by Krishna Sankar
This chapter is the introduction to a trilogy of chapters dealing with database access from a Java program. Standard relational data access is very important for Java programs because the Java applets by nature are not monolithic, all-consuming applications. As applets by nature are modular, they need to read persistent data from data stores, process the data, and write the data back to data stores for other applets to process. Monolithic programs could afford to have their own proprietary schemes of data handling. But as Java applets cross operating system and network boundaries, you need published open data access schemes.
The Java Database Connectivity (JDBC) of the Java Enterprise APIs is the first of such cross-platform, cross-database approaches to database access from Java programs. The Enterprise APIs also consist of Remote Method Invocation (RMI) and serialization APIs (for Java programs to marshal objects across namespaces and invoke methods in remote objects), Java IDL (Interface Definition Language) for communicating with CORBA, and other object-oriented systems.
This chapter introduces relational concepts, as well as Microsoft's Open Database Connectivity (ODBC). This chapter describes ODBC because of two major reasons:
The idea (and correctly so) of basing JDBC design on ODBC is that, as ODBC is popular with ISVs (Independent Software Vendors) as well as users, implementing and using JDBC will be easier for database practitioners who have earlier experience with ODBC. Also, Sun and Intersolv are developing a JDBC-ODBC bridge layer to take advantage of the ODBC drivers available in the market. So with the JDBC APIs and the JDBC-ODBC bridge, you can access and interact effectively with almost all databases from Java applets and applications.
Databases, as you know, contain data that's specifically organized. A database can be as simple as a flat file (a single computer file with data usually in a tabular form) containing names and telephone numbers of one's friends, or as elaborate as the worldwide reservation system of a major airline. Many of the principles discussed in this chapter are applicable to a wide variety of database systems.
Structurally, there are mainly three major types of databases:
During the 1970s and 1980s, the hierarchical scheme was very popular. This scheme treats data as a tree-structured system with data records forming the leaves. Examples of the hierarchical implementations are schemes like b-tree and multi-tree data access. In the hierarchical scheme, to get to data, users need to traverse down and up the tree structure. The most common relationship in a hierarchical structure is a one-to-many relationship between the data records, and it is difficult to implement a many-to-many relationship without data redundancy.
Relationships of the Database Kind
Establishing and keeping track of relationships between data records in database tables can be more difficult than maintaining human relationships! There are three types of data record relationships between records:
- One-to-one. One record in a table is related to at least one record in another table. The book/ISBN relationship (where a book has only one ISBN and an ISBN is associated with only one book) is a good example of a one-to-one relationship.
- One-to-many relationship. One record in a table could be associated with many records in another table. Purchase order/line items (where a purchase order can have many line items while one line item can be associated only with a single purchase order) is an example of a one-to-many relationship.
- Many-to-many relationships. Similar to the student/class relationships (where a student is taking many courses with different teachers in a semester, while a course has many students).
You may wonder how is a database going to remember these data relationships. They are usually done either by keeping a common element like the student ID/class ID in both the tables, or by keeping a record ID table (called the index) of both records. Modern databases have many other sophisticated ways of keeping data record relationships intact to weather updates, deletes, and so on.
During the '90s, the relational data access scheme came to the forefront. The relational scheme views data as rows of information. Each row contains columns of data, called fields. The main concept in the relational scheme is that the data is uniform. Each row contains the same number of columns. One such collection of rows and columns is called a table. Many such tables (which can be structurally different) form a relational database.
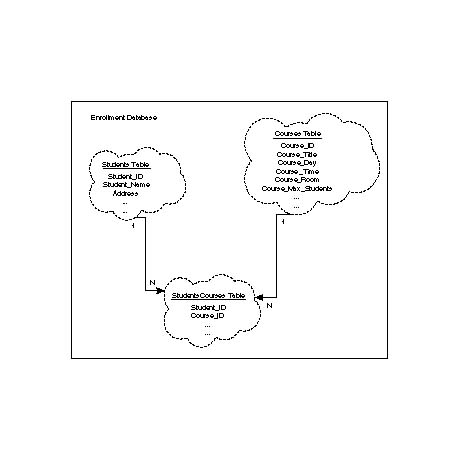
Figure 43.1 shows a sample relational database schema (or table layout) for an
enrollment database. In this example, the database consists of three tables: the
Students table which contains student information, the Courses table which has the
courses information, and the StudentsCourses table which has the student-course relation.
The student table has student ID, name, address, and so on; the courses table contains
the course ID, subject name or course title, term offered, location, and so on.
FIG. 43.1
A sample relational database schema for the Enrollment database.
Now that you have the student and course tables of data, how do you relate the tables? That is where the relational part of the relational database comes into the picture. To relate two tables, either the two tables will have a common column or you need to create a third table with two columns, one from the first table and the second from the second table.
Let's look at how this is done. In this example, to relate the student table with the course table, you need to make a new table StudentsCourse table which has two columns: Student_ID and Course_ID. Whenever a student takes a course, create a row in the StudentClass table with that Student_ID and the Course_ID. Thus, the table has the student and course relationship. If you want to find a list of students and the subjects they take, go to the StudentsCourses table, read each row, find the student name corresponding to the Student_ID, from the Course table find the course title corresponding to the Course_ID, and select the Student_Name and the Course_Title columns.
Once relational databases started becoming popular, database experts wanted a universal database language to perform actions on data. The answer was SQL, or Structured Query Language. SQL has grown into a mainstream database language that has constructs for data manipulation such as create, update, and delete; data definition such as create tables and column; security for restricting access to data elements, creating users and groups; data management including backup, bulk copy, and bulk update; and most importantly, transaction processing. SQL is used along with programming languages like Java, C++, and others, and is used for data handling and interaction with the back-end database management system.
NOTE: Each database vendor has its own implementation of the SQL. In the Microsoft SQL server, which is one of the client/server relational DBMS, the SQL is called the Transact/SQL, while the Oracle
NOTE: SQL is called the PL/SQL. SQL became an ANSI (American National Standards Institute) standard in 1986 and later was revised to become SQL-92. JDBC is SQL-92-compliant.
Just because a database consists of tables with rows of data does not mean that you are limited to view the data in the fixed tables in the database. Join is a process in which two or more tables are combined to form a single table. The join can be dynamic where two tables are merged to form a virtual table, or static where two tables are joined and saved for future reference. A static join is usually a stored procedure which can be invoked to refresh the saved table, and then the saved table is queried. Joins are performed on tables that have a column of common information. Conceptually, there are many types of joins which are discussed later in this section.
Before you dive deeper into joins, look at the following example, where you fill
the tables of the database schema in Figure 43.1 with a few records as shown in Tables
43.1, 43.2, and 43.3. These tables show only the relevant fields or columns.
| Student_ID | Student_Name |
| 1 | John |
| 2 | Mary |
| 3 | Jan |
| 4 | Jack |
| Course_ID | Course_Title |
| S1 | Math |
| S2 | English |
| S3 | Computer |
| S4 | Logic |
| Student_ID | Course_ID |
| 2 | S2 |
| 3 | S1 |
| 4 | S3 |
| Student_ID | Student_Name | Course_ID |
| 2 | Mary | S2 |
| 3 | Jan | S1 |
| 4 | Jack | S3 |
SELECT Students.Student_Name, StudentsCourses.Course_ID FROM Students, StudentsCourses WHERE Students.Student_ID = StudentsCourses.Student_ID
Outer Join An outer join between two tables (such as Table1 and Table2) occurs when the result table has all the rows of the first table and the common records of the second table. (The first and second table are determined by the order in the SQL statement.) If you assume a SQL statement with the FROM Table1,Table2 clause, in a left outer join, all rows of the first table (Table1) and common rows of the second table (Table2) are selected. In a right outer join, all records of the second table (Table2) and common rows of the first table (Table1) are selected. A left outer join with the Students Table and the StudentsCourses table creates Table 43.5.
| Student_ID | Student_Name | Course_ID |
| 1 | John | <null> |
| 2 | Mary | S2 |
| 3 | Jan | S1 |
| 4 | Jack | S3 |
The SQL statement for this outer join is as follows:
SELECT Students.Student_ID,Students.Student_Name,StudentsCourses.Course_ID
FROM {
oj c:\enrol.mdb Students
LEFT OUTER JOIN c:\enrol.mdb
StudentsCourses ON Students.Student_ID = StudentsCourses .Student_ID
}
The full outer join, as you may have guessed, returns all the records from both the tables merging the common rows as shown in Table 43.6.
| Student_ID | Student_Name | Course_ID |
| 1 | John | <null> |
| 2 | Mary | S2 |
| 3 | Jan | S1 |
| 4 | Jack | S3 |
| <null> | <null> | S4 |
SELECT Students.Student_Name
FROM {
oj c:\enrol.mdb Students
LEFT OUTER JOIN c:\enrol.mdb
StudentsCourses ON Students.Student_ID = StudentsCourses .Student_ID
}
WHERE (StudentsCourses.Course_ID Is Null)
General Discussion on Joins and SQL Statements
One more point: For equi-joins, as the column values are equal, you retrieved only one copy of the common column. Then the joins are called natural joins. When you have a non equi-join, you might need to retrieve the common columns from both tables.
Once an SQL statement reaches a database management system, the DBMS parses the SQL statement and translates the SQL statements to an internal scheme called a query plan to retrieve data from the database tables. This internal scheme generator, in all the client/server databases, includes an optimizer module. This module, which is specific to a database, knows the limitations and advantages of the database implementation.
In many databases--for example, the Microsoft SQL Server--the optimizer is a cost-based query optimizer. When given a query, this optimizer generates multiple query plans, computes the cost estimates for each (knowing the data storage schemes, page I/O, and so on), and then determines the most efficient access method for retrieving the data, including table join order and index usage. This optimized query is converted into a binary form called the execution plan, which is executed against the data to get the result. There are known cases where straight queries take hours to perform that when run through an optimizer, have resulted in an optimized query which is performed in minutes. All the major client/server databases have the query optimizer module built in which processes all the queries. A database system administrator can assign values to parameters such as cost, storage scheme, and so on, and fine-tune the optimizer.
ODBC (Open Database Connectivity) is one of the most popular database interfaces in the PC world and is slowly moving into all other platforms. ODBC is Microsoft's implementation of the X/Open and SQL Access Group (SAG) Call Level Interface (CLI) specification. ODBC provides functions to interact with databases from a programming language, including adding, modifying, and deleting data; and obtaining details about the databases, tables, views, and indexes.
TIP: This discussion on ODBC is relevant from the Java and JDBC point of view. It is instructive to note the similarities and differences between the JDBC and ODBC architectures. Also, the study of ODBC might give you some clues as to where JDBC is heading in the future.
The Application layer provides the GUI and the Business logic and is written in languages like Java, Visual Basic, and C++. The application uses the ODBC functions in the ODBC interface to interact with the databases.
The Driver Manager layer is part of the Microsoft ODBC. As the name implies, it manages various drivers present in the system including loading, directing calls to the right driver, and providing driver information to the application when needed. Because an application can be connected to more than one database (such as legacy systems and departmental databases), the Driver Manager makes sure that the right database management system gets all the program calls directed to it and that the data from the Data Source is routed to the application.
The Driver is the actual component which knows about specific databases. Usually the driver is assigned to a specific database like the Access Driver, SQL Server Driver, and Oracle Driver. The ODBC interface has a set of calls such as SQL statements, connection management, information about the database, and so on. It is the Driver's duty to implement all these function- alities. That means for some databases, the Driver has to emulate the ODBC interface functions not supported by the underlying DBMS. The Driver does the work of sending queries to the database, getting the data back, and routing the data to the application. For databases that are in local networked systems or on the Internet, the driver also handles the network communication.
In the context of ODBC, the Data Source can be a database management system or just the data store which usually is a set of files in the hard disk. The Data Source can be a very simple MS Access database for the expense data of a small company, or as exotic as a multi-server, multi-gigabyte data store of all the customer billing details of a telephone company. It could be handling a data warehouse or a simple customer list.
The major piece of an ODBC system is the driver which knows about the DBMS and communicates with the database. ODBC does not require the drivers to support all the functions in the ODBC interface. Instead, ODBC defines API and SQL grammar conformance levels for drivers. The only requirement is that when a driver conforms to a certain level, it should support all the ODBC defined functions on that level, regardless of whether the underlying database supports them.
NOTE: ODBC driver specification sets no upper limits of supported functionalities. That means a driver that conforms to Level 1 can and might support a few of the Level 2 functionalities. The driver is still considered Level 1 conformance, as it is not supporting all Level 2 functions. An application, however, can use the partial Level 2 support provided by that driver.
NOTE: Applications use the API calls like SQLGetFunctions and SQLGetInfo to get the functions supported by a driver.
| Type | Conformance Level | Description |
| API Conformance Levels | Core | All functions in SAG CLI specification. |
| Allocate and free connection, statement, and environment handles. | ||
| Prepare and execute SQL statements. | ||
| Retrieve the result set and information about the result set. | ||
| Retrieve error information. | ||
| Capability to commit and roll back transactions. | ||
| Level 1 | Extended Set 1 is Core API plus capabilities to send and retrieve partial data set, retrieve catalog information, get information about the driver and database capabilities, and more. | |
| Level 2 | Extended Set 2 is Level 1 plus capabilities to handle arrays as parameters, scrollable cursor, call transaction DLL, and more. | |
| SQL Grammar Conformance Levels | Minimum Grammar | Create Table and Drop Table functions in the Data Definition Language. |
| Select, Insert, Update, and Delete functions (simple) in the Data Manipulation Language, Simple expressions. | ||
| Core Grammar | Conformance to SAG CAE 1992 Specification Minimum grammar plus Alter Table, Create and Drop Index, and Create and Drop View for the DDL. | |
| Full SELECT statement capability for the DML. | ||
| Functions such as SUM and MAX in the expressions. | ||
| Extended Grammar | Adds capabilities like Outer Joins, positioned Update, Delete, more expressions, more data types, procedure calls, and so on to the Core grammar. |
The ODBC has a rich set of functions. They range from simple connect statements
to handling multi-result set stored procedures. All the ODBC functions have the "SQL"
prefix and can have one or more parameters which can be of type input (to the driver)
or output (from the driver). Let's look at the general steps required to connect
to an ODBC source, and then the actual ODBC command sequence.
Typical ODBC Steps
ODBC Command Sequence
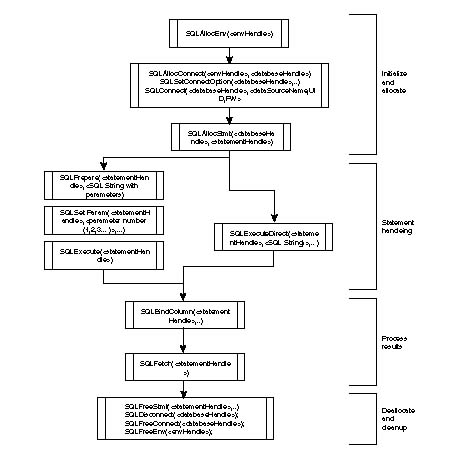
FIG. 43.3
ODBC Program Flow Schematic shows the ODBC program flow schematic for a typical program.
First, allocate statement handle using the SQLAllocStmt(<databaseHandle>, <statementHandle>). After the statement handle is allocated, you can execute SQL statements directly using the SQLExecDirect function, or prepare a statement using the SQLPrepare and then execute using the SQLExec function. You first bind the columns to program variables and then read these variables after a SQLFetch statement for a row of data. The SQLFetch returns SQL_NO_DATA_FOUND when there is no more data.
NOTE: JDBC also follows similar strategy for handling statements and data. But JDBC differs in the data binding to variables.
SQLFreeStmt(<statementHandle>, ..) SQLDisconnect(<databaseHandle>); SQLFreeConnect(<databaseHandle>); SQLFreeEnv(<envHandle>);
NOTE: In JDBC, the allocate statements and handles are not required.
Because Java is an object-oriented language, you get the connection object which then gives you the statement object.
As Java has automatic garbage collection, you don't need to free up handles, delete objects, and so on. Once an object loses scope, the JVM will reclaim the memory used by that object as a part of the automatic garbage collection.
A typical client/server system is at least a department-wide system, and most likely an organizational system spanning many departments in an organization. Mission-critical and line-of-business systems such as brokerage, banking, manufacturing, and reservation systems fall into this category. Most systems are internal to an organization, and also span the customers and suppliers. Almost all such systems are on a local area network (LAN), plus they have wide area network connections (WAN) and dial-in capabilities. With the advent of the Internet/intranet and Java, these systems are getting more and more sophisticated and are capable of doing business in many new ways.
Take the case of Federal Express. Their Web site can now schedule package pickups, track a package from pickup to delivery, and get delivery information and time. You are now in the threshold of an era where online commerce will be as common as shopping malls. Let's look at some of the concepts that drive these kinds of systems.
Most of the application systems will involve modules with functions for a front-end GUI, business rules processing, and data access through a DBMS. In fact, major systems like online reservation, banking and brokerage, and utility billing involve thousands of business rules, heterogeneous databases spanning the globe, and hundreds of GUI systems. The development, administration, maintenance, and enhancement of these systems involve handling millions of lines of code, multiple departments, and coordinating the work of hundreds if not thousands of personnel across the globe. The multi-tier system design and development concepts are applied to a range of systems from departmental systems to such global information systems.
NOTE: In the two- and three-tier systems, an application is logically divided into three parts:
- GUI, Graphical User Interface. Consists of the screens, windows, buttons, list boxes, and more.
- Business Logic. The part of the program that deals with the various data element interactions. All processing is done based on values of data elements, such as the logic for determining the credit limit depending on the annual income, or the calculation of Income Tax based on the tax tables, or a re-order point calculation logic based on the material usage belong into this category.
- DBMS. The Database management system that deals with the actual storage and retrieval of data.
Three-Tier Systems
Multi-Tier Systems The concept of transactions are an integral part of any client/server database.
A transaction is a group of SQL statements that update, add, and delete rows
and fields in a database. Transactions have an all or nothing property--either they
are committed if all statements are successful, or the whole transaction is rolled
back if any of the statements cannot be executed successfully. Transaction processing
assures the data integrity and data consistency in a database.
NOTE: JDBC supports transaction processing with the commit() and
rollback() methods. Also, JDBC has the autocommit() which when
on, all changes are committed automatically and if off, the Java program has to use
the commit() or rollback() methods to effect the changes to the
data.
Transactions
Transaction ACID Properties The characteristics of a transaction are described
in terms of the Atomicity, Consistency, Isolation, and Durability (ACID) properties.
A transaction is atomic in the sense that it is an entity. All the components
of a transaction happen or do not happen. There is no partial transaction. If only
a partial transaction can happen, then the transaction is aborted. The atomicity
is achieved by the commit() or rollback() methods.
A transaction is consistent because it does not perform any actions which violate the business logic or relationships between data elements. The consistent property of a transaction is very important when you develop a client/server system, because there will be many transactions to a data store from different systems and objects. If a transaction leaves the data store inconsistent, all other transactions also would potentially be wrong, resulting in a system-wide crash or data corruption.
A transaction is isolated because the results of a transaction are self-contained. They do not depend on any preceding or succeeding transaction. This related to a property called serializability which means the sequence of transactions are independent; in other words, a transaction does not assume any external sequence.
Finally, a transaction is durable, meaning the effects of a transaction
are permanent even in the face of a system failure. That means some form of permanent
storage should be a part of a transaction.
Distributed Transaction Coordinator
An application begins a transaction with the transaction manager and then starts transactions with the resource managers, registering the steps (enlisting) with the transaction manager.
The transaction manager keeps track of all enlisted transactions. The application, at the end of the multi-data source transaction steps, calls the transaction manager to either commit or abort the transaction.
When an application issues a commit command to the transaction manager, the DTC performs a two-phase commit protocol:
The Microsoft DTC is an example of very powerful next generation transaction coordinators from the database vendors. As more and more multi-platform, object-oriented Java systems are being developed, this type of transaction coordinator will gain importance. Already many middleware vendors are developing Java-oriented transaction systems.
A relational database query normally returns many rows of data. But an application program usually deals with one row at a time. Even when an application can handle more than one row--for example, by displaying the data in a table or spreadsheet format--it can still handle only a limited number of rows. Also, updating, modifying, deleting, or adding data is done on a row-by-row basis.
This is where the concept of cursors come in the picture. In this context, a cursor is a pointer to a row. It is like the cursor on the CRT--a location indicator.
Data Concurrency and Cursor Schemes
Different types of multi-user applications need different types of data sets in terms of data concurrency. Some applications need to know as soon as the data in the underlying database is changed. Such as the case with reservation systems, the dynamic nature of the seat allocation information is extremely important. Others such as statistical reporting systems need stable data; if data is in constant change, these programs cannot effectively display any results. The different cursor designs support the need for the various types of applications.
CAUTION:
An important point to remember when you think about cursors is the transaction isolation. If a user is updating a row, another user might be viewing the row in a cursor of his own. Data consistency is important here. Worse, the second user also might be updating the same row!
NOTE: The ResultSet in JDBC API is a Cursor. But it is only a forward scrollable cursor--this means you can only move forward using the getNext() method.
In the static cursor scheme, the data is read from the database once, and the data is in the snapshot recordset form. Because the data is a snapshot (a static view of the data at a point of time), the changes made to the data in the data source by other users are not visible. The dynamic cursor solves this problem by keeping live data, but this takes toll on network traffic and application performance.
The keyset driven cursor is the middle ground where the rows are identified at the time of fetch, and thus changes to the data can be tracked. Keyset driven cursors are useful when you implement a backward scrollable cursor. In a keyset-driven cursor, additions and deletions of entire rows are not visible until a refresh. When you do a backward scroll, the driver fetches the newer row if any changes are made.
NOTE: ODBC also supports a modified scheme, where only a small window of the keyset is fetched, called the mixed cursor, which exhibits the keyset cursor for the data window, and a dynamic cursor for the rest of the data. In other words, the data in the data window (called a RowSet) is keyset-driven, and when you access data outside the window, the dynamic scheme is used to fetch another keyset-driven buffer.
On the other hand, for online ordering systems or reservation systems, you need
a dynamic view of the system with row locks and views of data as changes are made
by other users. In such cases, you will use the dynamic cursor. In many of these
applications, the data transfer is small, and the data access is performed on a row-by-row
basis. For these online applications, aggregate data access is very rare.
Bookmark
Positioned Update/Delete
UPDATE/DELETE <Field or Column values etc.> WHERE CURRENT OF <cursor name>
The positioned update statement to update the fields in the current row is
UPDATE <table> SET <field> = <value> WHERE CURRENT OF <cursor name>
The positioned delete statement to delete the current row takes the form
DELETE <table> WHERE CURRENT OF <cursor name>
Generally, for this type of SQL statement to work, the underlying driver or the DBMS has to support updatability, concurrency, and dynamic scrollable cursors. But there are many other ways of providing the positioned update/delete capability at the application program level. Presently, JDBC does not support any of the advanced cursor functionalities. However, as the JDBC driver development progresses, I am sure there will be very sophisticated cursor management methods available in the JDBC API.
Data replication is the distribution of corporate data to many locations across the organization, and it provides reliability, fault-tolerance, data access performance due to reduced communication, and in many cases, manageability as the data can be managed as subsets.
As you have seen, the client/server systems span an organization, possibly its clients and suppliers; most probably in wide geographic location. Systems spanning the entire globe are not uncommon when you're talking about mission-critical applications, especially in today's global business market. If all the data is concentrated in a central location, it would be almost impossible for the systems to effectively access data and offer high performance. Also, if data is centrally located, in the case of mission-critical systems, a single failure will bring the whole business down. So, replicating data across an organization at various geographic locations is a sound strategy.
Different vendors handle replication differently. For example, the Lotus Notes groupware product uses a replication scheme where the databases are considered peers and additions/updates/deletions are passed between the databases. Lotus Notes has replication formulas that can select subsets of data to be replicated based on various criteria.
The Microsoft SQL server, on the other hand, employs a publisher/subscriber scheme where a database or part of a database can be published to many subscribers. A database can be a publisher and a subscriber. For example, the western region can publish its slice of sales data while receiving (subscribing to) sales data from other regions.
There are many other replication schemes from various vendors to manage and decentralize data. Replication is a young technology that is slowly finding its way into many other products.
{kind=link}
{kind=link}