by David W. Baker
Despite all of its other merits, the rapid embrace of Java by the computing community is primarily due to its powerful integration with Internet networking. The Internet revolution has forever changed the way the personal computer is used, empowering individuals to gather, share, and publish information in a vast resource with millions of participants. Building on top of this foundation, Java could be the next major revolution in computing.
The Java execution environment is designed so that applications can be easily written to efficiently communicate and share processing with remote systems. Much of this functionality is provided with the standard Java API within the java.net package.
This is the first of five chapters which will demonstrate clear and practical uses of the classes within java.net, explaining the programming concepts on which they are based. As a foundation of these discussions, the design of the Internet network protocol suite--TCP/IP--is illustrated within this chapter.
TCP/IP is a suite of protocols that interconnects the various systems on the Internet. TCP/IP provides for a common programming interface to diverse and foreign hardware. The suite supports the joining of separate physical networks implementing different network media. To wit, TCP/IP makes a diverse, chaotic, global network like the Internet possible.
Models provide useful abstractions of working systems, ignoring fine detail while enabling a clear perspective on global interactions. Models facilitate a greater understanding of functioning systems and also provide a foundation for extending that system. Understanding the models of network communications is an essential guide to learning TCP/IP fundamentals.
The network protocol architecture known as the Open Systems Interconnect (OSI) Reference Model is often used to describe network systems. The OSI scheme was one part of a larger project by the International Organization for Standardization (ISO). The OSI protocols never proved as successful as TCP/IP, making the Reference Model perhaps the most enduring aspect of this ISO endeavor.
The model consists of seven layers providing specific functionality. Each layer has defined characteristics, and together the whole enables network communication. The software implementation of such a layered model is appropriately termed a protocol stack.
The OSI model is illustrated in Figure 23.1. User applications insert information
into one layer and each specially encapsulates the data until the last is reached.
The information is then transmitted to the destination, sometimes having the layers
translated from the bottom up as the data is transported.
FIG. 23.1
The OSI Reference Model consists of seven layers.
The following layers have specific roles, each refraining from intruding into the domain of the other, all depending upon the others:
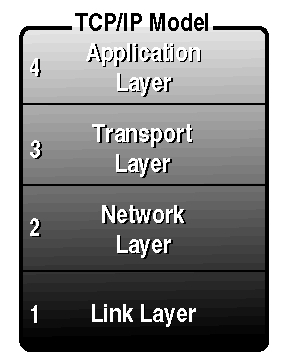
The OSI model informs an understanding of the TCP/IP communication architecture. When viewed as a layered model, TCP/IP is usually seen as being composed of four layers:
These layers are illustrated in Figure 23.2. Attempts to map these layers to the
OSI model are inexact and confuse matters, so this chapter refrains from such an
endeavor.
FIG. 23.2
The TCP/IP Network Model can be broken down into four layers.
As in the OSI model, each TCP/IP layer plays a specific role.
Application Layer
Transport Layer
Network Layer
Link Layer Three protocols are most commonly used within the TCP/IP scheme, and a closer
investigation of their properties is warranted. Understanding how these three protocols
(IP, TCP, and UDP) interact is critical to developing network applications.
IP is the keystone of the TCP/IP suite. All data on the Internet flows through
IP packets, the basic unit of IP transmissions. IP is termed a connectionless,
unreliable protocol. As a connec-tionless protocol, IP does not exchange control
information before transmitting data to a remote system--packets are merely sent
to the destination with the expectation that they will be treated properly. IP is
unreliable because it does not retransmit lost packets or detect corrupted data.
These tasks must be implemented by higher level protocols, such as TCP. IP defines a universal addressing scheme called IP addresses. An IP address
is a 32-bit number, and each standard address is unique on the Internet. Given an
IP packet, the information can be routed to the destination based upon the IP address
defined in the packet header. IP addresses are generally written as four numbers,
between 0 and 255, separated by a period (for example, 124.148.157.6). While a 32-bit number is an appropriate way to address systems for computers,
humans understandably have difficulty remembering them. Thus, a system called the
Domain Name System (DNS) was developed to map IP addresses to more intuitive
identifiers and vice versa. You can use www.netspace.org instead of 128.148.157.6. It is important to realize that these domain names are not used or understood
by IP. When an application wants to transmit data to another machine on the Internet,
it must first translate the domain name to an IP address using the DNS. A receiving
application can perform a reverse translation, using the DNS to return a domain name
given an IP address. There is not a one-to-one correspondence between IP addresses
and domain names: a domain name can map to multiple IP addresses, and multiple IP
addresses can map to the same domain name.
NOTE: Even more important to note is that the entire body of DNS data cannot
be trusted. Varied systems through the world are responsible for maintaining DNS
records. DNS servers can be tricked, and servers can be set up that are populated
with false information. In fact, a security hole in early Java implementations was
created by an inappropriate trust of the DNS.
Most Internet applications use TCP to implement the transport layer. TCP provides
a reliable, connection-oriented, continuous-stream protocol. The implications of
these characteristics are:
Because of these characteristics, it is easy to see why TCP would be used by most
Internet applications. TCP makes it very easy to create a network application, freeing
you from worrying how the data is broken up or about coding error correction routines.
However, TCP requires a significant amount of overhead and perhaps you might want
to code routines that more efficiently provide reliable transmissions, given the
parameters of your application. Furthermore, retransmission of lost data may be inappropriate
for your application, because such information's usefulness may have expired. In
these instances, UDP serves as an alternative, described in the following section,
"User Datagram Protocol (UDP)." An important addressing scheme which TCP defines is the port. Ports separate
various TCP communications streams that are running concurrently on the same system.
For server applications, which wait for TCP clients to initiate contact, a specific
port can be established from where communications will originate. These concepts
come together in a programming abstraction known as sockets. See "TCP Socket Basics," Chapter 24
UDP is a low-overhead alternative to TCP for host-to-host communications.
In contrast to TCP, UDP has the following features:
For some applications, UDP is more appropriate than TCP. For instance, with the
Network Time Protocol (NTP), lost data indicating the current time would be invalid
by the time it was retransmitted. In a LAN environment, Network File System (NFS)
can more efficiently provide reliability at the application layer and thus uses UDP. As with TCP, UDP provides the addressing scheme of ports, allowing for many applications
to simultaneously send and receive datagrams. UDP ports are distinct from TCP ports.
For example, one application can respond to UDP port 512 while another unrelated
service handles TCP port 512.
While IP addresses uniquely identify systems on the Internet, and ports identify
TCP or UDP services on a system, URLs provide a universal identification scheme at
the application level. Anyone who has used a Web browser is familiar with seeing
URLs, though their complete syntax may not be self-evident. URLs were developed to
create a common format of identifying resources on the Web, but they were designed
to be general enough so as to encompass applications that predated the Web by decades.
Similarly, the URL syntax is flexible enough so as to accommodate future protocols.
The primary classification of URLs is the scheme, which usually corresponds
to an application protocol. Schemes include http, ftp, telnet,
and gopher. The rest of the URL syntax is in a format that depends upon the
scheme. These two portions of information are separated by a colon: Thus, while mailto:dwb@netspace.org indicates "send mail to user
dwb at the machine netspace.org," ftp://dwb@netspace.org/
means "open an FTP connection to netspace.org and log in as user dwb."
Most URLs conform to a general format that follows this pattern: Scheme-name is an URL scheme such as HTTP, FTP, or Gopher. Host is the domain
name or IP address of the remote system. Port is the port number on which the service
is listening; because most application protocols define a standard port, unless a
non-standard port is being used, the port and the colon which delimits it from the
host are omitted. File-info is the resource requested on the remote system, which
often is a file. However, the file portion may actually execute a server program
and it usually includes a path to a specific file on the system. The internal-reference
is usually the identifier of a named anchor within an HTML page. A named anchor
allows a link to target a particular location within an HTML page. Usually this is
not used, and this token with the # character that delimits it is omitted. Realize that this general format is very much an over-simplification which only
agrees with common use. For more complete information on URLs, read the following
resource:
Java provides a very powerful and elegant mechanism for creating network client
applications, allowing you to use relatively few statements to obtain resources from
the Internet. The java.net package contains the sources of this power, the URL
and URLConnection classes.
NOTE: The Security Manager of Java browsers generally prohibits applets
from opening a network connection to a machine other than the one from which the
applet was downloaded. This security feature significantly limits what applets can
accomplish. This holds true for all Java networking described in this and subsequent
chapters. Java applications, however, are under no such restrictions.
This class allows you to easily create a data structure containing all of the
necessary information to obtain the remote resource. Once an URL object
has been created, you can obtain the various portions of the URL, according to the
general format. The URL object also allows you to obtain the remote data. The URL class has four constructors: The first constructor is the most commonly used and allows you to create an URL
object with a simple declaration like: The second and third constructors allow you to specify explicitly the various
portions of the URL. The last constructor enables you to use relative URLs. A relative
URL only contains part of the URL syntax; the rest of the data is completed from
the URL to which the resource is relative. This will often be seen in HTML pages,
where a reference to merely more.html means "get more.html
from the same machine and directory where the current document resides." Here are examples of these constructors: The first three statements create URL objects that all refer to the Yahoo!
home page, while the fourth creates a reference to "text/suggest.html"
relative to Yahoo's home page (such as http://www.yahoo.com/text/suggest.html).
All of these constructors throw a MalformedURLException, which you will
generally want to catch. The example shown later in Listing 23.1 illustrates this.
Note that once you create an URL object, you can change to which resource
it points. To accomplish this, you must create a new URL object.
Now that you've created an URL object, you will want to actually obtain
some useful data. There are two main avenues of so doing: reading directly from the
URL object or obtaining an URLConnection instance from it. Reading directly from the URL object requires less code, but is much
less flexible, and it only allows a read-only connection. This is limiting, as many
Web services allow you to write information that will be handled by a server application.
The URL class has an openStream() method which returns an InputStream
object through which the remote resource can be read byte-by-byte. Handling data as individual bytes is cumbersome, so you will often want to embed
the returned InputStream within a DataInputStream object, allowing
you to read the input line-by-line. This coding strategy is often referred to as
using a decorator, as the DataInputStream decorates the InputStream
by providing a more specialized interface. The following code fragment obtains an
InputStream directly from the URL object and then decorates that
stream: Another more flexible way of connecting to the remote resource is by using the
openConnection() method of the URL class. This method returns an
URLConnection object that provides a number of very powerful methods that
you can use to customize your connection to the remote resource. For example, unlike the URL class, an URLConnection allows you
to obtain both an InputStream and an OutputStream. This has a significant
impact upon the HTTP protocol, whose access methods include both GET and
POST. With the GET method, an application merely requests a resource
and then reads the response. The POST method is often used to provide input
to server applications by requesting a resource, writing data to the server with
the HTTP request body, and then reading the response. In order to use the POST
method, you can write to an OutputStream obtained from the URLConnection
prior to reading from the InputStream. If you read first, the GET
method will be used and a subsequent write attempt will be invalid. The following code fragment demonstrates using an URLConnection object
to contact a remote server application using the HTTP POST method by writing
to an OutputStream decorated by a PrintStream instance. www.javasoft.com
makes a CGI server application available to test out these methods. The code connects
to a CGI application which reverses the POST data and then reads the reversed
data from a decorated InputStream. After reading this overview of the URL and URLConnection classes,
you may begin to suspect that the methods of these classes are designed with the
HTTP protocol in mind. If you look at the complete class specifications, this notion
is confirmed. Though the http scheme is only one of many classifications
of URLs, these classes are very HTTP-centric. HTTP is likely to be the most used standard protocol for your communications on
the Web and Internet, so this is not a significant concern. You should be aware,
however, that many of these methods are useful only when working with HTTP URLs.
Now that you've learned the basics of Java networking, it would be nice to do
something actually useful. The AltaVista search engine provides a very powerful way
of searching for documents on the Web; however, it is designed to only return a few
hits at a time to optimize performance. As other astute and sagacious programmers
have pointed out, developing a small client to automatically request all of the search
results and then present them at once is very useful. The AltaVistaList Java application
does just that.
TIP: AltaVista is a powerful search engine that allows you to find documents
on the Web. The AltaVista home page is available at: http://www.altavista.digital.com/
Listing 23.1 shows the entire code of the AltaVistaList application. When executed
with a series of keywords, it returns an HTML page that contains all of the hits
returned by AltaVista.
CAUTION:
The main() Method: Starting the Application Note that because this is a static method, it is not invoked through an instance
of URLConnection. Instead, the method is invoked through the class itself.
This method indicates that all HTTP requests should specify the "User-Agent"
field as being equal to a string that identifies this application. The HTTP User-Agent
is a field that Web clients use to tell servers their program name, allowing servers
to keep track of what clients are visiting the site. For instance, Netscape browsers
send a User-Agent field that includes "Mozilla," while the Internet Explorer
sends "Explorer." Unfortunately, as of the writing of this chapter, the
JDK has yet to implement this method, and the User-Agent remains the default Java<version>.
This code has been left in with the assumption that the JDK will soon complete its
implementation of the Java API. The constructor then enters an infinite loop. In this loop, it calls the getPage()
method with an URL of a page to receive. This URL is the URL of the AltaVista search
engine appended by a question mark, the query returned by createQuery(),
and a number from where the hit list should start. AltaVista lists hits ten at a
time, and the startHits counter allows the AltaVistaList application to
increment throughout the entire list of hits. The returned page is passed to getHits(),
which strips out the hits from the rest of the HTML page. If what remains is a null
String reference, the application breaks from the loop. Otherwise, it appends
the data to a StringBuffer and then increments the startHits counter
to set up for retrieving the next ten hits. While this appears confusing, this is merely a set of five parameters separated
by ampersands. what=web tells AltaVista to search its index of Web pages.
fmt=c asks for output to be returned in a compact format, facilitating parsing
and efficient presentation. pq=q indicates that you are doing a simple query
using the basic syntax language. q= identifies your search string, which
must be encoded in the URL format, encoding spaces, and other special characters.
Finally, stq= tells AltaVista which query result item to start from when
returning its data. AltaVista returns results ten at a time, and stq= allows
you to obtain the results after the first ten. createQuery() takes an array of String objects and then appends
the entire array to a StringBuffer object. The contents of each String are
separated by a space. Another static method is used, this time encode()
from the URLEncoder class. This is a very useful method: The URLEncoder.encode() static method takes a String as an argument
and returns a corresponding String that is in URL encoded format. This format
allows spaces and other special characters to be encapsulated within an URL. createQuery() then returns the appropriate query with this encoded String
embedded. Note that createQuery() omits the number for the stq=
parameter, as that information is appended within the main() method. The getHits() Method: Parsing Out the Hits Otherwise, the method pares down the HTML page to a substring and iterates through
that data. Each hit should be a new line starting with <a href=. While
this is the case, the method keeps looping until it comes to the end of the data.
Each line that it encounters indicates a new hit has been found, and the method increments
an instance variable used to keep track of the total number of hits. Once completed,
the method returns the String containing the hits. Running AltaVistaList java AltaVistaList Java URL
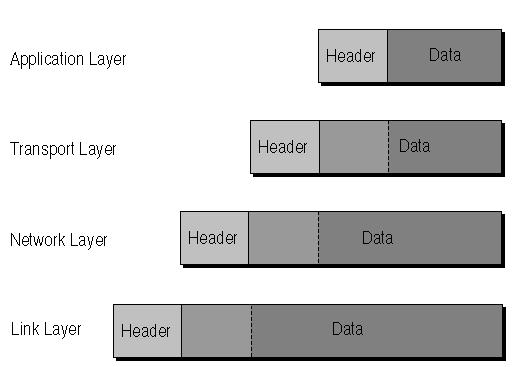
FIG. 23.3
As data moves through the TCP/IP layers, it is encapsulated.
TCP/IP Protocols
Internet Protocol (IP)
Transmission Control Protocol (TCP)
User Datagram Protocol (UDP)
Uniform Resource Locator (URL)
URL Syntax
scheme-name:scheme-info
General URL Format
scheme-name://host:port/file-info#internal-reference
Java and URLs
The URL Class
public URL(String spec) throws MalformedURLException;
public URL(String protocol, String host, String file)
throws MalformedURLException;
public URL(String protocol, String host, int port, String file)
throws MalformedURLException;
public URL(URL context, String spec)
throws MalformedURLException;
URL myURL = new URL("http://www.yahoo.com/");
URL firstURLObject - new URL("http://www.yahoo.com/");
URL secondURLObject = new URL("http","www.yahoo.com","/");
URL thirdURLObject = new URL("http","www.yahoo.com",80,"/");
URL fourthURLObject = new URL(firstURLObject,"text/suggest.html");
Connecting to an URL
URL whiteHouse = new URL("http://www.whitehouse.gov/");
InputStream undecoratedInput = whiteHouse.openStream();
DataInputStream decoratedInput = new DataInputStream(undecoratedInput);
URL reverseURL =
new URL("http://www.javasoft.com/cgi-bin/backwards");
URLConnection reverseConn = reverseURL.openConnection();
PrintStream output =
new PrintStream(reverseConn.getOutputStream());
DataInputStream input =
new DataInputStream(reverseConn.getInputStream());
output.println("string=TexttoReverse");
String reversedText = input.readLine();
HTTP-Centric Classes
An Example--Customized AltaVista Searching
When designing this application, first consider what public methods this class should
have. It needs:
Note that this application is limited by the specific mechanisms AltaVista uses to
receive and present information. These mechanisms are not guaranteed to remain static--thus,
if AltaVista changes, this program fails.
Listing 23.1
import java.net.*; // Import the names of the classes
import java.io.*; // to be used.
/**
* This application creates a single, concise HTML page
* of hits from the AltaVista search engine given a
* search string.
* @author David W. Baker
* @version 1.1
*/
public class AltaVistaList {
private static final String AGENT_NAME =
"java-alta-search";
private static final String AGENT_VERSION = "1.0";
private static final String SEARCH_URL =
"http://www.altavista.digital.com/cgi-bin/query";
private int totalHits = 0;
private StringBuffer outputList = new StringBuffer();
/**
* This starts the application.
* @param args Program arguments - the search string.
*/
public static void main(String[] args) {
if (args.length == 0) {
System.out.println(
"Usage: AltaVistaList search string");
System.exit(1);
}
AltaVistaList runApp = new AltaVistaList(args);
runApp.printOutput(System.out);
System.exit(0);
}
/**
* This constructor connects to AltaVista and obtains
* all of the relevant hits.
* @param args The search tokens.
*/
public AltaVistaList(String[] args) {
String hitData; // Store incoming data.
int startHits = 0; // Get the next 10 hits from here.
String searchSyntax = createQuery(args);
URLConnection.setDefaultRequestProperty("User-Agent",
AGENT_NAME + "/" + AGENT_VERSION);
while (true) {
hitData = getPage(SEARCH_URL + "?" + searchSyntax +
startHits); // Go get a page of hits.
hitData = getHits(hitData); // Extract the hits.
// If there were no hits in the page, hitData will
// be null. If there were hits, append them to
// the outputList, increment to the next 10 hits,
// and go through the loop again.
if (hitData != null) {
outputList.append(hitData + "\n");
startHits += 10;
// Otherwise, break from the loop.
} else {
break;
}
}
}
/**
* This method builds an AltaVista search query
* string.
* @param searchTokens An array of search tokens.
* @return The search query string built.
*/
protected String createQuery(String[] searchTokens) {
StringBuffer searchString = new StringBuffer();
// Apend the tokens to a single string.
for(int index = 0; index < searchTokens.length;
index++) {
searchString.append(searchTokens[index]);
// Add a space if there's another token coming up.
if (index < searchTokens.length-1) {
searchString.append(" ");
}
}
// URL encode the string.
String encodedSearchString =
URLEncoder.encode(searchString.toString());
// Return the proper query string.
return "what=web&fmt=c&pg=q&q=" + encodedSearchString
+ "&stq=";
}
/**
* This method obtains a page from the Web.
* @param url The URL of the page to obtain.
* @return The page obtained.
*/
protected String getPage(String url) {
// A buffer for the incoming page.
StringBuffer page = new StringBuffer();
String nextLine; // The next line in the input stream.
try {
URL urlObject = new URL(url);
URLConnection agent = urlObject.openConnection();
DataInputStream input =
new DataInputStream(agent.getInputStream());
// While readLine() doesn't return null, append
// then next line to the buffer.
while((nextLine = input.readLine()) != null) {
page.append(nextLine+"\n");
}
input.close();
} catch(MalformedURLException excpt) {
System.out.println("Badly formed URL: " + excpt);
} catch(IOException excpt) {
System.out.println("Failed I/O: " + excpt);
}
// Convert the buffer to a string and return.
return page.toString();
}
/**
* This method extracts the list of hits from a returned
* AltaVista results page.
* @param hitPage The page returned from AltaVista.
* @return The list of hits.
*/
protected String getHits(String hitPage) {
int first,last; // Begin/end of a substring.
int notFound = -1; // Not found return for indexOf().
String hitSection = null; // The hits part of page.
// Go to the first "<a href=" after "<pre>".
first = hitPage.indexOf("<pre>") + "<pre>".length();
first = hitPage.indexOf("<a href=",first);
// End pointer at "</pre>".
last = hitPage.indexOf("</pre>");
// If our beginning is after our end, return.
if (last < first) {
return hitSection;
}
// If neither substring is found, return.
if (first == notFound || last == notFound) {
System.err.println("Bad search page format");
return hitSection;
}
// Cut out the substring.
hitSection = hitPage.substring(first,last);
first = last = 0;
totalHits += 1; // Found one hit.
// Go through the page line by line.
while((last = hitSection.indexOf("\n",first))
!= notFound) {
// Find the next "<a href=" which should be
// immediately after the \n.
first = hitSection.indexOf("<a href=",last);
// If it's not, return the current substring.
if (first != (last+1)) {
return hitSection.substring(0,last);
// Otherwise, another hit has been found.
} else {
totalHits += 1;
}
}
return hitSection; // Return the substring.
}
/**
* This method prints the list of hits obtained from
* AltaVista.
* @param sendOutput Where to print the output.
*/
public void printOutput(PrintStream sendOutput) {
sendOutput.print("<!DOCTYPE HTML PUBLIC \"-//IETF//" +
"DTD HTML//EN\">\n<HTML>\n<HEAD>\n<TITLE>" +
AGENT_NAME + "</TITLE>\n</HEAD>\n<BODY>\n<H1>" +
"Search Results</H1>\n<P><STRONG>Total number of " +
"hits: " + totalHits + "</STRONG></P>\n<PRE>\n" +
outputList + "</PRE>\n</BODY>\n</HTML>\n");
}
}
The AltaVistaList Constructor URLConnection.setDefaultRequestProperty("User-Agent",
AGENT_NAME + "/" + AGENT_VERSION);
The createQuery() Method: Building the Query String what=web&fmt=c&pg=q&q=<search string>&stq=<n>
String encodedSearchString =
URLEncoder.encode(searchString.toString());
The getPage() Method: Retrieving a Web Page
The printOutput Method: Displaying the Results
{kind=link}
{kind=link}
{kind=link}