C++ is an evolving language, and frequently undergoes review and improvement. New power features that have been added to C++ in the recent past are exceptions, templates, Run-Time Type Information (RTTI), namespace support, and some new keywords and data types. While most programmers delay learning these concepts until they have six months to a year of Visual C++ programming experience, you should consider learning it now. These concepts are not much more difficult than the ones covered earlier in this book, and can add real power to your programs.
Exceptions are a better way of handling runtime errors in your programs than using old-fashioned error-handling techniques.
Function templates enable you to create a general blueprint for a function. The compiler can then create different versions of the function for you.
Class templates are similar to function templates, except that they act as a blueprint for classes rather than for functions.
Run-Time Type Information (RTTI) adds to C++ the ability to safely downcast polymorphic-object pointers, as well as to get information about objects at runtime.
Identifier scope can be a hassle when you have to include several external libraries into your project. Namespaces help you avoid identifier-name conflict.
The new data type boolean, and the new keywords mutable and explicit, eliminate a number of annoying programming troubles.
When you write applications using Visual C++, sooner or later you're going to run into error-handling situations that donít seem to have a solution. Perhaps you are writing a function that returns a numeric value, and need a way to send back an error response. Sometimes you can come up with one special return value, perhaps 0 or -1, that indicates a problem. Other times there doesnít seem to be a way to signal trouble. Or perhaps you use special return values, but find yourself writing code that starts out like this:
while (somefunction(x))
{
for (int i=0; i<limit; i++)
{
y = someotherfunction(i);
}
}
Now you realize that if someotherfunction() returns -1, you should not move on to the next i, and you should leave the while loop. Your code becomes the following:
int timetostop = 0;
while (somefunction(x) && !timetostop)
{
for (int i=0; i<limit && !timetostop; i++)
{
if ( (y = someotherfunction(i)) == -1)
timetostop = 1;
}
}
This isnít bad, though itís getting hard to read. If there are two or three things that could go wrong, your code gets unmanageably complex.
Exceptions are designed to handle just these sorts of problems. The exception mechanism allows programs to signal each other about serious and unexpected problems. There are three places in your code that participate in most exceptions:
Simple Exception Handling
The mechanism used by exception-handling code is really pretty simple. You place the source code that you want guarded against errors inside a try block. You then construct a catch program block that acts as the error handler. If the code in the try block (or any code called from the try block) throws an exception, the try block immediately ceases execution and the program continues inside the catch block.
For example, memory allocation is one place in a program where you might expect to run into trouble. Listing 26.1 shows a nonsensical little program that allocates some memory and then immediately deletes it. Because memory allocation could fail, the code that allocates the memory is enclosed in a try program block. If the pointer returned from the memory allocation is NULL, the try block throws an exception. In this case, the exception object is a string.
The sample applications in this chapter are console applications, which can run from a DOS prompt and donít have a graphical interface. This keeps them small enough to be shown in their entirety in the listings. To try them yourself, create a console application as discussed in Chapter 28, ìFuture Explorations,î add a file to the project, and add the code shown here.

Listing 26.1ñEXCEPTION1.CPPñSimple Exception Handling
#include <iostream.h>
int main()
{
int* buffer;
try
{
buffer = new int[256];
if (buffer == NULL)
throw "Memory allocation failed!";
else
delete buffer;
}
catch(char* exception)
{
cout << exception << endl;
}
return 0;
}
When the program throws the exception, program execution jumps to the first line of the catch program block. (The remainder of the code inside the try block is not executed.) In the case of Listing 26.1, this line just prints out a message, after which the function's return line is executed and the program ends.
If the memory allocation is successful, the program executes the entire try block, deleting the buffer. Then program execution skips over the catch block completely, in this case going directly to the return statement.
The catch program block does more than direct program execution. It actually catches the exception object thrown by the program. For example, in Listing 26.1, you can see the exception object being caught inside the parentheses following the catch keyword. This is very similar to a parameter being received by a method. In this case, the type of the "parameter" is char* and the name of the parameter is exception.
Exception Objects
The beauty of C++ exceptions is that the exception object thrown can be just about any kind of data structure you like. For example, you might want to create an exception class for certain kinds of exceptions that occur in your programs. Listing 26.2 shows a program that defines a general-purpose exception class called MyException. In the case of a memory-allocation failure, the main program creates an object of the class and throws it. The catch block catches the MyException object, calls the object's GetError() member function to get the object's error string, and then displays the string on the screen.
Listing 26.2ñEXCEPTION2.CPPñCreating an Exception Class
#include <iostream.h>
class MyException
{
protected:
char* m_msg;
public:
MyException(char *msg) { m_msg = msg; }
~MyException(){}
char* GetError() {return m_msg; };
};
int main()
{
int* buffer;
try
{
buffer = new int[256];
if (buffer == NULL)
{
MyException* exception =
new MyException("Memory allocation failed!");
throw exception;
}
else
delete buffer;
}
catch(MyException* exception)
{
char* msg = exception->GetError();
cout << msg << endl;
}
return 0;
}
An exception object can be as simple as an integer error code or as complex as a fully developed class. MFC provides a number of exception classes, including CException and several classes derived from it. The abstract class CException has a constructor and three member functions: Delete(), which deletes the exceptions, GetErrorMessage(), which returns a string describing the exception, and ReportError(), which reports the error in a message box.
Placing the catch Block
The catch program block doesn't have to be in the same function as the one in which the exception is thrown. When an exception is thrown, the system starts "unwinding the stack," looking for the nearest catch block. If the catch block is not found in the function that threw the exception, the system looks in the function that called the throwing function. This search continues on up the function-call stack. If the exception is never caught, the program halts.
Listing 26.3 is a short program that demonstrates this concept. The program throws the exception from the AllocateBuffer() function but catches the exception in main(), which is the function from which AllocateBuffer() is called.
Listing 26.3ñEXCEPTION3.CPPñCatching Exceptions Outside of the Throwing Function
#include <iostream.h>
class MyException
{
protected:
char* m_msg;
public:
MyException(char *msg) { m_msg = msg;}
~MyException(){}
char* GetError() {return m_msg;}
};
class BigObect
{
private:
int* intarray;
public:
BigObject() {intarray = new int[1000];}
~BigObject() {delete
intarray;}
}
int* AllocateBuffer();
int main()
{
int* buffer;
try
{
buffer = AllocateBuffer();
delete buffer;
}
catch (MyException* exception)
{
char* msg = exception->GetError();
cout << msg << endl;
}
return 0;
}
int* AllocateBuffer()
{
BigObject huge;
float* floatarray = new float[1000];
int* buffer = new int[256];
if (buffer == NULL)
{
MyException* exception =
new MyException("Memory allocation failed!");
throw exception;
}
delete floatarray;
return buffer;
}
When the exception is thrown in AllocateBuffer(), the remainder of the function is not executed. The dynamically allocated floatarray will not be deleted. The BigObject that was allocated on the stack will go out of scope and its destructor will be executed, deleting the intarray member variable that was allocated with new in the constructor. This is an important concept to grasp: objects created on the stack will be destructed as the stack unwinds. Objects created on the heap will not. Your code must take care of these. For example, AllocateBuffer() should include code to delete floatarray before throwing the exception, like this:
if (buffer == NULL)
{
MyException* exception =
new MyException("Memory allocation failed!");
delete floatarray;
throw exception;
}
In many cases, using an object with a carefully written destructor can save you significant code duplication when you are using exceptions. If you are using objects allocated on the heap, you may need to catch and rethrow exceptions just so that you can delete them. Consider the code in Listing 26.4, in which the exception is thrown right past an intermediate function up to the catching function.
Listing 26.4ñEXCEPTION4.CPPñUnwinding the stack
#include <iostream.h>
class MyException
{
protected:
char* m_msg;
public:
MyException(char *msg) { m_msg = msg;}
~MyException(){}
char* GetError() {return m_msg;}
};
class BigObject
{
private:
int* intarray;
public:
BigObject() {intarray = new int[1000];}
~BigObject() {delete intarray;}
};
int* AllocateBuffer();
int* Intermediate();
int main()
{
int* buffer;
try
{
buffer = Intermediate();
delete buffer;
}
catch (MyException* exception)
{
char* msg = exception->GetError();
cout << msg << endl;
}
return 0;
}
int* Intermediate()
{
BigObject bigarray;
float* floatarray = new float[1000];
int* retval = AllocateBuffer();
delete floatarray;
return retval;
}
int* AllocateBuffer()
{
int* buffer = new int[256];
if (buffer == NULL)
{
MyException* exception =
new MyException("Memory allocation failed!");
throw exception;
}
return buffer;
}
Now if the exception is thrown, execution of AllocateBuffer() is abandoned immediately. The stack unwinds. Since there is no catch block in Intermediate(), execution of that function will be abandoned after the call to AllocateBuffer(). The delete for floatarray will not happen, but the destructor for bigarray will be executed. Listing 26.5 shows a way around this problem.
Listing 26.5ñRethrowing exceptions
int* Intermediate()
{
BigObject bigarray;
float* floatarray = new float[1000];
int* retval = NULL;
try
{
retval = AllocateBuffer();
}
catch (MyException e)
{
delete floatarray;
throw;
}
delete floatarray;
return retval;
}
This revised version of Intermediate() catches the exception just so that it can delete floatarray, and then throws it further up to the calling function. (Notice that the name of the exception is not in this throw statement: it can throw only the exception it just caught.) There are a few things you should notice about this revised code:
This is really starting to get ugly. Through all of this, the BigObject called bigarray has been quietly handled properly and easily, with an automatic call to the destructor no matter which function allocated it or where the exception was called. When you write code that uses exceptions, wrapping all your heap-allocated objects in classes like BigObject makes your life easier. BigObject implements a managed pointer: when a BigObject object like bigarray goes out of scope, the memory it pointed to is deleted. A very flexible approach to managed pointers is described at the end of the Template section in this chapter.
Handling Multiple Types of Exceptions
Because it's often the case that a block of code generates more than one type of exception, you can use multiple catch blocks with a try block. You might, for example, need to be on the lookout for both CException and char* exceptions. Because a catch block must receive a specific type of exception object, you need two different catch blocks to watch for both CException and char* exception objects. You can also set up a catch block to catch whatever type of exception hasn't been caught yet, by placing ellipses (...) in the parentheses, rather than a specific argument. The problem with this sort of multipurpose catch block is that you have no access to the exception object received and so must handle the exception in some general way.
Listing 26.6 is a program that generates three different types of exceptions based on a user's input. (In a real program, you shouldn't use exceptions to deal with user errors. It's a slow mechanism, and checking what the user typed can usually be handled more efficiently another way.)
When you run the program, you're instructed to enter a value between 4 and 8, except for 6. If you enter a value less than 4, the program throws a MyException exception; if you enter a value greater than 8, the program throws a char* exception; and, finally, if you happen to enter 6, the program throws the entered value as an exception.
Although the program throws the exceptions in the GetValue() function, the program catches them all in main(). The try block in main() is associated with three catch blocks. The first catches the MyException object, the second catches the char* object, and the third catches any other exception that happens to come down the pike.
Just as with if-else statements, the order in which you place catch program blocks can have a profound effect on program execution. You should always place the most specific catch blocks first. For example, in Listing 26.6, if the catch(...) block was first, none of the other catch blocks would ever be called. This is because the catch(...) is as general as you can get, catching every single exception that the program throws. In this case (as in most cases), you want to use catch(...) to receive only the leftover exceptions.
Listing 26.6ñEXCEPTION6.CPPñUsing Multiple catch Blocks
#include <iostream.h>
class MyException
{
protected:
char* m_msg;
public:
MyException(char *msg) { m_msg =
msg;}
~MyException(){}
char* GetError() {return m_msg;}
};
int GetValue();
int main()
{
try
{
int value = GetValue();
cout << "The value you entered is okay." << endl;
}
catch(MyException* exception)
{
char* msg = exception->GetError();
cout << msg << endl;
}
catch(char* msg)
{
cout << msg << endl;
}
catch(...)
{
cout << "Caught unknown exception!" << endl;
}
return 0;
}
int GetValue(){
int value;
cout << "Type a number from 4 to 8 (except 6):" << endl;
cin >> value;
if (value < 4)
{
MyException* exception =
new MyException("Value less than 4!");
throw exception;
}
else if (value > 8)
{
throw "Value greater than 8!";
}
else if (value == 6)
{
throw value;
}
return value;
}
The Old Exception Mechanism
Before try, catch, and throw were added to Visual C++, there was a rudimentary form of exception handling available to both C and C++ programmers through macros called TRY, CATCH, and THROW. These macros are a little slower than the standard exception mechanisms, and can only throw exceptions that are objects of a class derived from CException. Don't use these in your programs. If you have an existing program that uses them, you may want to convert to the new mechanism. There's a helpful article on this topic in the Visual C++ documentation: search for TRY and you'll find it.
It's a good guess that, at one time or another, you wished you could develop a single function or class that could handle any kind of data. Sure, you can use function overloading to write several versions of a function, or you can use inheritance to derive several different classes from a base class. But, in these cases, you still end up writing many different functions or classes. If only there was a way to make functions and classes a little smarter, so that you could write just one that handled any kind of data you wanted to throw at it. There is a way to accomplish this seemingly impossible task. You need to use something called templates, which are the focus of this section.
Introducing Templates
A template is a kind of blueprint for a function or class. You write the template in a general way, supplying placeholders, called parameters, for the data objects that the final function or class will manipulate. A template always begins with the keyword template followed by a list of parameters between angle brackets, like this:
template<class Type>
You can have as many parameters as you need, and you can name them whatever you like, but each must begin with the class keyword and must be separated by commas, like this:
template<class Type1, class Type2, class Type3>
As you may have guessed from the previous discussion, there are two types of templates: function and class. The following sections describe how to create and use both types of templates.
Creating Function Templates
A function template starts with the template line you just learned about, followed by the function's declaration, as shown in Listing 26.7. The template line specifies the types of arguments that will be used when calling the function, whereas the function's declaration specifies how those arguments are to be received as parameters by the function. Every parameter specified in the template line must be used by the function declaration. Notice the Type1 immediately before the function name. Type1 is a placeholder for the function's return type, which will vary depending upon how the template is used.
Listing 26.7ñ The Basic Form of a Function Template
template<class Type1, class Type2>
Type1 MyFunction(Type1 data1, Type1 data2, Type2 data3)
{
// Place the body of the function here.
}
An actual working example will help you understand how function templates become functions. A common example is a Min() function that can accept any type of arguments. Listing 26.6 is a short program that defines a template for a Min() function and then uses that function in main(). When you run the program, the program displays the smallest value of whatever data is sent as arguments to Min(). This works because the compiler takes the template and creates functions for each of the data types that are compared in the program.
Listing 26.8ñTEMPLATE1.CPPñUsing a Typical Function Template
#include <iostream.h>
template<class Type>
Type Min(Type arg1, Type arg2)
{
Type min;
if (arg1 < arg2)
min = arg1;
else
min = arg2;
return min;
}
int main()
{
cout << Min(15, 25) << endl;
cout << Min(254.78, 12.983) << endl;
cout
<< Min('A', 'Z') << endl;
return 0;
}
Notice how, in Listing 26.8, the Min() template uses the data type Type not only in its parameter list and function argument list, but also in the body of the function, in order to declare a local variable. This illustrates how you can use the parameter types just as you would use any specific data type such as int or char.
Because function templates are so flexible, they can often lead to trouble. For example, in the Min() template, you have to be sure that the data types you supply as parameters can be compared. If you tried to compare two classes, your program would not compile unless the classes overloaded the < and > operators.
Another way you can run into trouble is when the arguments you supply to the template are not used as you think. For example, what if you added the following line to main() in Listing 26.6?
cout <<
Min("APPLE", "ORANGE") << endl;
If you don't think about what you're doing in the previous line, you may jump to the conclusion that the returned result will be APPLE. The truth is, however, that the preceding line may or may not give you the result you expect. Why? Because the "APPLE" and "ORANGE" string constants result in pointers to char. This means that the program will compile fine, with the compiler creating a version of Min() that compares char pointers. But there's a big difference between comparing two pointers and comparing the data to which the pointers point. If "ORANGE" happens to be stored at a lower address than "APPLE", the preceding call to Min() results in "ORANGE".
A way to avoid this problem is to provide a specific replacement function for Min() that defines exactly how you want the two string constants compared. When you provide a specific function, the compiler uses that function instead of creating one from the template. Listing 26.9 is a short program that demonstrates this important technique. When the program needs to compare the two strings, it doesn't call a function created from the template but instead uses the specific replacement function.
Listing 26.9ñTEMPLATE2.CPPñUsing a Specific Replacement Function
#include <iostream.h>
#include <string.h>
template<class Type>
Type Min(Type arg1, Type arg2)
{
Type min;
if (arg1 < arg2)
min = arg1;
else
min = arg2;
return min;
}
char* Min(char* arg1, char* arg2)
{
char* min;
int result = strcmp(arg1, arg2);
if (result < 0)
min = arg1;
else
min = arg2;
return min;
}
int main()
{
cout << Min(15, 25) << endl;
cout << Min(254.78, 12.983) << endl;
cout << Min('A', 'Z') << endl;
cout << Min("APPLE", "ORANGE") <<
endl;
return 0;
}
Creating Class Templates
Just as you can create abstract functions with function templates, so too can you create abstract classes with class templates. A class template represents a class, which in turn represents an object. When you define a class template, the compiler takes the template and creates a class. You then declare (instantiate) objects of the class. As you can see, class templates add another layer of abstraction to the concept of classes.
You define a class template much as you define a function template, by supplying the template line followed by the class's declaration, as shown in Listing 26.10. Notice that, just as with a function template, you use the abstract data types given as parameters in the template line in the body of the class in order to define member variables, return types, and other data objects.
Listing 26.10ñ Defining a Class Template
template<class Type>
class CMyClass
{
protected:
Type data;
public:
CMyClass(Type arg) { data = arg;
}
~CMyClass() {};
};
When you're ready to instantiate objects from the template class, you must supply the data type that will replace the template parameters. For example, to create an object of the CMyClass class, you might use a line like this:
CMyClass<int> myClass(15);
The previous line creates a CMyClass object that uses integers in place of the abstract data type. If you wanted the class to deal with floating-point values, you'd create an object of the class something like this:
CMyClass<float> myClass(15.75);
For a more complete example, suppose you want to create a class that stores two values and has member functions that compare those values. Listing 26.11 is a program that does just that. First, the listing defines a class template called CCompare. This class stores two values that are supplied to the constructor. The class also includes the usual constructor and destructor, as well as member functions for determining the larger or smaller of the values, or to determine whether the values are equal.
Listing 26.11ñTEMPLATE3.CPPñUsing a Class Template
#include <iostream.h>
template<class Type>
class CCompare
{
protected:
Type arg1;
Type arg2;
public:
CCompare(Type arg1, Type arg2)
{
CCompare::arg1 = arg1;
CCompare::arg2 = arg2;
}
~CCompare() {}
Type GetMin()
{
Type min;
if (arg1 < arg2)
min = arg1;
else
min = arg2;
return min;
}
Type GetMax()
{
Type max;
if (arg1 > arg2)
max = arg1;
else
max = arg2;
return max;
}
int Equal()
{
int equal;
if (arg1 == arg2)
equal = 1;
else
equal = 0;
return equal;
}
};
int main()
{
CCompare<int> compare1(15, 25);
CCompare<double> compare2(254.78, 12.983);
CCompare<char> compare3('A', 'Z');
cout << "THE COMPARE1 OBJECT" << endl;
cout << "Lowest: " << compare1.GetMin() << endl;
cout << "Highest: " << compare1.GetMax() << endl;
cout << "Equal: " << compare1.Equal() << endl;
cout << endl;
cout << "THE COMPARE2 OBJECT" << endl;
cout << "Lowest: " << compare2.GetMin() << endl;
cout << "Highest: " << compare2.GetMax() << endl;
cout << "Equal: " << compare2.Equal() << endl;
cout << endl;
cout << "THE COMPARE2 OBJECT" << endl;
cout << "Lowest: " << compare3.GetMin() << endl;
cout << "Highest: " << compare3.GetMax() << endl;
cout << "Equal: " << compare3.Equal() << endl;
cout << endl;
return 0;
}
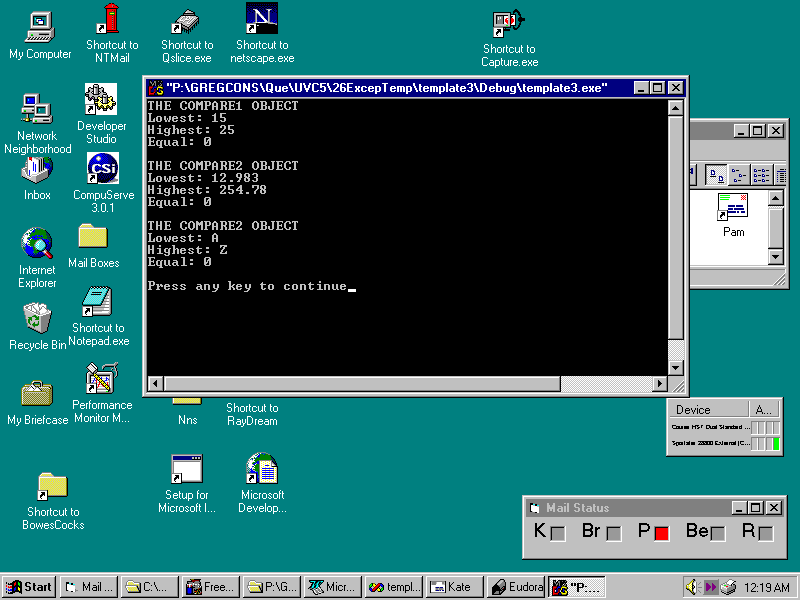
The main program instantiates three objects from the class template, one that deals with integers, one that uses floating-point values, and one that stores and compares character values. After creating the three CCompare objects, main() calls the objects' member functions in order to display information about the data stored in each object. Figure 26.1 shows the program's output.
Fig. 26.1 The Template3 program creates three different objects from a class template.
You can, of course, pass as many parameters as you like to a class template, just as you can with a function template. Listing 26.12 shows a class template that uses two different types of data.
Listing 26.12ñUsing Multiple Parameters with a Class Template
template<class Type1, class Type2>
class CMyClass
{
protected:
Type1 data1;
Type2 data2;
public:
CMyClass(Type1 arg1, Type2 arg2)
{
data1 = arg1;
data2 = arg2;
}
~CMyClass() {}
};
To instantiate an object of the CMyClass class, you might use a line like this:
CMyClass<int, char> myClass(15, 'A');
Finally, you can use specific data types, as well as the placeholder data types, as parameters in a class template. You just add the specific data type to the parameter list, just as you add any other parameter. Listing 26.13 is a short program that creates an object from a class template that uses two abstract parameters and one specific data type.
Listing 26.13ñUsing Specific Data Types as Parameters in a Class Template
#include <iostream.h>
template<class Type1, class Type2, int num>
class CMyClass
{
protected:
Type1 data1;
Type2 data2;
int data3;
public:
CMyClass(Type1 arg1, Type2 arg2, int num)
{
data1 = arg1;
data2 = arg2;
data3 = num;
}
~CMyClass() {}
};
int main()
{
CMyClass<int, char, 0> myClass(15, 'A', 10);
return 0;
}
The Standard Template Library
Before you run off to write templates that implement linked lists, binary trees, sorting, and other common tasks, you might like to know that somebody else already has. Visual C++ incorporates the Standard Template Library (STL), which includes hundreds of functon and class templates to tackle common tasks. Would you like a stack of ints or a stack of floats? Don't write lots of different stack classes, don't even write one stack class template, just use the stack template included in the STL. The same is true for almost every common data structure and operation.
Earlier in this chapter you saw applications that use exceptions and allocate memory on the heap (dynamic allocation with new) can run into trouble when exceptions are thrown and the delete statement for that memory gets bypassed. If there was an object on the stack whose destructor called delete for the memory, you would prevent this problem. STL implements a managed pointer like this: it's called auto-ptr. Here's the declaration for auto_ptr:
template<class T>
class auto_ptr {
public:
typedef T element_type;
explicit auto_ptr(T *p = 0) ;
auto_ptr(const auto_ptr<T>& rhs) ;
auto_ptr<T>& operator=(auto_ptr<T>& rhs);
~auto_ptr();
T& operator*() const ;
T *operator->() const;
T *get() const ;
T *release() const;
};
Once you create a pointer to an int, float, Employee, or any other type of object, you can make an auto_ptr and use that just like a pointer. For example, imagine a code fragment like this:
// ...
Employee* emp = new Employee(stuff);
emp->ProcessEmployee;
delete emp;
// ...
When you realize that ProcessEmployee() might throw an EmployeeException, you might change this code to read like this:
// ...
Employee* emp = new Employee(stuff);
try
{
emp->ProcessEmployee;
}
catch (EmployeeException e)
{
delete emp;
throw;
}
delete emp;
// ...
But you think this is ugly and hard to maintain, so you go with an auto_ptr instead:
#include <memory>
// ...
auto_ptr<Employee> emp (new Employee(stuff));
emp->ProcessEmployee;
// ...
This looks just like the first example, but it works just like the second: whether you leave this code snippet normally or because of an exception, emp will go out of scope, and when it does the Employee object that was allocated on the heap will be deleted for you automatically. No extra try or catch blocks, and as an extra bonus you don't even have to remember to delete the memory in the routine at allñit's taken care of for you.
Look again at the functions declared in the template: a constructor, a copy constructor, an address-of (&) operator, a destructor, a contents of (*) operator, a dereferencing (->) operator, and functions called get() and release(). These work together to ensure that you can treat your pointer exactly as though it was an ordinary pointer. It's neat stuff.
Run-Time Type Information (RTTI) was added to C++ so that programmers could obtain information about objects at runtime. This capability is especially useful when you're dealing with polymorphic objects, because it enables your program to determine at runtime what exact type of object it's currently working with. Later in this section, you'll see how important this type of information can be when you're working with class hierarchies. RTTI can also be used to safely downcast an object pointer. In this section, you'll discover how RTTI works and why you'd want to use it.
Polymorphism is discussed in Chapter 4, "Messages and Commands," in a sidebar in the "Message Maps" section.
Introducing RTTI
The RTTI standard introduces three new elements to the C++ language. The dynamic_cast operator performs downcasting of polymorphic objects; the typeid operator retrieves information (in the form of a type_info object) about an object; and the type_info class stores information about an object, providing member functions that can be used to extract that information.
The public portion of the type_info class is defined in Visual C++ and shown in Listing 26.14.
Listing 26.14ñThe type_info Class, defined by Visual C++
class type_info {
public:
virtual ~type_info();
int operator==(const type_info& rhs) const;
int operator!=(const type_info& rhs) const;
int before(const type_info& rhs) const;
const char* name() const;
const char* raw_name() const;
};
As you can see, the class provides member functions that can compare objects for equality, and return the object's name, both as a readable text string and as a raw decorated object name. The before() member function remains a bit mysterious and poorly documented. According to Microsoft, the Visual C++ implementation of before() is used "to determine the collating sequence of types." Microsoft further states that "there is no link between the collating order of types and inheritance relationships."
Performing Safe Downcasts
Once you start writing a lot of OOP programs, you'll run into times when you need to downcast one type of object to another. Downcasting is the act of converting a base-class pointer to a derived-class pointer (a derived class being a class that's derived from the base class). You use dynamic_cast to downcast an object, like this:
Type* ptr = dynamic_cast<Type*>(Pointer);
In the preceding example, Type is the type to which the object should be cast, and Pointer is a pointer to the object. If the pointer cannot be safely downcast, the dynamic_cast operator returns 0.
Suppose, for example, that you have a base class called CBase and a class derived from CBase called CDerived. Because you want to take advantage of polymorphism, you obtained a pointer to CDerived, like this:
CBase* derived = new CDerived;
Notice that, although you're creating a CDerived object, the pointer is of the base-class type, CBase. This is a typical scenario in programs that take advantage of OOP polymorphism.
Now suppose that you want to safely downcast the CBase pointer to a CDerived pointer. You might use dynamic_cast, as follows:
CDerived* ptr = dynamic_cast<CDerived*>(derived);
If the cast returns 0, the downcast was not allowed.
Getting Object Information
As mentioned previously, you can use the typeid operator to obtain information about an object. Although the dynamic_cast operator applies only to polymorphic objects, you can use typeid on any type of data object. For example, to get information about the int data object, you could use lines like these:
const type_info& ti = typeid(int);
cout << ti.name();
In the first line, you can see that the typeid operator returns a reference to a type_info object. You can then use the object's member functions to extract information about the data object. In the preceding example, the cout object will output the word int. The typeid operator's single argument is the name of the data object for which you want a type_info object.
Of course, a better use for typeid is to compare and get information about classes that you have defined in your program. Listing 26.15 is a short program that prints out information about the classes it defines.
Listing 26.15ñRTTI.CPPñUsing the typeid Operator
#include <iostream.h>
#include <typeinfo.h>
class CBase
{
public:
CBase() {};
~CBase() {};
};
class CDerived : public CBase
{
public:
CDerived() {};
~CDerived() {};
};
int main()
{
CBase* base = new CBase;
CBase* derived = new CDerived;
const type_info& ti1 = typeid(CBase);
const type_info& ti2 = typeid(CDerived);
cout << "First object's name: " << ti1.name() << endl;
cout << "First object's raw name: " << ti1.raw_name() << endl;
cout << endl;
cout << "Second object's name: " << ti2.name() << endl;
cout << "Second object's raw name: " << ti2.raw_name() << endl;
cout << endl;
if (ti1 == ti2)
cout << "The two objects are equal." << endl;
else
cout << "The two objects are not equal." << endl;
cout << endl;
delete base;
delete derived;
return 0;
}
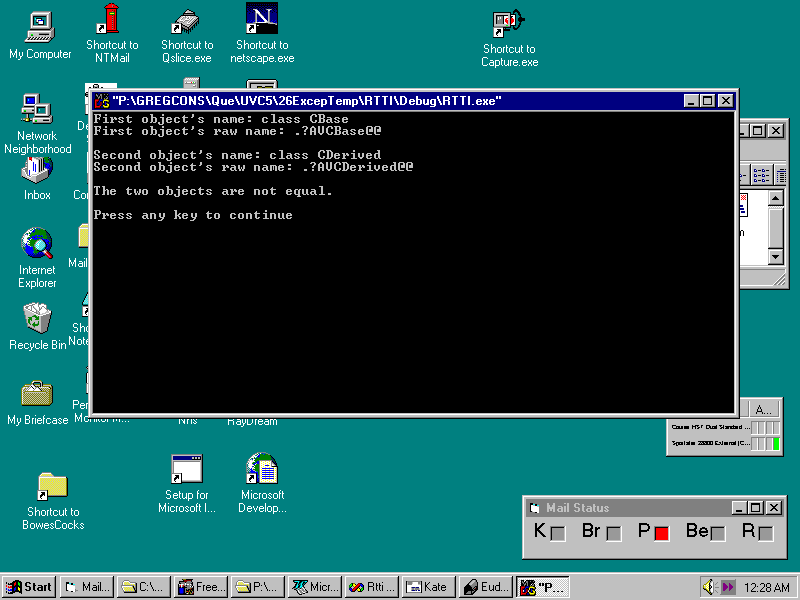
Listing 26.15 first defines a base class called CBase. The program then derives a second class, called CDerived, from the base class. In main(), the program instantiates an object from each class, the objects being called base and derived. Then the program calls typeid to obtain type_info objects for each class. Finally, the program calls the type_info member functions to extract information about the classes, as well as to compare the classes for equality. Figure 26.2 shows the program's output. If you have trouble running the RTTI program shown in Listing 26.15, jump ahead to the next section, which tells you how to enable RTTI.
Fig. 26.2 This is Listing 26.15 in action.
Preparing to Use RTTI
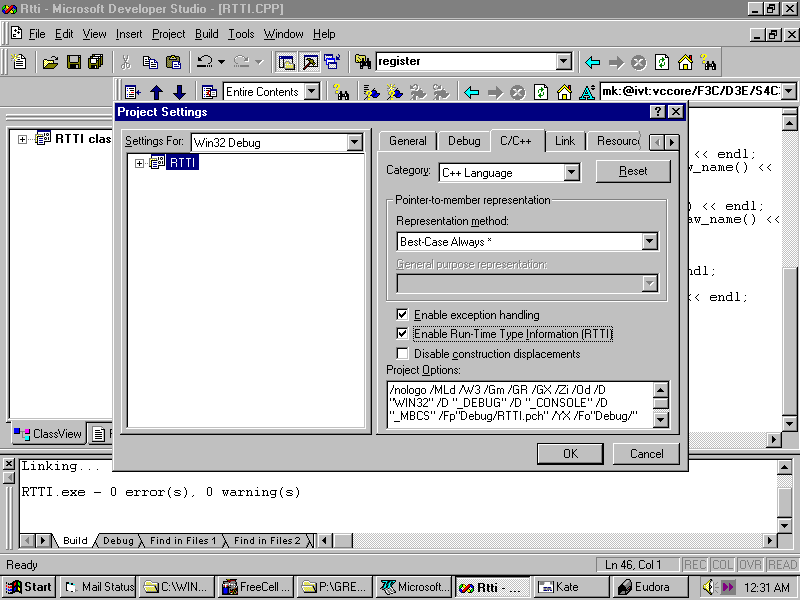
If you got a strange error message or warning when you tried to compile the RTTI program, you probably don't yet have RTTI enabled. To enable RTTI, use the following procedure:
Fig. 26.3 The C/C++ options page controls Run Time Type Identification.
Select the Enable Run-Time Type Information (RTTI) option and then click OK to finalize your choices.
Also, be sure that you include the TYPEID.H header file in any source-code file that calls the typeid operator. If you don't, your program will not compile.
A namespace defines a scope in which duplicate identifiers cannot be used. For example, you already know that you can have a global variable named value and then also define a function with a local variable called value. Because the two variables are in different namespaces, your program knows that it should use the local value when inside the function and the global value everywhere else.
Namespaces, however, do not extend far enough to cover some very thorny problems. One example is duplicate names in external classes or libraries. This issue crops up when a programmer is using several external files within a single project. None of the external variables and functions can have the same name as other external variables or functions. To avoid this type of problem, third-party vendors frequently add prefixes or suffixes to variable and function names in order to reduce the likeliness of some other vendor using the same name.
Obviously, the C++ gurus have come up with a solution to such scope-resolution problems. (Otherwise, we wouldn't be having this discussion.) The solution is user-defined namespaces, about which you'll study in this section.
Defining a Namespace
To accommodate user-defined namespaces, the keyword namespace was added to the C++ language. In its simplest form, a namespace is not unlike a structure or a class. You start the namespace definition with the namespace keyword, followed by the namespace's name and the declaration of the identifiers that will be valid within the scope of that namespace.
Listing 26.16 shows a namespace definition. The namespace is called A and includes two identifiers, i, and j, and a function, Func(). Notice that the Func() function is completely defined within the namespace definition. You can also choose to define the function outside of the namespace definition, but in that case, you must preface the function definition's name with the namespace's name, much as you would preface a class's member-function definition with the class's name. Listing 26.17 shows this form of namespace function definition.
Listing 26.16ñDefining a Namespace
namespace A
{
int i;
int j;
int Func()
{
return 1;
}
}
Listing 26.17ñDefining a Function Outside of the Namespace Definition
namespace A
{
int i;
int j;
int Func();
}
int A::Func()
{
return 1;
}
Namespaces must be defined at the file level of scope or within another namespace definition. They cannot be defined, for example, inside a function.
Namespace Scope Resolution
Namespaces add a new layer of scope to your programs, but this means that you need some way of identifying that scope. The identification is, of course, the namespace's name, which you must use in your programs to resolve references to identifiers. For example, to refer to the variable i in namespace A, you'd write something like this:
A::i = 0;
You can, if you like, nest one namespace definition within another, as shown in Listing 26.18. In the case shown in the listing, however, you have to use more complicated scope resolutions in order to differentiate between the i variable declared in A and B, like this:
A::i = 0;
A::B::i = 0;
Listing 26.18ñNesting Namespace Definitions
namespace A
{
int i;
int j;
int Func()
{
return 1;
}
namespace B
{
int i;
}
}
If you're going to frequently reference variables and functions within namespace A, you can avoid using the A:: resolution by preceding the program statements with a using line, as shown in Listing 26.19.
Listing 26.19ñResolving Scope with the using Keyword
using namespace A;
i = 0;
j = 0;
int num1 = Func();
Unnamed Namespaces
Just to be sure that you're thoroughly confused, Visual C++ allows you to have unnamed namespaces. You define an unnamed namespace exactly as you would any other namespace, except you leave off the name. Listing 26.20 shows the definition of an unnamed namespace. This lets you arrange variables whose names are only valid within one namespace, and cannot be accessed from elsewhere, because no other code can know the name of the unnamed namespace.
Listing 26.20ñDefining an Unnamed Namespace
namespace
{
int i;
int j;
int Func()
{
return 1;
}
}
You refer to the identifiers in the unnamed namespace without any sort of extra scope resolution, like this:
i = 0;
j = 0;
int num1 = Func();
Namespace Aliases
There may be times when you run into namespaces that have long names. In these cases, having to use that long name over and over in your program in order to access the identifiers defined in the namespace can be a major chore. To solve this problem, Visual C++ enables you to create namespace aliases, which are just replacement names for a namespace. You create an alias like this:
namespace A = LongName;
LongName is the original name of the namespace, and A is the alias. After the preceding line executes, you can access the LongName namespace using either A or LongName. You can think of an alias as a nickname or short form. Listing 26.21 is a short program that demonstrates namespace aliases.
Listing 26.21ñUsing a Namespace Alias
namespace ThisIsANamespaceName
{
int i;
int j;
int Func()
{
return 2;
}
}
int main()
{
namespace ns = ThisIsANamespaceName;
ns::i = 0;
ns::j = 0;
int num1 = ns::Func();
return 0;
}
Visual C++ has added a number of keywords in accordance with recommendations from the ANSI committee working on Standard C++. These are bool, true, false, mutable, typename, and explicit.
The bool data type
The new data type bool is special integer type that can have the values true or false only. It's a formal replacement for the informal #define and typedefs most C++ programmers have been using for years. Most conditional expressions, like (i ! =0) or (a < b) now return a bool rather than an int.
The mutable keyword
The mutable keyword is used to make an exception to the const status of an object. For example, imagine you have an Account class that needs to make a single big calculation at the beginning of all of its member functions. You decide to cache the result of this calculation in the object as a private member variable. The class looks something like this:
class Account
{
private:
// lots of data
float value;
bool valueok;
public:
void PrintStatement(CTime starttime);
float GetValue();
void CreditSalesRep(SalesRep& owner);
void Deposit (float amt);
// and so on
private:
void UpdateValue();
};
void Account::PrintStatement(CTime startttime)
{
if (!valueok)
{
UpdateValue();
valueok = true;
}
//rest of function
}
void Account::Deposit(float amt)
{
valueok=false;
//rest of function
}
// more functions
Typically, a class isn't written like this at first. Probably each function just called UpdateValue() every time, until someone noticed a problem with execution speed and decided to cache value in the object so that UpdateValue() wouldn't have to be called so often. This is a private implementation change and won't affect any of the rest of the code that uses this object.
There is one catch though: what if some of these member functions were const member functions? PrintStatement(), for example, doesn't really change an Account object at all, or at least it didn't until the decision to cache value. But the compiler will balk if you try to declare PrintAccount() as const now, because it changes valueok. If you move the line valueok = true to the bottom of UpdateValue(), and declare UpdateValue() to be a const member function, then PrintAccount() will compile, but the line valueok = true (and the line that sets value) will generate an error message when you compile UpdateValue().
In days of yore, programmers got around this with a process referred to as casting away const, which was dangerous and hard to read. Now you simply declare value and valueok to be mutable:
private:
// lots of data
mutable float value;
mutable bool valueok;
This says that the rules of const don't apply to these member variables, and they can be changed even in a const function. This enables you to preserve "conceptual constness" and keeps your programs more readable.
The typename keyword
This keyword belongs only in template code, and it means that the name you are about to give is the name of a type rather than the name of a variable. It can also replace the word class in a template definition.
The explicit keyword
You may have seen this keyword in the declaration of the auto_ptr class template earlier in this chapter. It can be used only on constructors, and is present only in the declaration, such as shown in the following:
class Foo
{
explicit Foo() {data=0;}
//fine
explicit Foo(int i); //fine
//rest of class
};
explicit Foo::Foo(int I) //not allowed
{
data = i;
}
Foo::Foo(int I) //fine, it's explicit because
//class declaration said so
{
data = i;
}
What does it mean if a constructor is explicit? It mans that it cannot be used to do the sort of invisible conversions that compilers do all the time. Consider this code snippet:
void func(Foo f);
//...
f(3);
//...
In order to compile this code, the compiler looks around for a way to make a Foo from an integer. You can imagine that it creates code something like this:
{
Foo compiler_temporary (3);
func(compiler_temporary);
}
If you add trace statements (see Chapter 24, "Improving Your Application's Performance,") to your constructor and destructor, you will see just how often the compiler makes implicit conversions like this. It happens a lot.
The explicit keyword says that this constructor is not to be used in these implicit conversions. Since the Foo constructor that takes an int is explicit, the compiler can't make the conversion and the call to func will not compile.
Why would you want to write code that will not compile? When compiling it would make things far worse. If Foo was a managed pointer, when compiler_temporary went out of scope the memory it pointed to would be deleted and your program would have a serious bug. If you want to call func, make a Foo object yourself and pass it down, and you avoid the bug.
You've covered a lot of ground in this chapter. The techniques covered here, although fairly new to C++ programming, are rapidly becoming must-know techniques for all C++ programmers. Exceptions and templates, especially, are things that you'll run into often when you examine other programmers' codeñor, more importantly, when you apply for that programmer's job.
For more information on related topics, please refer to the following chapters:
© 1997, QUE Corporation, an imprint of Macmillan Publishing USA, a Simon and Schuster Company.
![]()
{kind=link}
{kind=link}
{kind=link}