by Eric Ries
Joe Programmer is a Java developer for Company X. His distributed sales application is a huge success in California, where his company is based, mainly because he follows good object-oriented design and implementation: keeping his objects portable, reusable, and independent. One day, Company X decides to start selling its product in Japan. Joe Programmer, who does not know Japanese, gets a Java-literate translator to go through his code and make all the necessary changes using some custom Japanese language character set that Joe doesn't really understand. But he happily compiles this Japanese-language version of his code and sends it off to Japan, where it is a big success. Encouraged by this result, Company X starts moving into other markets; France and Canada are next. To Joe's dismay, he finds that he has to maintain several completely different versions of his code because France and Canada, although they share a common language, have a completely different culture! Poor Joe now has five compiled versions of his code: an American English, Japanese, French, Canadian French, and Canadian English. Now, when he makes even the slightest change to his code, he has to make the same change five times, and then hire several translators to make language changes directly in the source code. Clearly, Joe is in an unacceptable situation.
In the previous scenario, Joe Programmer is said to have written a myopic program, one that is only suited to one locale. A locale is a region (usually geographic, but not necessarily so) that shares customs, culture, and language. Each of the five versions of Joe's program was localized for one specific locale, and was unusable outside that locale without major alteration. This violates the fundamental principle of OOP design, because Joe's program is no longer portable or reusable. The process of isolating the culture-dependent code (text, pictures, and so on) from the language-independent code (the actual functionality of the program), is called Internationalization. Once a program has been through this process, it can easily be adapted to any Locale with a minimum amount of effort. Version 1.1 of the Java language provides built-in support for internationalization, which makes writing truly portable code easy.
Java 1.1 introduces several changes to the Java language which support internationalization. In the past, writing internationalized code required extra effort and was substantially more difficult than writing myopic code. One of the design goals of Java 1.1 was to reverse this paradigm. Java seeks to make writing internationalized code easier than its locale-specific counterpart. The changes introduced with Java 1.1 mainly affect three packages:
A Locale object encapsulates information about a specific locale. This consists of just enough information to uniquely identify the locale's region. When a locale-sensitive method is passed a Locale object as a parameter, it will attempt to modify its behavior for that particular locale. A Locale is initialized with a language code, a country code, and an optional "variant" code. These three things define a region, although you need not specify all three. For example, you could have a Locale object for American English, California variant. If you ask the Calendar class what the first month of the year is, the Calendar will try and find a name suitable for Californian American English. Since month names are not affected by what state you are in, the Calendar class has no built-in support for Californian English, and it tries to find a best fit. It will next try American English, but since month names are constant in all English-speaking countries, this will fail as well. Finally, the Calendar class will return the month name that corresponds to the English Locale. This best-fit lookup procedure allows the programmer complete control over the granularity of internationalized code.
You create a Locale object using the following syntax:
Locale theLocale = new Locale("en", "US");
where "en" specifies English, and "US" specifies United States. These two-letter codes are used internally by Java programs to identify languages and countries. They are defined by the ISO-639 and ISO-3166 standards documents respectively. More information on these two documents can be found at:
http://www.ics.uci.edu/pub/ietf/http/related/iso639.txt
http://www.chemie.fu-berlin.de/diverse/doc/ISO_3166.html
Currently, the JDK supports the following language and country combinations in all of its locale-sensitive classes, such as Calendar, NumberFormat, and so on. This list may change in the future, so be sure to check the latest documentation (see Table 16.1).
| Locale | Country | Language |
| da_DK | Denmark | Danish |
| DE_AT | Austria | German |
| de_CH | Switzerland | German |
| de_DE | Germany | German |
| el_GR | Greece | Greek |
| en_CA | Canada | English |
| en_GB | United Kingdom | English |
| en_IE | Ireland | English |
| en_US | United States | English |
| es_ES | Spain | Spanish |
| fi_FI | Finland | Finnish |
| fr_BE | Belgium | French |
| fr_CA | Canada | French |
| fr_CH | Switzerland | French |
| fr_FR | France | French |
| it_CH | Switzerland | Italian |
| it_IT | Italy | Italian |
| ja_JP | Japan | Japanese |
| ko_KR | Korea | Korean |
| nl_BE | Belgium | Dutch |
| nl_NL | Netherlands | Dutch |
| no_NO | Norway | Norwegian (Nynorsk) |
| no_NO_B | Norway | Norwegian (Bokmål) |
| pt_PT | Portugal | Portuguese |
| sv_SE | Sweden | Swedish |
| tr_TR | Turkey | Turkish |
| zh_CN | China | Chinese(Simplified) |
| zh_TW | Taiwan | Chinese (Traditional) |
Locale theLocale = new Locale("en", "US", "CA_WIN");
Remember that methods that do not understand this particular variant will try and find a "best fit" match, in this case probably "en_US".
The two-letter abbreviations listed here are not meant to be displayed to the user; they are meant only for internal representation. For display, use one of the Locale methods listed in Table 16.2.
| Method Name | Description |
| getDisplayCountry() | |
| getDisplayCountry(Locale) | Country name, localized for default Locale, or specified Locale |
| getDisplayLanguage() | |
| getDisplayLanguage(Locale) | Language name, localized for default Locale, or specified Locale |
| getDisplayName() | |
| getDisplayName(Locale) | Name of the entire locale, localized for default Locale, or specified Locale |
| getDisplayVariant() | |
| getDisplayVariant(Locale) | Name of the Locale's variant. If the localized name is not found, this will return the variant code. |
Locale.setDefault( new Locale("en", "US") ); //Set default Locale to American English
Locale japanLocale = new Locale("ja:, "JP"); //Create locale for Japan
System.out.println( japanLocale.getDisplayLanguage() );
System.out.println( japanLocale.getDisplayLanguage( Locale.FRENCH ) );
This code fragment will print out the name of the language used by japanLocale. In the first case, it is localized for the default Locale, that has been conveniently set to American English. The output would therefore be "Japanese." The second print statement will localize the language name for display in French, which yields the output "Japonais." All of the Locale "display" methods use this same pattern. Almost all Internationalization API methods allow you to explicitly control the Locale used for localization, but, in most cases, you'll just want to use the default Locale.
Another thing to note in the above example is the use of the static constant Locale.FRENCH. The Locale class provides a number of these useful constants, each of which is a shortcut for the corresponding Locale object. A list of these objects is shown in Table 16.3:
| Constant Name | Locale | Shortcut for |
| CANADA | English Canada | new Locale("en", "CA", "") |
| CANADA_FRENCH | French Canada | new Locale("fr", "CA", "") |
| CHINA SCHINESE PRC | Chinese (Simplified) | new Locale("zh", "CN", "") |
| CHINESE | Chinese Language | new Locale("zh", "", "") |
| ENGLISH | English Language | new Locale("en", "", "") |
| FRANCE | France | new Locale("fr", "FR", "") |
| FRENCH | French Language | new Locale("fr", "", "") |
| GERMAN | German Language | new Locale("de", "", "") |
| GERMANY | Germany | new Locale("de", "DE", "") |
| ITALIAN | Italian Language | new Locale("it", "", "") |
| ITALY | Italy | new Locale("it", "IT", "") |
| JAPAN | Japan | new Locale("jp", "JP", "") |
| JAPANESE | Japanese Language | new Locale("jp", "", "") |
| KOREA | Korea | new Locale("ko", "KR", "") |
| KOREAN | Korean Language | new Locale("ko", "", "") |
| TAIWAN TCHINESE | Taiwan (Traditional Chinese) | new Locale("zh", "TW", "") |
| UK | Great Britain | new Locale("en", "GB", "") |
| US | United States | new Locale("en", "US", "") |
The Locale class allows you to easily handle Locale-sensitive
methods. However, most programs (especially applets and GUI-based applications) require
the use of Strings, data, and other resources that also need to be localized. For
instance, most GUI programs have "OK" and "Cancel" buttons. This
is fine for the United States, but other locales require different labels for these
buttons. In Germany, for instance, you might use "Gut" and "Vernichten"
instead. Traditionally, information such as this was included in the source code
of an application, which, as Programmer Joe found out earlier, can lead to many problems
when trying to simultaneously support many localized versions of one program. To
solve this problem, Java provides a way to encapsulate this data into objects which
are loaded by the VM upon demand. These objects are called ResourceBundles.
ResourceBundles--Naming conventions
ResourceBundle getResourceBundle(String baseName, Locale locale, ClassLoader loader)
This method uses the specified ClassLoader to search for a class that matches baseName, plus certain attributes of the specified Locale. There is a very specific search pattern that is used to find the "closest match" to the Bundle you request:
bundleName + "_" + localeLanguage + "_" + localeCountry + "_" + localeVariant bundleName + "_" + localeLanguage + "_" + localeCountry bundleName + "_" + localeLanguage bundleName + "_" + defaultLanguage + "_" + defaultCountry + "_" + defaultVariant bundleName + "_" + defaultLanguage + "_" + defaultCountry bundleName + "_" + defaultLanguage bundleName
In our example, if you request the baseName LabelBundle with a fr_FR_WIN (French language, France, Windows platform) Locale, the getResourceBundle() method will perform the following steps:
Creating ResourceBundles
Object handleGetObject(String key)
This method returns an Object that corresponds to the specified key. These keys are internal representations of the content stored in the ResourceBundle, and should be the same for all localized versions of the same data. An extremely simple version of your LabelBundle might be defined as follows:
class LabelBundle extends ResourceBundle {
public Object handleGetObject(String key) {
if( key.equals("OK") )
return "OK";
else if( key.equals("Cancel") )
return "Cancel";
// Other labels could be handled here
return null; // If the key has no matches, always return null
}
}
Other versions of the same bundle might return values translated into different languages. You can see, however, that this method of handling key-value pairs is very inefficient if you have more than a few keys. Luckily, Java provides two subclasses of ResourceBundle which can make life easier: ListResourceBundle and PropertyResourceBundle.
ListResourceBundles use an array of two-element arrays to store the key-value pairs used above. All you have to do is override the default getContents() method, like this:
class LabelBundle extends ListResourceBundle {
static final Object[][] labels = {
{"OK", "OK"},
{"Cancel", "Cancel"},
("AnotherKey", "Another Value"}
//More key-value pairs can go here
};
public Object[][] getContents() {
return labels;
}
}
You could also provide your own similar functionality using a Hashtable, but that's only worthwhile if you want the contents to change dynamically over time.
PropertyResourceBundles are created as needed from predefined "property" files stored on disk. These are usually used for system-wide settings, or when large amounts of data need to be stored in a key-value pair. PropertyResourceBundles are built from files with the same name as the corresponding class file, but with the .properties extension instead. To implement the LabelBundle_de_DE class, you might provide a file called LabelBundle_de_DE.properties with the following content:
OK=Gut Cancel=Vernichten AnotherKey=This value has a lot of text stored within it. Of course, it really ought to be translated into German first...
Contents are always specified in the form "key=value" and are assumed to be Strings (although they can be cast into other appropriate objects). This functionality is based on the java.util.Properties class. See Chapter 33 for more information on the java.util package.
NOTE: Although the examples given here all deal with String objects, ResourceBundles can store Objects of any type, including Dates, Applets, GUI elements, or even other ResourceBundles!
There have been some other changes to the java.util packages which are mainly straightforward, but make substantial changes from the 1.1 Core API. The Date class is no longer to be used for time manipulation; it is simply a wrapper for one particular instant in time. For creating Date objects, you should now use the Calendar class. Calendar is an abstract class that provides culture-independent methods for manipulating the epoch, century, year, month, week, day, and time in various ways. In order to instantiate the Calendar class, you have to extend it and provide methods based on a particular Calendar standard. The only one that (so far) comes with the JDK is the GregorianCalendar class, which provides very sophisticated functionality for the world's most popular calendar system. Future releases may include support for various lunar, seasonal, or other calendar systems. An adjunct to the Calendar class, which is not usually used directly by the programmer, is the TimeZone (and SimpleTimeZone) class, which allows dates and times to be properly adjusted for other time zones.
The Date, Calendar, and TimeZone classes provide a huge amount of functionality that most programmers will never need to know about. You don't need to understand the intricacies of temporal arithmetic to make use of these classes; they all contain default methods that allow you to get the current time and date, and display it in a Locale-sensitive way. By merely using the provided methods, your programs will become localized by default; requiring no added effort on your part.
NOTE: There are many more methods in these few classes than are worth discussing here. If you are interested, a simple example of the Calendar and Date classes interacting is provided in the example at the end of the chapter. For a more complete discussion, you should consult the Java API documentation directly.
The old java.io package operated exclusively on byte streams: a continuous series of 8-bit quantities. However, Java's Unicode characters are 16 bits, which makes using them with byte streams difficult. Java 1.1 introduces a whole series of 16-bit character stream Readers and Writers, which correspond to the old InputStream and OutputStream. The two sets of classes can work together or separately, depending on whether your program needs to input or output text of any kind.
The way in which characters are represented as binary numbers is called an encoding scheme. The most common scheme used for English text, is called the ISO Latin-1 encoding. The set of characters supported by any one encoding is said to be its character set, which includes all possible characters that can be represented by the encoding. Usually, the first 127 codes of an encoding correspond to the almost universally accepted ASCII character set, which includes all of the standard characters and punctuation marks. Nevertheless, most encodings can vary radically, especially since some, like Chinese and Japanese encodings, have character sets that bear little resemblance to English!
Luckily, Java 1.1 provides classes for dealing with all of the most common encodings around. The ByteToCharConverter and CharToByteConverter classes are responsible for performing very complex conversions to and from the standard Unicode characters supported by Java. Each encoding scheme is given its own label by which it can be identified. A complete list of JDK 1.1 supported encodings and their labels follows is shown in Table 16.4:
| Label | Encoding Scheme Description |
| 8859_1 | ISO Latin-1 |
| 8859_2 | ISO Latin-2 |
| 8859_3 | ISO Latin-3 |
| 8859_4 | ISO Latin-4 |
| 8859_5 | ISO Latin/Cyrillic |
| 8859_6 | ISO Latin/Arabic |
| 8859_7 | ISO Latin/Greek |
| 8859_8 | ISO Latin/Hebrew |
| 8859_9 | ISO Latin-5 |
| Big5 | Big 5 Traditional Chinese |
| CNS11643 | CNS 11643 Traditional Chinese |
| Cp1250 | Windows Eastern Europe / Latin-2 |
| Cp1251 | Windows Cyrillic |
| Cp1252 | Windows Western Europe / Latin-1 |
| Cp1253 | Windows Greek |
| Cp1254 | Windows Turkish |
| Cp1255 | Windows Hebrew |
| Cp1256 | Windows Arabic |
| Cp1257 | Windows Baltic |
| Cp1258 | Windows Vietnamese |
| Cp437 | PC Original |
| Cp737 | PC Greek |
| Cp775 | PC Baltic |
| Cp850 | PC Latin-1 |
| Cp852 | PC Latin-2 |
| Cp855 | PC Cyrillic |
| Cp857 | PC Turkish |
| Cp860 | PC Portuguese |
| Cp861 | PC Icelandic |
| Cp862 | PC Hebrew |
| Cp863 | PC Canadian French |
| Cp864 | PC Arabic |
| Cp865 | PC Nordic |
| Cp866 | PC Russian |
| Cp869 | PC Modern Greek |
| Cp874 | Windows Thai |
| EUCJIS | Japanese EUC |
| GB2312 | GB2312-80 Simplified Chinese |
| JIS | JIS |
| KSC5601 | KSC5601 Korean |
| MacArabic | Macintosh Arabic |
| MacCentralEurope | Macintosh Latin-2 |
| MacCroatian | Macintosh Croatian |
| MacCyrillic | Macintosh Cyrillic |
| MacDingbat | Macintosh Dingbat |
| MacGreek | Macintosh Greek |
| MacHebrew | Macintosh Hebrew |
| MacIceland | Macintosh Iceland |
| MacRoman | Macintosh Roman |
| MacRomania | Macintosh Romania |
| MacSymbol | Macintosh Symbol |
| MacThai | Macintosh Thai |
| MacTurkish | Macintosh Turkish |
| MacUkraine | Macintosh Ukraine |
| SJIS | PC and Windows Japanese |
| UTF8 | Standard UTF-8 |
Character streams make heavy use of Character set converters. Fortunately, they also hide the underlying complexity of the conversion process, making it easy for Java programs to be written without knowledge of the Internationalizing process. Again, you see that programs are internationalized by default.
The advantages of using character streams over byte streams are many. Although they have the added overhead of doing character conversion on top of byte reading, they also allow for more efficient buffering. Byte streams are designed to read information a byte at a time, while character streams read a buffer at a time. According to JavaSoft, this, combined with a new efficient locking scheme, more than compensates for the speed loss caused by the conversion process. Every Input or Output Stream in the old class hierarchy now has a corresponding Reader or Writer class that performs similar functions using character streams (see Table 16.5).
| Byte Stream | Corresponding Character Stream OutputStream) Function | Class(InputStream/ Class(Reader/Writer) |
| InputStream | Reader | Abstract class from which all other classes inherit methods, and so on |
| BufferedInputStream | BufferedReader | Provides a buffer for input operations |
| LineNumberInputStream | LineNumberReader | Keeps track of line numbers |
| ByteArrayInputStream | CharArrayReader | Reads from an array |
| N/A | InputStreamReader | Translates a byte stream into a character stream |
| FileInputStream | FileReader | Allows input from a file on disk |
| FilterInputStream | FilterReader | Abstract class for filtered input |
| PushbackInputStream | PushbackReader | Allows characters to be pushed back into the stream |
| PipedInputStream | PipedReader | Reads from a process pipe |
| StringBufferInputStream | StringReader | Reads from a String |
| OutputStream | Writer | Abstract class for character-output streams |
| BufferedOutputStream | BufferedWriter | Buffers output, uses platform's line separator |
| ByteArrayOutputStream | CharArrayWriter | Writes to a character array |
| FilterOutputStream | FilterWriter | Abstract class for filtered character output |
| N/A | OutputStreamWriter | Translates a character stream into a byte stream |
| FileOutputStream | FileWriter | Translates a character stream into a byte file |
| PrintStream | PrintWriter | Prints values and objects to a Writer |
| PipedOutputStream | PipedWriter | Writes to a PipedReader |
| N/A | StringWriter | Writes to a String |
The most advanced and complex Internationalization API features are found in the java.text package. They include many classes for formatting and organizing text in a language- independent way. For instance, date formatting can be quite problematic for programmers. In America, dates are written in month-day-year order, but in Europe, dates are written in day-month-year order. This makes interpreting a date like 10/2/97 difficult: Does this represent October 2, 1997 or February 10, 1997? This is the purpose of properly formatted text. Most of these classes are not intended to be instantiated directly, and can be accessed through static getDefault() methods.
Text collating, on the other hand, is the process of sorting text according to particular rules. In English, sorting in alphabetical order is relatively easy, because English lacks many special characters (such as accents) that could complicate things. In French, however, things are not so simple. Two words that look very similar (like péché and pêche) have entirely different meanings. Which should come first alphabetically? And what about characters like hyphenation or punctuation? The Java Collation class provides a way of defining language-specific sort criteria in a robust, consistent manner.
Text boundaries can also be ambiguous across languages. Where do words, sentences, and paragraphs begin and end? In English, a period generally marks the end of a sentence, but is this always the case? Certainly not. The TextBoundary and CharacterIterator classes can intelligently break up text into various sub-units based on language-specific criteria. Java 1.1 comes with built-in support for some languages, but you can always define your own set of rules, as well. TextBoundary works by returning the integer index of boundaries that occur within a String, as demonstrated by the following example, which breaks a String up by words:
String str = "This is a line of text. It contains many words, sentences, and formatting."
TextBoundary byWord = TextBoundary.getWordBreak();
int from, to;
from = byWord.first();
while( (to = byWord.next()) != DONE ) {
System.out.println( byWord.getText().substring(from, to) );
from = to;
}
This snippet of code will print out each word on its own line. Although this example is trivial, text boundaries can be extremely important, especially in GUI applications that require text selection, intelligent word-wrapping, and so on.
To better understand how all of this fits together, take a look at this very simple Java application that makes use of several of the features discussed in this chapter. It is included on the CD-ROM accompanying this book, if you'd like to play with it yourself.
The application is a very simple one. It takes up to three command-line parameters that specify a locale. It uses this information to:
Besides the main application class (InternationalTest), the program requires several other classes. Most are ResourceBundles that correspond to different locales (currently, ResourceBundles must be created as public classes, but this may change in a future release of the JDK). Another thing to note is that this application passes "null" as the ClassLoader parameter to the getResourceBundle() method. This is because applications are loaded from the CLASSPATH environment variable, and do not have an explicit ClassLoader. So long as the ResourceBundles are also available via CLASSPATH, you don't need a separate ClassLoader to load them. If you were making an applet, on the other hand, you would need a ClassLoader to load the classes across the Internet. You can use the same ClassLoader instance that loaded the applet like this:
ClassLoader loader = this.getClass().getClassLoader();
The complete listing of InternationalTest follows in Listing 16.1:
import java.util.*;
import java.lang.*;
import java.text.DateFormat;
class InternationalTest extends Object {
public static void main(String args[]) {String lang = "", country = "", var = "";
try {
lang = args[0];
country = args[1];
var = args[2];
} catch(ArrayIndexOutOfBoundsException e) {
if( lang.equals("") ) {
System.out.println("You must specify at least one parameter");
System.exit(1);
}
}
Locale locale = new Locale(lang, country, var);
Locale def = Locale.getDefault();
System.out.println( "Default Locale is: "+ def.getDisplayName() );
System.out.println("You have selected Locale: "+locale.getDisplayName() );
System.out.println("Default language, localized for your locale is: " +
def.getDisplayLanguage( locale ) );
System.out.println("Default country name, localized: " + locale ) );
ClassLoader loader = null;
ResourceBundle bundle = null;
try {
bundle = ResourceBundle.getResourceBundle( "TestBundle", locale, loader );
} catch( MissingResourceException e) {
System.out.println( "No resources available for that locale." );
} finally {
System.out.println( "Resources available are: ");
System.out.println(" r1: " + bundle.getString("r1") );
System.out.println(" r2:" + bundle.getString("r2") );
}
DateFormat myFormat = DateFormat.getDateTimeFormat(DateFormat.FULL, DateFormat.FULL, locale);
Calendar myCalendar = Calendar.getDefault( locale );
System.out.println("The localized date and time is: " +
myFormat.format( myCalendar.getTime() ) );
}
}
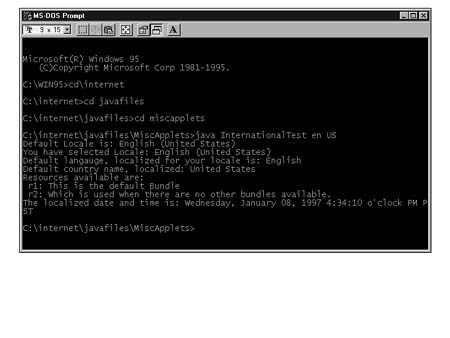
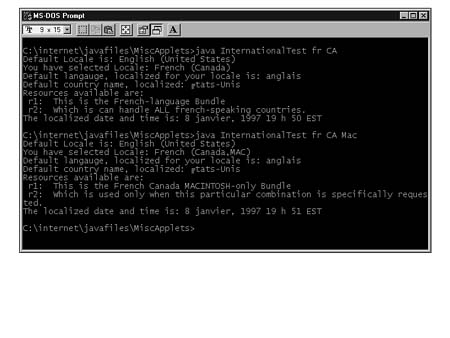
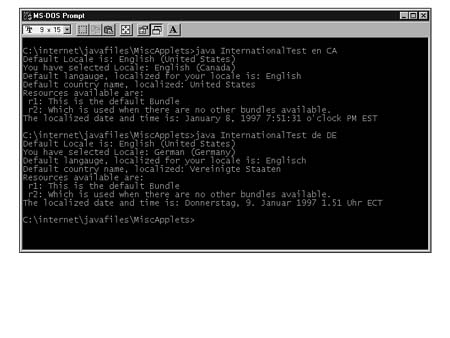
Figures 16.1, 16.2, and 16.3 show output from the InternationalTest program:
FIG. 16.1
American English locale.
FIG. 16.2
Canadian French, and Canadian French Macinotsh locales.
FIG. 16.3
Canadian English and Germany locales.
So where does this leave Joe Programmer? Well, he's got some work to do to convert his application to the Internationalization API. His labels, text, and localized resources need to be encapsulated into ResourceBundles for each locale he supports. He also needs to adjust a few methods and objects to use localized date, time, and message formats. When this process is complete, he'll find that not only will his program be localized for many locales, but that he also does not need to support multiple versions of the same program. Even better, when a new locale needs to be supported, he doesn't need to modify his source code at all--he just needs to get his locale-specific resources translated to this new language/customs. His program is now, once again, portable, reusable, and independent.
{kind=link}
{kind=link}
{kind=link}