter. For example, the following form will encode your input and e-mail it to eekim@hcs.harvard.edu: You can then parse and process the contents of your e-mail. |
This section is a very specific application. You are conducting a poll over a controversial topic, and you want to collect people's choices and their ages and store these results in a comma-delimited file. Because the application is so specific, I hard code the form into the CGI application. The completed program in both Perl and C are in Listings 10.8 and 10.9.
Listing 10.8. The poll.cgi program (in Perl).
#!/usr/local/bin/perl
require 'cgi-lib.pl';
$file = '/home/poll/results.txt';
if (&ReadParse(*input)) {
open(FILE,">>$file") || &CgiDie("Can't Append to $file");
print FILE "$input{'cola'},$input{'age'}\n";
close(FILE);
print &PrintHeader,&HtmlTop("Thanks!");
print "<p>Thanks for filling out the poll!</p>\n";
print &HtmlBot;
}
else {
print &PrintHeader,&HtmlTop("Poll");
print <<EOM;
<form method=POST>
<p>Which is better?</p>
<ul>
<li><input type=radio name="cola" value="coke" checked>Coke
<li><input type=radio name="cola" value="pepsi">Pepsi
</ul>
<p>How old are you? <input type=text name="age"></p>
<input type=submit>
</form>
EOM
print &HtmlBot;
}
Listing 10.9. The poll.cgi program (in C).
#include <stdio.h>
#include "cgi-lib.h"
#include "html-lib.h"
#define OUTPUT "/home/poll/results.txt"
int main()
{
llist entries;
FILE *output;
html_header();
if (read_cgi_input(&entries)) {
if ( (output = fopen(OUTPUT,"a")) == NULL) {
html_begin("Can't Append to File");
h1("Can't Append to File");
html_end();
exit(1);
}
fprintf(output,"%s,%s",cgi_val(entries,"cola"),cgi_val(entries,"age"));
fclose(output);
html_begin("Thanks!");
h1("Thanks!");
printf("<p>Thanks for filling out the poll!</p>\n");
html_end();
}
else {
html_begin("Poll");
h1("Poll");
printf("<form method=POST>\n");
printf("<p>Which is better?</p>\n");
printf("<ul>\n");
printf(" <li><input type=radio name=\"cola\
Â" value=\"coke\" checked>Coke\n");
printf(" <li><input type=radio name=\"cola\" value=\"pepsi\">Pepsi\n");
printf("</ul>\n");
printf("<p>How old are you? <input type=text name=\"age\"></p>\n");
printf("<input type=submit>\n");
printf("</form>\n);
html_end();
}
list_clear(&entries);
}
| Note |
Appending to a file is normally an atomic operation, meaning it is a sequence of operations that must finish uninterrupted, so you don't have to worry about file locking. |
Both the Perl and C versions of poll.cgi consist mostly of printing the appropriate HTML. Obtaining and parsing the input is one line of code in both versions.
In Perl:
if (&ReadParse(*input)) { … }
In C:
if (read_cgi_input(&entries)) { … }
Appending the results to a file is three lines.
In Perl:
open(FILE,">>$file") || &CgiDie("Can't Append to $file");
print FILE "$input{'cola'},$input{'age'}\n";
close(FILE);
In C:
if ( (output = fopen(OUTPUT,"a")) == NULL) { … }
fprintf(output,"%s,%s",cgi_val(entries,"cola"),cgi_val(entries,"age"));
fclose(output);
You could easily create this kind of program any time you need one.
You want to avoid this kind of effort, however. Instead of having a separate program for each task, you want one program that parses input and saves it to a file. In order to achieve this result using poll.cgi as the basis for your code, you need to do the following:
To achieve the second step, allow the user to specify the filename and location via the PATH_INFO variable. The Perl and C source code for our simple but general forms parser are in Listings 10.10 and 10.11, respectively.
Listing 10.10. The parse-form program (in Perl).
#!/usr/local/bin/perl
require 'cgi-lib.pl';
$file = $ENV{'PATH_INFO'};
if (!$file) {
&CgiDie("No output file specified");
}
&ReadParse(*input);
open(FILE,">>$file") || &CgiDie("Can't Append to $file");
foreach $name (keys(%in)) {
foreach (split("\0", $in{$name})) {
($value = $_) =~ s/\n/<br>\n/g;
# since it's comma delimited, escape commas by
# preceding them with slashes; must also escape slashes
$value =~ s/,/\\,/;
$value =~ s/\\/\\\\/;
print FILE "$value,\n";
}
}
close(FILE);
print &PrintHeader,&HtmlTop("Form Submitted");
print &HtmlBot;
Listing 10.11. The parse-form program (in C).
#include <stdio.h>
#include <stdlib.h>
#include "cgi-lib.h"
#include "html-lib.h"
char *escape_commas(char *str)
{
int i,j = 0;
char *new = malloc(sizeof(char) * (strlen(str) * 2 + 1));
for (i = 0; i < strlen(str); i++) {
if ( (str[i] == ',') || (str[i] == '\') ) {
new[j] = '\';
j++;
}
new[j] = str[i];
j++;
}
new[j] = '\0';
return new;
}
int main()
{
llist entries;
node *window;
FILE *output;
html_header();
if (PATH_INFO == NULL) { /* remember, cgi-lib.h defines PATH_INFO */
html_begin("No output file specified");
h1("No output file specified");
html_end();
exit(1);
}
read_cgi_input(&entries);
if ( (output = fopen(PATH_INFO,"a")) == NULL) {
html_begin("Can't Append to File");
h1("Can't Append to File");
html_end();
exit(1);
}
window = entries.head;
while (window != NULL) {
fprintf(output,"%s,",escape_commas((*window).entry.value));
}
fclose(output);
html_begin("Form Submitted");
h1("Form Submitted");
html_end();
list_clear(&entries);
}
To use parse-form, include it in the action parameter of your HTML form with the full pathname of the output file. For example, the following will save the results of the form, comma-delimited, in the /var/adm/results.txt file:
<form action="/cgi-bin/parse-form/var/adm/results.txt">
The code is smaller, even though the program is more general because the built-in form has been removed. Even in its new, more general form, however, parse-form is still not quite satisfactory. First, the confirmation message is fairly unhelpful and ugly. You might want to send a custom message for each type of form.
Second, the output file is somewhat unhelpful. The point of parsing the data before saving it to a file is to simplify the parsing. For example, with poll.cgi, it's easier to parse a file like the following:
coke,15
pepsi,21
pepsi,10 than one like:
cola=coke&age=15
cola=pepsi&age=21
cola=pepsi&age=10
Here, because you know the variables, you can assume that you won't have any commas in the response, for example. You can make no such assumption in general, though. What if you had a form that asked for comments? People might use commas when they fill out their comments. You need to escape these commas so that a clear distinction exists between the delimiter and actual commas. If your data is very complex, then a comma-delimited file might not be easier to parse than a CGI-encoded one.
Form.cgi solves the other parsers' problems. Form.cgi reads a configuration file (either defined by PATH_INFO or the predefined default) and does the following:
Because form.cgi requires some amount of text processing and because this text focuses on the algorithm rather than the programming implementation, form.cgi is written in Perl. You might already have Perl code for reading and parsing a configuration file from the redirection manager. This code has been adapted to read a configuration file that looks like the following:
FORM=/form.html
TEMPLATE=/usr/local/etc/httpd/conf/template
OUTPUT=/usr/local/etc/httpd/conf/output
RESPONSE=/thanks.html
FORM and RESPONSE define HTML documents relative to the document root. The TEMPLATE and OUTPUT variables contain full pathnames to the template. If you do not define it in the configuration file, then form.cgi sends the same response as parse-form. The code for parsing the configuration file appears in Listing 10.12. This code will ignore any other line not in the specified form.
Listing 10.12. Parsing the configuration file.
$global_config = '/usr/local/etc/httpd/conf/form.conf';
# parse config file
$config = $ENV{'PATH_INFO'};
if (!$config) {
$config = $global_config;
}
open(CONFIG,$config) || &CgiDie("Could not open config file");
while ($line = <CONFIG>) {
$line =~ s/[\r\n]//;
if ($line =~ /^FORM=/) {
($form = $line) =~ s/^FORM=//;
}
elsif ($line =~ /^TEMPLATE=/) {
($template = $line) =~ s/^TEMPLATE=//;
}
elsif ($line =~ /^OUTPUT=/) {
($output = $line) =~ s/^OUTPUT=//;
}
elsif ($line =~ /^RESPONSE=/) {
($response = $line) =~ s/^RESPONSE=//;
}
}
close(CONFIG);
The template file tells form.cgi the format of the output file. In order to specify the form values, you precede the field name with a dollar sign ($). For example, the template for a comma-delimited output file for the cola poll would look like the following:
$cola,$age
The input name must be only one word and consist entirely of alphanumeric characters. This example also has the capability to write the values of CGI environment variables to the file. To add this capability, you specify the environment variable name preceded by a percent symbol (%). For example, if you want to label each line of your cola poll's output file with the name of the machine where the browser resides, you would use the template file:
%REMOTE_HOST $cola,$age
If you want to just print a dollar sign or percent symbol, precede the symbol with a backslash (/). In order to print a backslash, precede the backslash with a backslash to print two backslashes (//).
How do you implement this? After you have read and parsed the form input, you need to read the template file and parse each line, replacing any variables with the appropriate form values. The code for this process appears in Listing 10.13.
Listing 10.13. Use template to define output file format.
# read template into list
if ($template) {
open(TMPL,$template) || &CgiDie("Can't Open Template");
@TEMPLATE = <TMPL>;
close(TMPL);
}
else {
&CgiDie("No template specified");
}
# write to output file according to template
if ($output) {
open(OUTPUT,">>$output") || &CgiDie("Can't Append to $output");
foreach $line (@TEMPLATE) {
if ( ($line =~ /\$/) || ($line =~ /\%/) ) {
# form variables
$line =~ s/^\$(\w+)/$input{$1}/;
$line =~ s/([^\\])\$(\w+)/$1$input{$2}/g;
# environment variables
$line =~ s/^\%(\w+)/$ENV{$1}/;
$line =~ s/([^\\])\%(\w+)/$1$ENV{$2}/g;
}
print OUTPUT $line;
}
close(OUTPUT);
}
else {
&CgiDie("No output file specified");
}
Putting all of the code together results in form.cgi as listed in Listing 10.14. Form.cgi seems to overcome all of the shortcomings of the previous attempts at a general, generic form parser. It serves as a customizable, robust application that will probably save you a great deal of time.
Listing 10.14. The form.cgi program.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
$global_config = '/usr/local/etc/httpd/conf/form.conf';
# parse config file
$config = $ENV{'PATH_INFO'};
if (!$config) {
$config = $global_config;
}
open(CONFIG,$config) || &CgiDie("Could not open config file");
while ($line = <CONFIG>) {
$line =~ s/[\r\n]//;
if ($line =~ /^FORM=/) {
($form = $line) =~ s/^FORM=//;
}
elsif ($line =~ /^TEMPLATE=/) {
($template = $line) =~ s/^TEMPLATE=//;
}
elsif ($line =~ /^OUTPUT=/) {
($output = $line) =~ s/^OUTPUT=//;
}
elsif ($line =~ /^RESPONSE=/) {
($response = $line) =~ s/^RESPONSE=//;
}
}
close(CONFIG);
# process input or send form
if (&ReadParse(*input)) {
# read template into list
if ($template) {
open(TMPL,$template) || &CgiDie("Can't Open Template");
@TEMPLATE = <TMPL>;
close(TMPL);
}
else {
&CgiDie("No template specified");
}
# write to output file according to template
if ($output) {
open(OUTPUT,">>$output") || &CgiDie("Can't Append to $output");
foreach $line (@TEMPLATE) {
if ( ($line =~ /\$/) || ($line =~ /\%/) ) {
# form variables
$line =~ s/^\$(\w+)/$input{$1}/;
$line =~ s/([^\\])\$(\w+)/$1$input{$2}/g;
# environment variables
$line =~ s/^\%(\w+)/$ENV{$1}/;
$line =~ s/([^\\])\%(\w+)/$1$ENV{$2}/g;
}
print OUTPUT $line;
}
close(OUTPUT);
}
else {
&CgiDie("No output file specified");
}
# send either specified response or dull response
if ($response) {
print "Location: $response\n\n";
}
else {
print &PrintHeader,&HtmlTop("Form Submitted");
print &HtmlBot;
}
}
elsif ($form) {
# send default form
print "Location: $form\n\n";
}
else {
&CgiDie("No default form specified");
}
You can use form.cgi as a very primitive guestbook. To do so, you need to create a configuration file, a form and a response HTML file, and a template file that describes the format of the guestbook.
Assume the following specifications:
Listing 10.15. The add.html program.
<html><head>
<title>Add Entry</title>
</head>
<body>
<h1>Add Entry</h1>
<hr>
<form action="/cgi-bin/form.cgi/usr/local/etc/httpd/conf/guestbook.conf">
<p>Name: <input name="name"><br>
Email: <input name="email"><br>
URL: <input name="url"></p>
<p>
<textarea name="message" rows=10 cols=70>
</textarea>
</p>
<input type=submit value="Sign Guestbook">
</form>
<hr>
</body></html>
Listing 10.16. The thanks.html program.
<html><head>
<title>Thanks!</title>
</head>
<body>
<h1>Thanks!</h1>
<p>Thanks for submitting your entry! You can
<a href="/guestbook.html">look at the guestbook.</a></p>
</body></html>
Listing 10.17. The guestbook.conf program.
FORM=/add.html
RESPONSE=/thanks.html
TEMPLATE=/usr/local/etc/httpd/conf/guestbook.template
OUTPUT=/usr/local/etc/httpd/htdocs/guestbook.html
Listing 10.18. The guestbook.template program.
<p><b>From <a href="$url">$name</a> <a href="mailto:$email">$email</a></p>
<pre>$message</pre>
<hr>
By creating the text files in Listings 10.15 through 18, you have created a guestbook without one extra line of CGI programming. Remember, however, that you have a very rudimentary guestbook, lacking features such as date-stamping and filtering greater than (>) and less than (<) symbols. The guestbook examples in Chapter 5, "Input," and Chapter 6, "Programming Strategies," are superior to this primitive example. Regardless, form.cgi can save the CGI developer a great deal of time.
The examples in this chapter were minimalistic as far as CGI programs go. The complexity came in manipulating CGI environment variables, in parsing input, and in sending output. All other routines either read and wrote data to a file, or they manipulated text.
The applications in this chapter-the content negotiator, the redirection manager, and the form parser-as well as the techniques applied, are enough to cover the majority of CGI programs that most people will ever need to write. The remainder of this book focuses on more specialized, advanced applications.