
![]()
![]()
![]()
Advanced Web applications often interface with database management systems. These database systems serve as repositories for large amounts of information that is collected and used by the application. For example, search sites maintain database information about the URLs that are searched. Online employee directories use databases to store contact information about employees. Web-based product catalogs maintain product descriptions and sales information in the form of a database.
In this chapter, you'll learn the fundamentals of database programming. You'll learn how relational databases work and how SQL is used to update and retrieve data from relational databases. You'll learn how databases are accessed and about the different types of drivers that can be used. When you finish this chapter, you'll have the background you need to begin Java database programming. Even if you are an experienced database programmer, you should still skim over this chapter. It contains useful introductory information on aspects of database programming with Java.
A database is a collection of data that is organized so that it may be easily searched and updated. The most important feature of a database is its organization, which supports both ease of use and efficient data retrieval. Consider an office that is organized with numbered file cabinets containing carefully labeled folders. Office information is stored by subject in specific folders that are kept in designated file cabinets. In such a system, every folder has its place and it is easy to find a particular folder.
Now consider a different environment where information is stored in folders, but the folders are haphazardly stored in boxes that are placed at seemingly random locations throughout an office building. How do you find a particular folder in such an environment? Where do you store a folder when you're finished with it?
The well-organized environment is analogous to a database. Information that is entered into a database is stored in specific locations within it. Because of the database's structure and organization (assuming the database is well designed), information can be easily retrieved. The database can be accessed remotely and is shared between many users.
The unorganized environment is analogous to a situation where information is stored in files on various user's computers. In such an environment, it is very hard to locate specific information. What file contains the information you need? Whose computer contains that file? Where is the computer located? Where is the file located in the user's file system?
A database server is a software program that manages databases, keeps them organized, and provides shared access to them. Database servers manage and organize databases at both a physical level and at a logical level. At a physical level, database servers store database information in specific locations within the particular files, directories, and disk volumes used by the server. The server keeps track of what information goes where so that you don't have to worry about it. The server is like a trusty office assistant--you can turn to and say, "Get me the file on..." and the assistant immediately retrieves the information you need and places it on your desk.
As previously mentioned, database servers also manage and organize information at a logical level. This logical level corresponds to the type of information that you store in a database. For example, you may have a database that stores the names, companies, email addresses, and phone numbers of your business contacts. The logical organization of the database could consist of a Contacts table with five columns: LastName, FirstName, Company, Email, and Phone. Specific contacts would be identified by rows of the table, as shown in Table 43.1.
| LastName | FirstName | Company | Phone | |
| Smith | Joe | XYZ, Corp. | joe@xyz.com | 123-456-7890 |
| Jones | Sally | UVW, Corp. | sally@uvw.com | 234-567-8901 |
| Woods | Al | RST, Corp. | al@rst.com | 345-678-9012 |
Although there are a number of different ways that databases can be logically organized, one particular organization, called the relational model, is the predominant method. The relational model was developed by E.F. Codd, a mathematician at IBM, during the late 1960s. Databases that adhere to the relational model are referred to as relational databases.
Relational databases are organized into tables that consist of rows and columns. As shown in Table 43.1, the columns of the table identify what type of information is contained in each row. The rows of the table contain specific records that have been entered in the database. The first row of Table 43.1 indicates that Joe Smith works for XYZ, Corp. and has email address joe@xyz.com and phone number 123-456-7890. (The table column headings are not counted as rows within the table.)
A relational database can have one table or 1,000 tables. The number of tables is only limited by the relational database server software and the amount of available physical storage. Some relational database servers, also referred to as relational database management systems (RDBMs), organize tables into schemas. A schema is a way of partitioning the tables of a database. Each table in a database belongs to exactly one schema. In a similar fashion, schemas are organized into catalogs. Each schema belongs to exactly one catalog, as shown in Figure 43.1. The purpose of schemas and catalogs is to organize tables into related groups and control access to the information contained in a database according to these groups.
NOTE: Not all relational database management systems support schemas and catalogs.
Access to information contained within tables is organized by keys. A key is a column or group of columns that uniquely identifies a row of a table. Keys are used to find a particular row within a table and to determine whether a new row is to be added to a table or to replace an existing row. Suppose that Table 43.1 was updated to include everybody in the world with an email address. What columns should we use as a key?
At first glance we may choose the LastName column. However, many people have the same last names. After further consideration, even if we chose the LastName, FirstName, and Company columns as our key, we would still run into problems with companies that had more than one Joe Smith working for them. The Email column would make a good key, though. If two people in the same company have the same name, they are still given unique email addresses, such as joe@xyz.com and joe.smith@xyz.com. (For the purpose of the example, we'll ignore the cases where people share the same email address or a person has more than one email address.)
Using Email as our key, we can easily manage our business contacts table. When we update the table, we can check to see if the Email column of the new row is already in the table. In this case, we can overwrite the existing row with new information. If the Email column of the new row is not in the table, we can add a new row to the table.
FIGURE 43.1. Tables are organized into schemas and catalogs.
When we design the tables of a database, how do we decide which information to put in which tables? Is it better to use one big table or lots of little tables?
The answer to these questions was provided by Codd in his paper on the relational data model. He described a process called normalization, which could be used to optimize the way that data is organized into tables. The purpose of normalization is to minimize the number of columns in database tables and promote data consistency. More tables with fewer columns are the result of normalization. Five levels of normalization are recognized. A database that is normalized to a particular level is said to be in normal form for that level (that is, first normal form through fifth normal form). The purpose of normalization is to remove redundant information from the database to simplify database updating and maintenance.
First normal form is the simplest and easiest to achieve. In it, duplicate columns of a table are eliminated. For example, consider Table 43.2, which keeps track of the taxes an individual paid in the years 1995 through 1997. The first column is the person's social security number and is the key for the table. The second through fourth columns represent the amount of tax the individual paid.
| SSN | Tax95 | Tax96 | Tax97 |
| 123-45-6789 | 10,000 | 11,000 | 11,500 |
| 234-56-7890 | 4,500 | 5,000 | 5,250 |
Because the second through fourth columns contain the same type of information, the table can be put into first normal form by organizing it as shown in Table 43.3.
| SSN | Year | Tax |
| 123-45-6789 | 95 | 10,000 |
| 123-45-6789 | 96 | 11,000 |
| 123-45-6789 | 97 | 11,500 |
| 234-56-7890 | 95 | 4,500 |
| 234-56-7890 | 96 | 5,000 |
| 234-56-7890 | 97 | 5,250 |
Subsequent normal forms are more complicated and harder to achieve. In most cases, achieving high levels of normalization is neither necessary nor desired. For example, databases that are put in fifth normal form have a high degree of consistency because redundant database columns are eliminated. However, this consistency comes at the expense of requiring more tables. The additional number of tables increases the storage space required by the database as a whole, and also increases the time to perform a database search. In general, database design is a trade-off between data consistency, database size, and database performance.
The Structured Query Language, or SQL (pronounced "sequel"), is a language for interacting with relational databases. It was developed by IBM during the '70s and '80s and standardized in the late '80s. The SQL standard has been updated over the years, and several versions currently exist. In addition, several database vendors have added product-specific extensions and variations to the language. The JDBC requires JDBC- compliant drivers to support the American National Standards Institute (ANSI) SQL-92 Entry Level version of the standard that was adopted in 1992.
SQL has many uses. When SQL is used to create or design a database, it is a data definition language. When it's used to update the data contained in a database, it is a data maintenance language. When it's used to retrieve information from a database, it is a data query language. We'll cover each of these uses in the following subsections.
NOTE: The following sections present enough SQL to get you started in database programming. For a complete description of SQL, check out the SQL Standards home page (http://www.jcc.com/sql_stnd.html) for links to standards and books on SQL. More sophisticated versions of the described SQL statements may be available. Consult the ANSI SQL standard for a complete description of each statement.
You can use SQL to define a database. For example, there are SQL statements for creating a database, creating tables and adding them to a database, updating the design of existing tables, and removing tables from a database. However, most database systems provide GUI tools for database definition, and these tools are far easier to work with than SQL for designing a database. For example, Microsoft Access 97 provides wizards that guide you through the entire process of creating a database and the tables that it contains. If you have access to a GUI-based database design tool, use it. It will save you time in creating your database and make it much easier to update. For those of you who do not have a GUI database design tool, I'll describe some of the basic SQL statements.
The CREATE DATABASE statement can be used to create a database:
CREATE DATABASE databaseName
Substitute the name of the table to be created for databaseName. For example, the following statement creates a database named MyDB:
CREATE DATABASE MyDB
NOTE: The CREATE DATABASE statement is not supported by all SQL implementations.
The CREATE TABLE statement creates a table and adds it to the database:
CREATE TABLE tableName (columnDefinition, ... ,columnDefinition)
Each columnDefinition is of the form
columnName columnType
The columnName is unique to a particular column in the table. The columnType identifies the type of data that may be contained in the table. Common data types are
NOTE: The Types class of java.sql identifies the SQL data types supported by Java. The get methods of the ResultSet interface are used to convert SQL data types into Java data types. The set methods of the PreparedStatement interface are used to convert Java types into SQL data types. These classes are covered in more detail in the next chapter.
The following is an example of a CREATE TABLE statement:
CREATE TABLE Contacts ( LastName char(30), FirstName char(20), Company char(50), Email char(40), Phone char(20) )
The preceding statement creates a Contacts table with the following columns:
The ALTER TABLE statement adds a row to an existing table:
ALTER TABLE tableName ADD (columnDefinition ... columnDefinition)
The row values of the newly added columns are set to NULL. Columns are defined as described in the previous section.
The following is an example of the ALTER TABLE statement that adds a column named Fax to the Contacts table:
ALTER TABLE Contacts ADD (Fax char(20))
The DROP TABLE statement deletes a table from the database:
DROP TABLE tableName
The dropped table is permanently removed from the database. The following is an example of the DROP TABLE statement:
DROP TABLE Contacts
The preceding statement removes the Contacts table from the database.
One of the primary uses of SQL is to update the data contained in a database. There are SQL statements for inserting new rows into a database, deleting rows from a database, and updating existing rows.
The INSERT statement inserts a row into a table:
INSERT INTO tableName VALUES (`value1', ..., `valuen')
In the preceding form of the INSERT statement, value1 through valuen identify all column values of a row. Values should be surrounded by single quotes.
The following is an example of the preceding form of the INSERT statement:
INSERT INTO Contacts VALUES ( `Zepernick', `Ken', `SAIZ, Inc.', `kenz@cts.com', `619-555-5555' )
The preceding statement adds Ken Zepernick to the Contacts table. All columns of Ken's row are filled in.
An alternative form of the INSERT statement may be used to insert a partial row into a table. The following is an example of this alternative form of the INSERT statement:
INSERT INTO tableName (columnName1, ..., columnNamem) VALUES (`value1', ..., `valuem')
The values of columName1 through columnNamem are set to value1 through valuem. The value of the other columns of a row are set to NULL.
An example of this form of the INSERT statement follows:
INSERT INTO Contacts (LastName, Email) VALUES ( `Deloach', `timdel@ix.netcom.com' )
The preceding statement adds a person with the last name of Deloach and the email address timdel@ix.netcom.com to the Contacts table. The person's FirstName, Company, and Phone fields are set to NULL.
The DELETE Statement
The DELETE statement deletes a row from a table:
DELETE FROM tableName [WHERE condition]
All rows of the table that meet the condition of the WHERE clause are deleted from the table. The WHERE clause is covered in a subsequent section of this chapter.
WARNING: If the WHERE clause is omitted, all rows of the table are deleted.
The following is an example of the DELETE statement:
DELETE FROM Contacts WHERE LastName = `Zepernick'
The preceding statement deletes all contacts with the last name of Zepernick from the Contacts table.
The UPDATE statement is used to update an existing row of a table:
UPDATE tableName SET columnName1 = `value1', ... ,columnNamen = `valuen' [WHERE condition]
All the rows of the table that satisfy the condition of the WHERE clause are updated by setting the value of the columns to the specified values. If the WHERE clause is omitted, all rows of the table are updated.
An example of the UPDATE statement follows:
UPDATE Contacts SET FirstName = `Tim' WHERE LastName = `Deloach'
The preceding statement changes the FirstName of all contacts with the LastName of Deloach to Tim.
The most important use of SQL for many users is for retrieving data contained in a database. The SELECT statement specifies a database query:
SELECT columnList1 FROM table1, ..., tablem [WHERE condition] [ORDER BY columnList2]
In the preceding syntax description, columnList1 and columnList2 are comma- separated lists of column names from the tables table1 through tablem. The SELECT statement returns a result set consisting of the specified columns of the table1 through tablem, such that the rows of these tables meet the condition of the WHERE clause. If the WHERE clause is omitted, all rows are returned.
NOTE: An asterisk (*) may replace columnList1 to indicate that all columns of the table(s) are to be returned.
The ORDER BY clause is used to order the result set by the columns of columnSet2. Each of the column names in the column list may be followed by the ASC or DESC keywords. If DESC is specified, the result set is ordered in descending order. Otherwise, the result set is ordered in ascending order.
An example of the SELECT statement follows:
SELECT * FROM Contacts
This statement returns all rows and columns of the Contact table.
The WHERE clause is a boolean expression consisting of column names, column values, relational operators, and logical operators. For example, suppose you have columns Department, Salary, and Bonus. You could use the following WHERE clause to match all employees in the Engineering department that have a salary over 100,000 and a bonus less than 5,000:
WHERE Department = `Engineering' AND Salary > `100000' AND Bonus < `5000'
Relational operators are =, !=, <, >, <=, and >=. Logical operators are AND, OR, and NOT.
NOTE: The ANSI SQL standard provides additional operators besides those listed in this section.
Most useful databases are accessed remotely. In this way, shared access to the database can be provided to multiple users at the same time. For example, you can have a single database server that is used by all employees in the accounting department.
In order to access databases remotely, users need a database client. A database client communicates to the database server on the user's behalf. It provides the user with the capability to update the database with new information or to retrieve information from the database. In this book, you'll learn to write Java applications and applets that serve as database clients. Your database clients talk to database servers using SQL statements. (See Figure 43.2.)
FIGURE 43.2. A database client talks to a database server on the user's behalf.
Database clients use database drivers to send SQL statements to database servers and to receive result sets and other responses from the servers. JDBC drivers are used by Java applications and applets to communicate with database servers. Officially, Sun says that JDBC is an acronym that does not stand for anything. However, it is associated with "Java database connectivity."
Many database servers use vendor-specific protocols. This means that a database client has to learn a new language to talk to a different database server. However, Microsoft established a common standard for communicating with databases, called Open Database Connectivity (ODBC). Until ODBC, most database clients were server- specific. ODBC drivers abstract away vendor-specific protocols, providing a common application programming interface to database clients. By writing your database clients to the ODBC API, you enable your programs to access more database servers. (See Figure 43.3.)
FIGURE 43.3. A database client can talk to many database servers via ODBC drivers.
So where does JDBC fit into this picture? It's not a competitor to ODBC yet, but it soon will be. JDBC provides a common database-programming API for Java programs. However, JDBC drivers do not directly communicate with as many database products as ODBC drivers. Instead, many JDBC drivers communicate with databases using ODBC. In fact, one of the first JDBC drivers was the JDBC-ODBC bridge driver developed by JavaSoft and Intersolv.
Why did JavaSoft create JDBC? What was wrong with ODBC? There are a number of reasons why JDBC was needed, which boil down to the simple fact that JDBC is a better solution for Java applications and applets:
JavaSoft created the Java-ODBC bridge driver as a temporary solution to database connectivity until suitable JDBC drivers were developed. The JDBC-ODBC bridge driver translates the JDBC API into the ODBC API and is used with an ODBC driver. The JDBC-ODBC bridge driver is not an elegant solution, but it allows Java developers to use existing ODBC drivers. (See Figure 43.4.)
FIGURE 43.4. The JDBC-ODBC bridge lets Java database clients talk to databases via ODBC drivers.
Since the release of the JDBC API, a number of JDBC drivers have been developed. These drivers provide varying levels of capability. As a service to Java developers, JavaSoft has classified JDBC drivers into the following four driver types:
FIGURE 43.5. A Type 2 JDBC driver uses a vendor-specific protocol and must be installed on client machines.
FIGURE 43.6. A Type 3 JDBC driver is a pure Java driver that uses a database access server to talk to database servers.
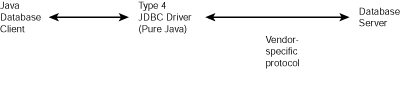
FIGURE 43.7. A Type 4 JDBC driver is a pure Java driver that uses a vendor- specific protocol to talk to database servers.
Of the four types of drivers, only Type 3 and Type 4 are pure Java drivers. This is important to support zero installation for applets, as you'll learn in Chapter 46, "Integrating Database Support into Web Applications." The Type 4 driver communicates with the database server using a vendor-specific protocol, such as SQLNet. The Type 3 driver makes use of a separate database access server. It communicates with the database access server using a standard network protocol, such as HTTP. The database access server communicates with database servers using vendor-specific protocols or ODBC drivers. The IDS JDBC driver that you'll use in Chapter 44, "Connecting to Databases with the java.sql Package," (and also in Chapters 45, "Using JDBC," and 46, "Integrating Database Support into Web Applications") is an example of a Type 3 driver.
In this chapter, you learned the basics of database programming. You learned how relational databases work and how SQL is used to update and retrieve data from relational databases. You also learned how databases are accessed and about the different types of drivers that can be used to access databases. In the following chapter, you'll learn how to use JDBC to connect to databases, execute SQL statements, and access the results of database queries.
© Copyright, Macmillan Computer Publishing. All rights reserved.
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
{kind=link}