When developing a new application, there are various hurdles developers need to overcome. You have to get your application to compile, to run without blowing up, and you have to be sure that it does what you want it to do. On some projects, there is time to determine if your application can run faster, use less memory, or if you can have a smaller executable file. The performance improvement techniques discussed in this chapter can prevent your program from blowing up, and prevent the kind of ìthinkosî that result in a program calculating or reporting the wrong numbers. These improvements are not just final tweaks and touch-ups on a finished product.
You should get in the habit of adding ìan ounce of preventionî to your code as you write, and of using the debugging capabilities provided to you by Developer Studio to be sure of whatís going on in your program. If you save all your testing to the end, both the testing and the bug-fixing will be much harder than if you had been testing all along. And, of course, any bug you manage to prevent will never have to be fixed at all!
Assertions prevent trouble, and trace statements show you whatís going on. These macros belong in every program.
When your application allocates memory but never frees it, you have a memory leak. See what causes them, how to find them, and how to eliminate them.
You can produce faster or smaller code today, simply by asking the compiler to optimize for you. Learn what options are available and how to make your decision.
Too many programmers sweat bullets trying to speed up code that is rarely called, while ignoring slow code that is causing a bottleneck. Profiling shows you where to spend your energy.
The concepts of asserting and tracing were not invented by the developers of Visual C++. Other languages support these ideas, and they are taught in many computer science courses. What is exciting about the Visual C++ implementation of these concepts is the clear way in which your results are presented, and the ease with which you can suppress assertions and trace statements in release versions of your application.
ASSERT: Detecting Logic Errors
The ASSERT macro allows you to check a condition that you logically believe should always be true. For example, imagine you are about to access an array like this:
array[i] = 5;
You want to be sure that the index, i, is not less than zero and is not larger than the number of elements allocated for the array. Presumably you have already written code to calculate i, and if that code has been written properly, i must be between 0 and the array size. An ASSERT statement will verify that:
ASSERT( i > 0 && i < ARRAYSIZE)
There is no semicolon (;) at the end of the line because ASSERT is a macro, not a function. Older C programs may call a function named assert(), but you should replace these calls with the ASSERT macro, because ASSERT disappears during a release build, as discussed later in this section.

ASSERT statements are ways for you to check your own logic. They should never be used to check for user input errors or bad data in a file. Whenever the condition inside an ASSERT statement is false, program execution halts with a message telling you which assertion failed. At this point, you know you have a logic error, or a developer error, that you need to correct. Hereís another example:
// Calling code must pass a non-null pointer
void ProcessObject( Foo * fooObject )
{
ASSERT( fooObject )
// process object
}
This code can de-reference the pointer in confidence, knowing execution will be halted if the pointer is null.
You probably already know that Developer Studio makes it simple to build debug and release versions of your programs. The Debug version #defines a constant, _DEBUG, and macros and other pre-processor code can check this constant to determine the build type. When _DEBUG is not defined, the ASSERT macro does nothing. This means there is no speed constraint in the final code as there would be if you added if statements yourself to test for logic errors. There is no need for you to go through your code removing ASSERT statements when you release your application, and in fact itís better to leave them there to help the developers who work on version 2. In addition, ASSERT cannot help you if there is a problem with the release version of your code because it is used to find logic and design errors before you release version 1.0 of your product.
TRACE: Isolating Problems Areas in Your Program
As discussed in Reference Chapter C, ìDebugging,î the power of the Developer Studio debugger is considerable. You can step through your code one line at a time, or run to a breakpoint, and you can see the values of any of your variables in watch windows as you move through the code. This can be slow, however, and many developers use TRACE statements as a way of speeding up this process and zeroing in on the problem area. Then they turn to more traditional step-by-step debugging to isolate the bad code.
In the old days, isolating bad code meant adding lots of print statements to your program, which is problematic in a Windows application. So before you start to think up workarounds, like printing to a file, relax, because the TRACE macro does everything you want. And like ASSERT, it magically goes away in release builds.
There are actually several TRACE macros: TRACE, TRACE0, TRACE1, TRACE2, and TRACE3. The number-suffix indicates the number of parametric arguments beyond a simple string, working much like printf. The different versions of TRACE were implemented to save data segment space.
When you generate an application with AppWizard, many ASSERT and TRACE statements are added for you. Hereís a TRACE example:
if (!m_wndToolBar.Create(this)
|| !m_wndToolBar.LoadToolBar(IDR_MAINFRAME))
{
TRACE0("Failed to create
toolbar\n");
return -1; // fail to create
}
If the creation of the toolbar fails, this routine will return -1, which signals to the calling program that something is wrong. This will happen in both debug and release builds. But in debug builds, a trace output will be sent that should help the programmer understand what went wrong.
All of the TRACE macros write to afxDump, which is usually the debug window, but can be set to stderr for console applications. The number-suffix indicates the parametric argument count, and you use the parametric values within the string to indicate the passed data type. For example, to send a TRACE statement that includes the value of an integer variable:
TRACE1(ìError Number: %d\nî, -1 );
Or, to pass two arguments, maybe a string and an integer:
TRACE2(ìFile Error %s, error number: %d\nî, __FILE__, -1 );
The most difficult part of tracing is making it a habit. Sprinkle TRACE statements anywhere you return error values: before ASSERT statements, and in areas where you are not quite sure you constructed your code correctly. When confronted with unexpected behavior, add TRACE statements first so that you understand more of what is going on before you start debugging.
If the idea of code that is not included in a release build appeals to you, you may want to arrange for some of your own code to be included in debug builds but not in release builds. Itís easy. Just wrap the code in a test of the _DEBUG constant, like this:
#ifdef _DEBUG
// debug code here
#endif
In release builds, this code will not be compiled at all.
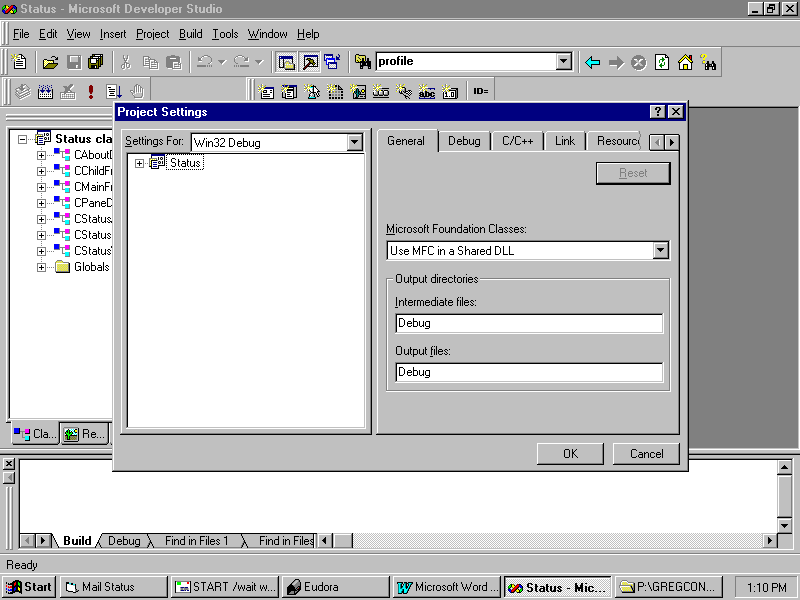
You can also use different settings for debug and release builds. For example, many developers use different compiler warning levels. All of the settings and configurations of the compiler and linker are kept separately for debug and release builds, and can be changed independently. For example, to bump your warning level to 4 for debug builds only, follow these steps:
Fig. 24.1 The Project Settings dialog box enables you to set configuration items for different phases of development.
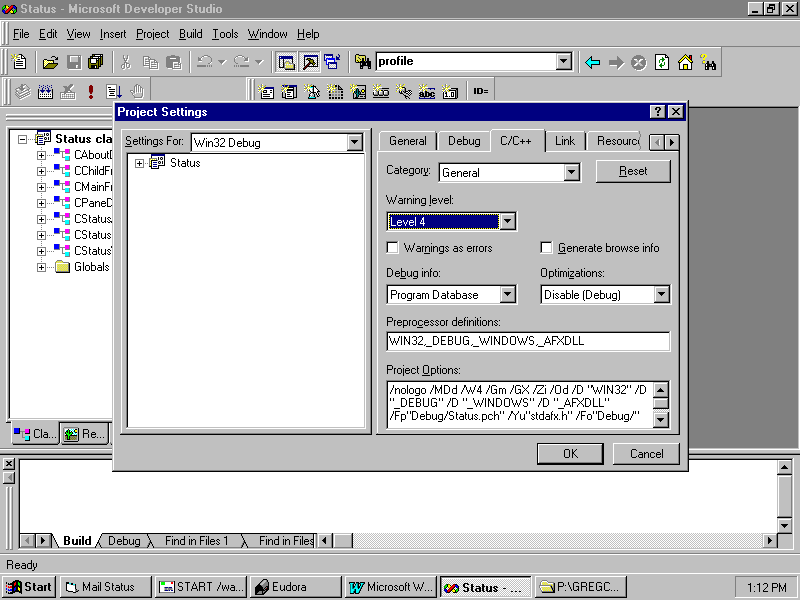
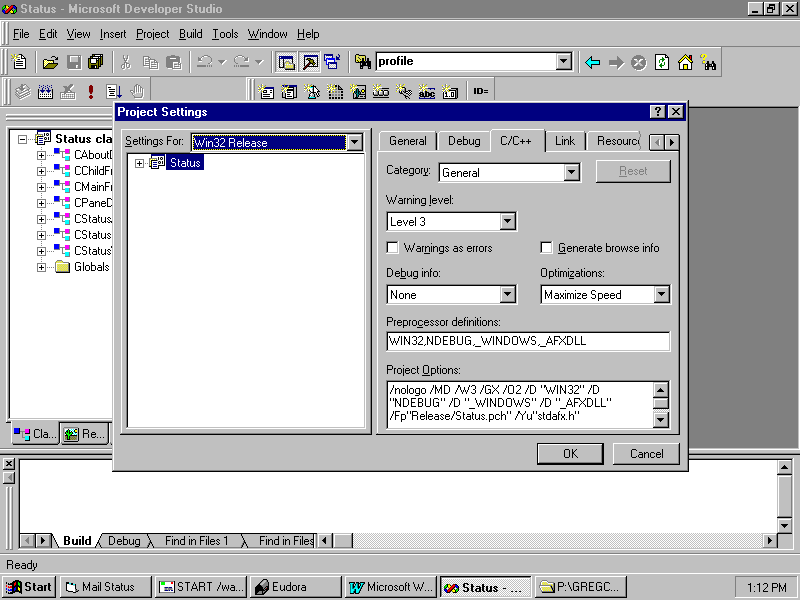
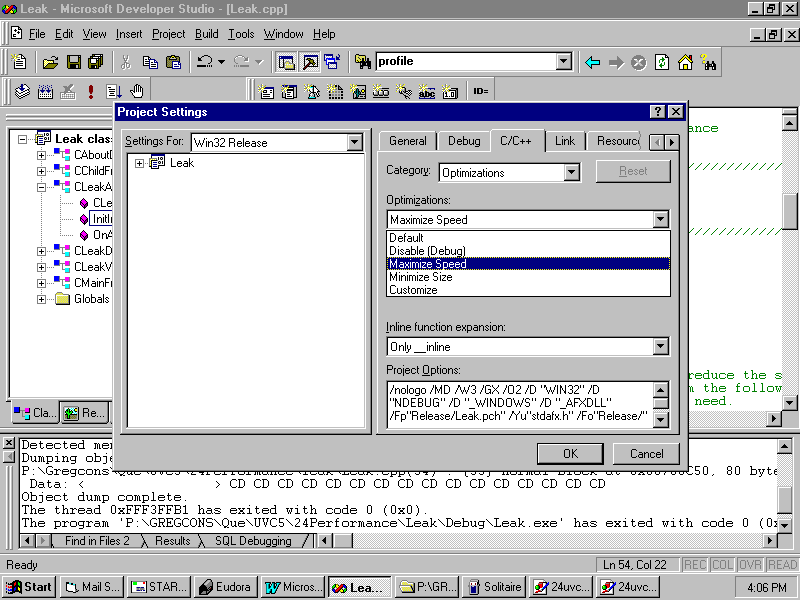
Click the C/C++ tab and set the Warning Level to Level 4, as shown in Figure 24.2. The default is Level 3, which we will use for the release version (see Figure 20.3).
Fig. 24.2 Warning levels can be set higher during development.
Fig. 24.3 Warning levels are usually lower in a production release.
A memory leak can be the most pernicious of errors. Small leaks may not cause any execution errors in your program until it is run for an exceptionally long time or with a larger-than-usual data file. Because most programmers test with tiny data files, or run the program for only a few minutes when they are experimenting with parts of it, memory leaks may not reveal themselves in everyday testing. Alas, memory leaks may well reveal themselves to your users when the program crashes or otherwise misbehaves.
What does it mean when your program has a memory leak? It means that your program allocated memory and never released it. One very simple cause is calling new to allocate an object or an array of objects on the heap, and never calling delete. Another cause of memory leaks is to change the pointer kept in a variable without deleting the memory the pointer was pointing to. More subtle memory leaks arise when a class with a pointer as a member variable calls new to assign the pointer, but doesnít have a copy constructor, assignment operator, or destructor. Listing 24.1 illustrates some ways that memory leaks are caused.
Listing 24.1óCausing Memory Leaks
// simple pointer leaving scope
{
int * one = new int;
*one = 1;
} // one is out of scope now, and wasnít deleted
// mismatched new and delete: new uses delete and new[] uses delete[]
{
float * f = new float[10];
// use array
delete f; // Oops! Deleted f[0] correct version is delete [] f;
}
// pointer of new memory goes out of scope before delete
{
const char * DeleteP = ìDonít forget Pî;
char * p = new char[strlen(DeleteP) + 1];
strcpy( p, DeleteP );
} // scope ended before delete[]
class A
{
public:
int * pi;
}
A::A()
{
pi = new int();
*pi = 3;
}
// ..later on, some code using this class..
A firsta; //allocates an int for first.pi to point to
B seconda; //allocates another int for seconda.pi
seconda=firsta;
// will perform a bitwise copy. Both objects have
// a pi that points to the first int allocated. The
// pointer to the second int allocated is gone forever.
The code fragments all represent ways in which memory can be allocated and the pointer to that memory lost before deallocation. Once the pointer goes out of scope, you cannot reclaim the memory and no one else can use it either. Things get even worse when you consider exceptions, discussed in Chapter 26, ìExceptions, Templates, and the Latest Additions to C++,î because if an exception is thrown, your flow of execution may leave a function before reaching the delete at the bottom of the code. Because destructors are called for objects that are going out of scope as the stack unwinds, you can prevent some of these problems by putting delete calls in destructors. This is also discussed in more detail in Chapter 26, in the "Placing the Catch Block" section.
Like all bugs, the secret to dealing with memory leaks is to prevent them, or to detect them as early as possible when they occur. You can develop some good habits to help you:
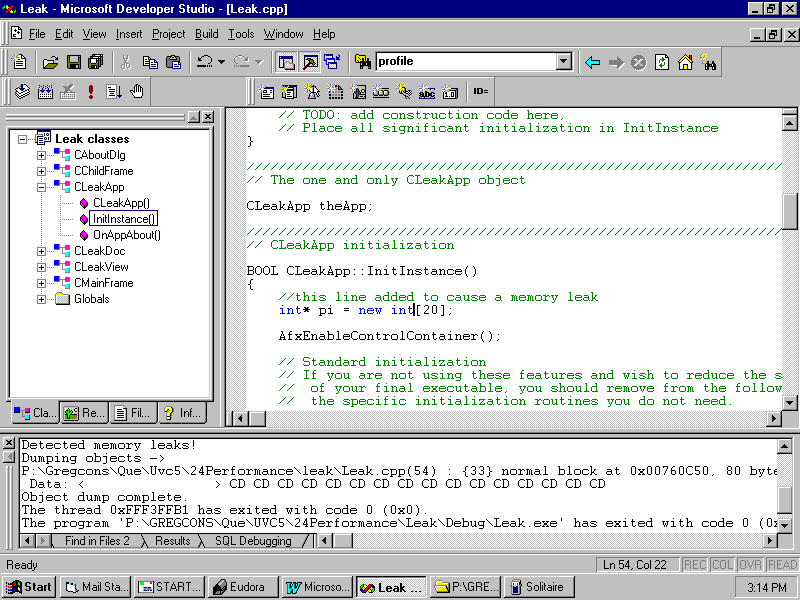
MFC has a lot to offer the programmer who is looking for memory leaks. In debug builds, whenever you use new and delete you are actually using special debug versions, that track the file number and line on which each allocation occurred, and that match up deletes with their news. If memory is left over as the program ends, you get a warning message in the output section, as shown in Figure 24.4.
Fig. 24.4 Memory leaks are detected automatically in debug builds.
To see this for yourself, create an AppWizard MDI application called Leak, accepting all the defaults. In the InitInstance() function of the application class (CLeakApp in this example), add this line:
int* pi = new int[20];
Build a debug version of the application and run it by choosing Build, Start Debug, Go, or click the Go button on the Build mini-bar. You should see output like Figure 24.4. Notice that the file name (Leak.cpp) and line number where the memory was allocated are provided in the error message. The editor window displays Leak.cpp with the cursor on line 54. (The coordinates in the lower-right corner remind you what line number you are on at all times.) If you were writing a real application you would now know what the problem was. The next problem to tackle is where to fix it (more specifically, where to put the delete).
When a program is executing within a particular scope, like a function, all variables allocated in that function are allocated on the stack. The stack is a temporary storage space that shrinks and grows, like an accordion. The stack is used to store the current execution address prior to a function call, the arguments passed to the function, and the local function objects and variables.
When the function returns, the stack pointer is reset to that location where the prior execution point was stored. This makes the stack space after the reset location available to whatever else needs it, which means those elements allocated on the stack in the function are gone. This process is referred to as stack unwinding.
Objects or variables defined with the keyword static are not allocated on the stack.
Stack unwinding also happens when an exception occurs. To reliably restore the program to its state before an exception occurred in the function, the stack is unwound. Stack-wise variables are gone and the destructors for stack-wise objects are called and are also gone. Unfortunately, the same is not true for dynamic objects. The handles (for example, pointers) are unwound but delete is not called by the unwinding process. This causes a memory leak.
In some cases, the solution is to add delete statements to the destructors of objects that you know will be destructed as part of the unwinding, so that they can use these pointers before they go out of scope. A more general approach is to replace simple pointers with a C++ class that can be used just like a pointer, but contains a destructor that deletes any memory at the location where it points. Donít worry, you donít have to write such a class: one is included in the Standard Template Library, which comes with Visual C++. Listing 24.2 is a heavily edited version of the auto_ptr class definition, presented to demonstrate the key concepts.
If you havenít seen template code before, itís explained in Chapter 26, ìExceptions, Templates, and the Latest Additions to C++.î
Listing 24.2óA Scaled-Down Version of the auto_ptr Class
// This class is not complete. Use the complete definition in
//the Standard Template Library.
template <class T>
class auto_ptr
{
public:
auto_ptr( T *p = 0) : rep(p) {}
// store pointer in the class
~auto_ptr(){ delete rep; } // delete internal rep
// include pointer conversion members
inline T* operator->() const { return rep; }
inline T& operator*() const { return *rep; }
private:
T * rep;
};
The class has one member variable, a pointer to whatever type it is you want a pointer to. It has a one argument constructor to build an auto_ptr from a int* or a Truck* or any other pointer type. The destructor deletes the memory pointed to by the internal member variable. Finally, the class overrides -> and *, the dereferencing operators, so that dereferencing an auto_ptr feels just like dereferencing an ordinary pointer.
If there is some class C to which you want to make an automatic pointer called p, all you do is this:
auto_ptr<C> p(new C());
Now you can use p just as though it was a C*. For example:
p->Method(); // calls C::Method()
You never have to delete the C object that p points to, even in the event of an exception, because p was allocated on the stack. When it goes out of scope, its destructor is called and the destructor calls delete on the C object that was allocated in the new statement.
There was a time when programmers were expected to optimize their code themselves. Many a night was spent arguing about the order in which to test conditions, or which variables should be register rather than automatic storage. These days, compilers come with optimizers that can speed execution or shrink program size far beyond what a typical programmer can accomplish by hand.
Hereís a simple example of how optimizers work. Imagine you have written a piece of code like this:
for (i=0;i<10;i++)
{
y=2;
x[i]=5;
}
for (i=0; i<10; i++)
{
total += x[i];
}
Your code will run faster, with no impact on the final results, if the y=2 is moved to before the first loop. In addition, the two loops can easily be combined into a single loop. If you do that, itís faster to add 5 to total each time than it is to calculate the address of x[i] in order to retrieve the value just stored into it. Really bright optimizers may even realize that total can be calculated outside the loop as well. The revised code may look like this:
y=2;
for (i=0;i<10;i++)
{
x[i]=5;
}
total += 50;
Optimizers do far more than this, of course, but this example gives you an idea of whatís going on behind the scenes. Itís up to you whether the optimizer focuses on speed, occasionally at the expense of memory usage, or tries to minimize memory usage, perhaps at a slighter lower speed.
To set the optimization options for your project, select the Project, Settings command from Developer Studio's menu bar. The Project Settings property sheet, first shown in Figure 24.1, appears. Click the C/C++ tab and make sure you are looking at the Release settings, then select Optimizations in the Category box. Optimization should be turned off for debug builds, since the code in your source files and the code being executed wonít match line for line, which will confuse you and the debugger. You should turn on some kind of optimization for release builds. Choose from the drop-down list box, as shown in Figure 24.5.
Fig. 24.5 Select the type of optimization you want.
If you select the Customize option in the Optimizations box, you can select from the list of individual optimizations, including Assume No Aliasing, Global Optimizations, Favor Fast Code, Generate Intrinsic Functions, Frame-Pointer Omission, and more. However, as you can tell from the names of these optimizations, you really have to know what you're doing before you set up a custom optimization scheme. For now, accept the schemes that have been laid out for you.
Profiling an application lets you discover bottlenecks, pieces of code that are slowing your applicationís execution and deserve special attention. Itís pointless to hand-optimize a routine if you donít know that the routine is called often enough for its speed to matter.
Another use of a profiler is to see whether the test cases you have put together result in every one of your functions being called, or in each line of your code being executed. You may think you have selected test inputs that guarantee this; however, the profiler can confirm it for you.
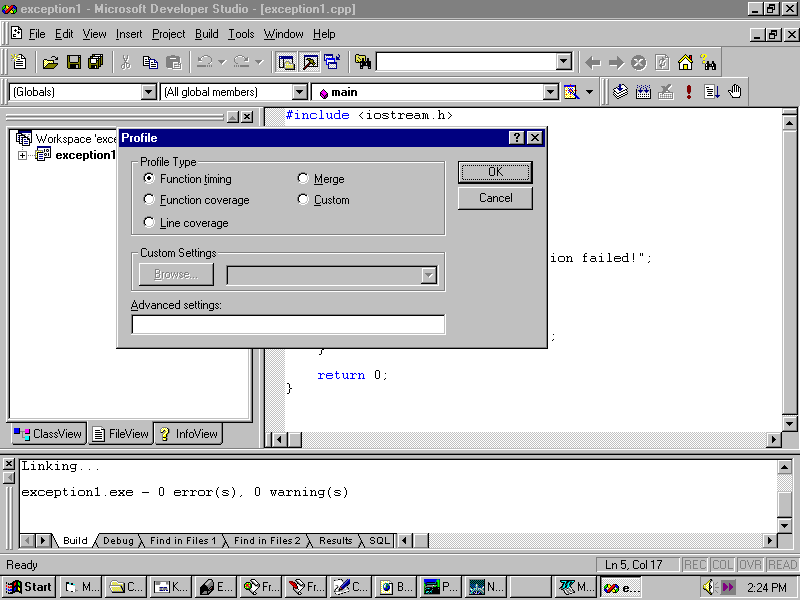
Visual C++ includes a profiler integrated with the IDE: all you need to do is use it. First, adjust your project settings to include profiler information. Bring up the Project Settings property sheet as you did in the preceeding section and click the Link tab. Check the Enable Profiling check box. Click OK and rebuild your project. Links will be slower now, because you cannot do an incremental link when you are planning to profile, but you can go back to your old settings once youíve learned a little about the way your program runs. Choose Build, Profile, and the Profile dialog box, shown in Figure 24.6, appears.
Fig. 24.6 A profiler can gather many kinds of information.
If you arenít sure what any of the radio buttons on this dialog box mean, click the ? (question mark) in the upper-right corner and then click the radio button. You will receive a short explanation of the option. (If you would like to add this kind of context-sensitive help to your own applications, be sure to read Chapter 11, ìHelp.î)
You donít profile as a way to catch bugs, but it can help to validate your testing, or show you the parts of your application that need work, which makes it a vital part of the developerís toolbox. Get in the habit of profiling all of your applications at least once in the development cycle.
MFC provides you with powerful tools to help ensure that your programs are bug-free and fast. ASSERT statements protect you against errors in logic. TRACE statements let you follow your applicationís progress without having to use the debugger. The debug new and delete make memory leaks easier to track. All of these features disappear in release builds, which means they cannot slow down or bloat the code your users getóthough the impact of using these techniques in development can be a significantly positive one. Finally, the optimizer can speed or shrink your code, and the profiler can draw your attention to specific functions that need attention. Programmers who use the techniques presented in this chapter will produce faster, neater code with less bugs and no mysterious hangs from memory leaks.
To learn about other techniques and tools, see these chapters:
© 1997, QUE Corporation, an imprint of Macmillan Publishing USA, a Simon and Schuster Company.
![]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}