{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




Debugging is still an art form. There seems to be less optimizing going on these days, but C++ developers can find more complex ways to add bugs into their programs than ever, albeit unintentionally. Why optimize when your user community can purchase faster PCs more cheaply than a development team can deliver a product, let alone optimize the 20 percent of code causing the bottleneck? C++ developers know that the C++ programming language allows language-smiths to write some pretty esoteric, hard-to-follow-for-the-average-person code.
Being able to write our own individual memory management schemes, or define how operators work with a myriad of types, can at best be a little intimidating and at worst extremely challenging to detect stray pointers, bad memory, or faulty logic.
This chapter shows you how to use the Developer Studio's debugging features, apply powerful techniques like assertions and code tracing, and demonstrate those MFC classes Microsoft has provided to assist you in finding a large variety of bugs.
Debugging is a proactive process that should occur during development. The worst way to debug is to postpone debugging until some magical time when a monolithic debugging process is supposed to occur. Where, when, and how you add debugging code is probably as important as the code that solves the original problem. You don't have to believe me. Ask Dave Thielen, the author of No
Bugs! Ask Microsoft why they incorporate ASSERTs and TRACEs into auto-generated code. (You can reach Microsoft Technical Support at (206) 635-7007 in the U.S.)
The Integrated Development Environment (IDE) is the programmer's best friend. It is the context-sensitive, cross-referenced help, online tutorials, menus, hotkeys, and, more recently, speed buttons that provide developers with fingertip access to a wealth of information. To program well in C++, you need to know the language inside and out. Exercising the Developer Studio to its intended capacity helps you develop applications faster and more robustly. The easiest chunk of knowledge to acquire is that someone else probably experienced the problem. Knowing this suggests following in the footsteps of others. Except for the most trivial of problems, consult the online help and use the features provided in the IDE to get information about the state of your program and its objects.
To do this, you need to know all the crevices into which Microsoft has stuffed tips and tidbits to provide you with answers to the mysteries of programs. The days of writing print statements to get information about the state of a program have dwindled and passed for most of us. The developer studio has a wealth of options; read the next section to see where and what they are.
Hotkeys, menus, and toolbars are generally GUI synonyms for each other. Use menu options to get started because they are more verbose and easily found. Supplanting tedious menu options with hotkeys and speed buttons will ultimately make your development experience more expedient, but, so far, not using them will not be an impediment.
Table 20.1 describes most of the menu options by menu name and menu item name, followed by a description of the purpose of each.
| Menu | Description | |
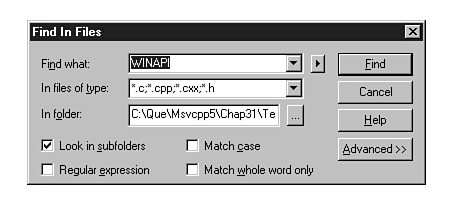
| File, | Find in FilesNone. Fill out the dialog box (refer to fig. 20.1) with a token, path, and file mask(s); it returns all references to the token. | |
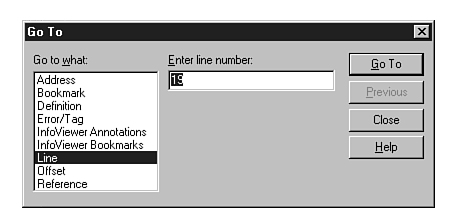
| Edit, Go To | Goes to line numbers, bookmarks, or addresses in compiled code. This menu item acts as a good central navigation spot (see fig. 20.2). | |
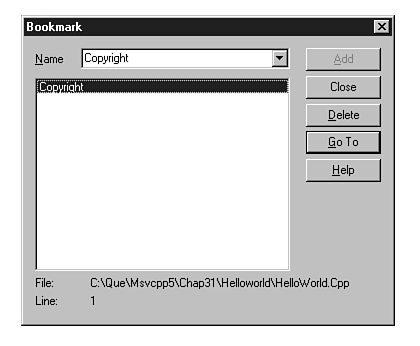
| Edit, Bookmark | Accepts an existing bookmark location (as demonstrated in fig. 20.3), enabling you to easily return to that spot with this menu item. | |
| Edit, Breakpoints | This feature enables you to set simple, iterative, or conditional breakpoints in your code (see fig. 20.4). | |
| View, Project Workspace | Activates the Project Workspace window. | |
| View, InfoViewer | Activates the InfoViewer Topic window. | |
| View, Output | Activates the output window. | |
| View, Watch | Activates the watch window. (The remaining View options are enabled only during program execution.) | |
| View, Variables | Displays variables in scope window. | |
| View, Registers | Displays the microprocessor's registers in a window. | |
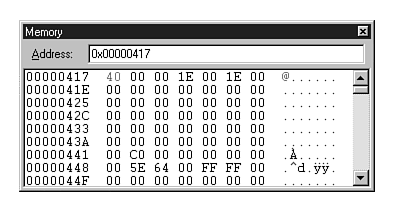
| View, Memory | Enables you to display a snapshot of the state of memory at an address. (Figure 20.5 shows the key state BIOS address with the Caps Lock key on.) | |
| View, Call Stack | Displays the function call stack. You can see an ordered list of the most recent to least recent function calls. | |
| View, Disassembly | Shows the underlying assembly language produced from the compiled C++ source. | |
| Build, Compile | Compiles the active source file. (The Build menu is replaced by a Debug menu during debugging.) | |
| Build, Build | Builds the entire project. | |
| Build, Rebuild All | Rebuilds all files regardless of dependencies | |
| Build, Batch Build | Builds multiple projects in batch mode. | |
| Build, Stop Build | Terminates the build in progress. | |
| Build, Update All Dependencies | Updates dependencies for selected projects. | |
| Build, Debug, Go | Starts or continues the program. | |
| Build, Debug, Step Into | Steps into a function, as opposed to stepping over a function. | |
| Build, Debug | Executes the program up to the cursor location. | |
| Build, Execute | Executes the program. | |
| Build, Settings | Enables editing of build and debug settings. | |
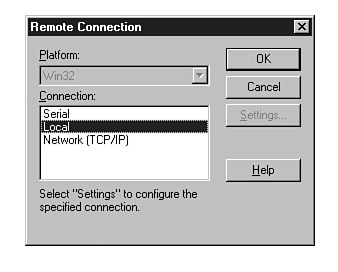
| Tools, Remote Connection | Enables remote serial, local or Network (TCP/IP) debugging (refer to fig. 20.6.) | |
| Tools, Record Keystrokes | Records keystrokes for playback. | |
| Tools, Playback | Plays back previously recorded keystrokes. | |
| Recording Window S_plit | Splits the current window. This enables asynchronous code viewing and editing of the same window. | |
| Window, Hide | Hides the active window. | |
| Help, Contents | Displays Help Table of Contents. | |
| Help, Search | Searches for help on a specific topic that includes articles on C++ printed in popular trade journals. | |
| Help, Keyboard | Shows the keyboard help table, shown in Figure 20.7 | |
| Help, Ti_p of the Day | Shows a Tip of the Day. | |
| Help, Technical Support | Displays a complete list of national and international technical suport information. |
The File, Find in Files dialog box option, shown in Figure 20.1, enables you to search multiple files for text matching the input text. This dialog box presents a simple interface to options that are reminiscent of Grep, which was originally developed for UNIX systems.
In this section you will see those features showcased that will assist you when debugging applications using the Microsoft Developer Studio. The Edit, Go To (see fig. 20.2) option is a neat spin on an old favorite. This option not only enables you to move the cursor to specific lines of text or addresses of compiled programs, but to bookmarks and references too.
Figure 20.2 : The enhanced Go To dialog box can be used as a central IDE navigation facility.
Figure 20.3 clearly demonstrates the usage of this feature. Place a bookmark on some relevant line of code by selecting Edit, Bookmark enabling you to return to the bookmark quickly. You may also select bookmarks in other projects, which will have the effect of opening that project's workspace.
The Edit, Breakpoint feature displays a tabbed dialog box (see fig. 20.4) that enables you to set very simple or complex breakpoints. The original breakpoint is the interrupt 3 function provided by the operating system. Setting a breakpoint puts a program on soft-ice, enabling you to restart the program. Setting a breakpoint may entail breaking anytime the line of code is executed or after a break condition occurs.
Figure 20.4 : Shows the Breakpoints dialog box; the simplest use is to break at a line of code.
A problematic code fragment may be attacked by breaking when a Windows message occurs or after some number of iterations of code or a specific condition exists. Sometimes errors manifest themseleves only after a number of iterations over the error inducing code, or perhaps you may even have to view the memory (refer to fig. 20.5) used by an object to determine if its state is in error.
In addition to menu items, Table 20.1 contains the hotkeys that are associated with debugging activities. Many of these have menu equivalents; the table notes where this condition exists. Using the hotkeys to navigate the Developer Studio may feel more natural for many veteran programmers because the first text-based GUIs, like WordStar, employed this kind of feature.
| TIP |
Table 20.1 does not represent an exhaustive list. It does present those readily available as perceived by looking at the menus. The Help, Keyboard menu displays a dialog box that contains all of the keyboard commands by category. |
The speed buttons on the menu bar provide an expedient way to perform common tasks. They are listed here for completeness, but today's IDEs provide ToolTips, which give the user a short hint as to the item's activity.
Figure 20.7 shows how the Microsoft Developer Studio Help Keyboard option displays a comprehensive table of Keyboard hotkeys, and Figure 20.8 shows the menu settings as activated by pressing Alt+f7.
Figure 20.8 : Shows the menu settings activated by pressing Alt+f7.
The entire toolbar suite is shown in Figure 20.9. Those items critical to debugging are along the bottom-most row of buttons. Beginning with the left-most button, which looks like a stack of papers, we have the Compile speed button, followed by Build, Stop Build, a combobox which toggles between debug time and distribution build settings, the Go speed button, Insert/Remove Breakpoint, and the Remove All breakpoints button.
Figure 20.9 : Displays the speed buttons, including those along the bottom pertinent to debugging.
A useful skill to develop early on is how to use the debugging features in concert to enable you to maximize debugging and testing within the Microsoft Developer Studio. This section walks you through debugging a scaffolded console application which tests the QuickSort algorithm presented in Chapter 32, "Additional Advanced Topics."
| NOTE |
To follow along in this hands-on exercise, load the QuickSortScaffold Project Workspace from the CD-ROM included with this book. |
The code is listed first in Listing 20.1 for convenience. The areas of interest are referred to by line number in the listing.
Listing 20.1 SORTS.CPP-Demonstration of Developer Studio Debugging
1: // SORTS.CPP - Contains the definitions and some test scaffolds
2: // Copyright" 1995. All Rights Reserved.
3: // By Paul Kimmel.
4:
5: #include "sorts.h"
6:
7: // Partitioning function for the RecursiveQuickSort.
8: template <class T>
9: unsigned long Partition( T data[], unsigned long left, unsigned long ›;right )
10: {
11: unsigned long j, k;
12: T v = data[right];
13:
14: j = left - 1;
15: k = right;
16:
17: for(;;)
18: {
19: while( data[++j] < v ) ;
20: while( data[--k] > v ) ;
21: if( j >= k ) break;
22: Swap(data[j], data[k]);
23: };
24: Swap(data[j], data[right] );
25: return j;
26: }
27:
28: // The QuickSort Function.
29: template <class T>
30: void RecursiveQuickSort( T data[], unsigned long left, unsigned long ›;right)
31: {
32: unsigned long j;
33: if( right > left )
34: {
35: j = Partition(data, left, right );
36: RecursiveQuickSort(data, left, j-1);
37: RecursiveQuickSort(data, j+1, right );
38: }
39: }
40:
41: #ifdef SORTS_SCAFFOLD
42: /* The scaffold is used only for testing the RecursiveQuickSort
43: * template function. By defining SORTS_SCAFFOLD project-wide we
44: * can easily remove the define, leaving the scaffold in place for
45: * another time. For instance, we may want to optimize the quicksort,
46: * or add additional functionality to this module.
47: * An added benefit is that the scaffold code also demonstrates
48: * to other users how to use the quicksort.
49: */
50:
51: #include <iostream.h> // Contains cout object
52: #include <stdlib.h> // Contains srand() and rand() functions
53: #include <time.h> // Definition of time()
54:
55: int main()
56: {
57: srand((unsigned long)time(NULL)); // Seed the random number ›;generator
58: unsigned long elems[10];
59: const unsigned long MAX = SIZEOF( elems );
60: // Fill the elems with random numbers.
61: for( unsigned long i = 0; i < MAX; i++ )
62: elems[i] = rand();
63: // Sort the elements, specifying the template type implicitly
64: unsigned long l = 0, r = MAX - 1;
65: RecursiveQuickSort(elems, l, r );
66: for( i = 0; i < MAX; i++ )
67: cout << i << ".=\t" << elems[i] << endl;
68: return 0;
69: }
70: #endif
| TIP |
Scaffolding discrete programs in stand-alone, simple programs is a much easier way to divide and conquer bugs. You are focusing on one very small part of code, and load times and compile times are much quicker than when testing them in a big application. Read Chapter 32, "Additional Advanced Topics," for more information on scaffolding. |
The algorithm is a template recursive QuickSort. A QuickSort is used to sort unordered data. It has an order-of-magnitude-a term used to describe its performance-of O(log 2N), which grows very slowly for a large number of elements, N. The sort works by dividing partitions of data in half successively until the partitions are very small. Then sorting each partition becomes very fast. The sort performs extremely well for randomly ordered data of very large sets.
In the small world of scaffolding we know the minimum and maximum element sizes, and because the RecursiveQuickSort function is called many times the first thing we can do is place a breakpoint in the Partition function. We might want to watch the first array access-the right index. The Partition function is critical to the success of this implementation of QuickSort, and accessing an array out of bounds is fatal.
To set a breakpoint on line 12, place the cursor on line 12 and press f9; or, place the cursor on line 12, click the right mouse button, and select Insert/Remove Breakpoint. In addition, two other areas in the Partition function where we need to ensure reliability are lines 19 and 20. The Partition function is called with a left and right bound for the relevant partition of array data. In addition to ensuring we don't go out of bounds on the entire array, we must also ensure that the index j is never incremented beyond the value of right and k is never less than 0 or less than left.
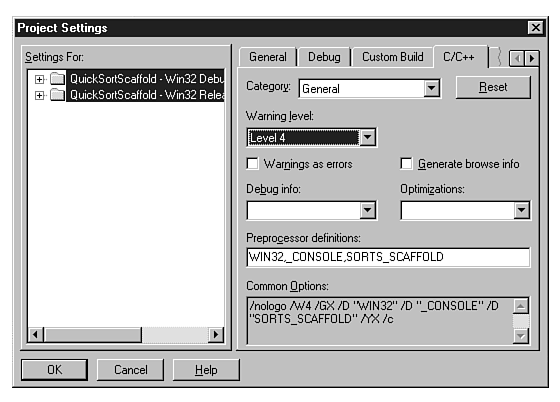
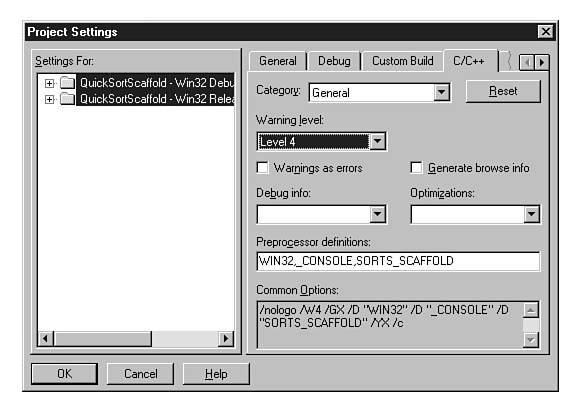
To set conditional breakpoints, we'll first set the breakpoints with f9 on lines 19 and 20. Then click the Condition button and enter the conditions for each breakpoint: for line 19, the condition is j<right, and for line 20, the conditions are k >= 0, k >= left. (Use Figure 20.10 as a visual guide.)
Figure 20.10 : Set the debug warnings to the highest level, Level 4, during development.
| TIP |
The paragraph on conditional breakpoints actually suggests a more maintainable solution, and one that is more visible. The use of assertions is applied the same way-write testable expressions that throw a flag when violated. For more details, read the section entitled "Employing ASSERT and TRACE" later in this chapter. |
After you have selected good candidate watch zones, you can run the code lickety-split with f5 or step into it with f11. After you begin to step through the application, the Build menu is replaced by an extended Debug menu, as depicted in Table 20.3, and an added plus of this developer centric IDE is the fly-by hints displayed for objects and variables. In addition the View, Watch window is displayed. You may Hide this or any window by giving it the focus and pressing Shift+Esc or using the right mouse menu item, Hide. To View this or other debug windows after hiding them, select the View menu and the window name menu item.
| TIP |
The fly-by hints are available in debug mode for variables. Place the mouse cursor over an object or variable name for a fly-by quick watch hint. |
| Menu | Hotkey | Description |
| Debug, Go | f5 | Executes or restarts the current program |
| Debug, Restart | Ctrl+Shift+f5 | Restarts the currently executing program |
| Debug, Stop Debugging | Shift+f5 | Stops debugging the program |
| Debug, Break | Stops program execution while debugging | |
| Debug, Step Into | f11 | Traces into a line of code |
| Debug, Step Over | f10 | Steps over the next statement |
| Debug, Step Out | Shift+f11 | Exits the current function |
| Debug, Run to Cursor | Ctrl+f10 | Executes until reaching the cursor location |
| Debug, Step Into function | Steps through a specific Specific Function | |
| Debug, Exceptions | Edits debug actions taken when an exception occurs | |
| Debug, Threads | Sets debug thread attributes | |
| Debug, Settings | Alt+f7 | Edits projects build and debug settings |
| Debug, QuickWatch | Shift+f9 | Immediately evaluates variables and expressions |
Now that we have our initial breakpoints and break conditions set we can run the scaffold, waiting for the debug engine to notify us if something is wrong.
There are several aspects to debugging during the micro-phase of development. Following is a debugging checklist:
There are a few ways to perform the tasks in the preceding checklist. The old fashioned way, which still works, is code tracing: place output statements at key locations providing an ongoing retrospective of activity. The simplest form of this is to print statements to the console. A better way is write to a file, creating a persistent log. With the advent of IDEs, we can now set breakpoints with conditional tests based on the number of iterations or some logical test. The most maintainable way of all may be to use code.
What is referred to is macros like ASSERT, which you will read about in the upcoming section "Employing ASSERT and TRACE." These functions provide a sustained legacy of the activity that was employed to test key values and critical paths. Using assertions and traces is referred to as the most maintainable way because the codified assertions are self-commenting as to what can go wrong, and they are easily turned on or off by compiler directives, as opposed to a back- and-forth interaction with the IDE.
As an exercise, use the breakpoints we added and the f11 key, stepping through the program to see if you can determine what strengths or weaknesses the QuickSort implementation has. (Hint: The indices are wrapping at the extremities and in some circumstances are throwing Access Violations.)
Development constraints are those IDE settings and preprocessor definitions which enable you to quickly find books. Compared to in-development constraints, which would be perceived as obnoxious to users, delivery constrainment is more relaxed. Delivery constrainment includes the (preprocessor) removal of assertions, code tracing, and other debug code added by the IDE, or you, the developer. The constraints placed on a program during development should be at their highest. This includes having TRACE and ASSERT macros in place and active, and in the Microsoft Developer Studio, you may want to set the Warning level to its highest setting. The default setting is Level 3; the highest setting is Level 4 as shown in Figure 20.10.
After you have developed your application with all of the debugging constraints-like assertions and code tracing-in place, the objective is not necessarily to remove them, but rather to disable them. Leaving this code in place acts as a road map to what was done to remove bugs and how it was done. It's a kind of a self-commenting history of debugging activity.
Any code that was added can be toggled with conditional compiler directives. Unfortunately, it is not as easy to do with Developer Studio settings. You have to make these changes within the Developer Studio to some extent. Reemphasizing my earlier suggestion that it was easier in some regard to use code to eke out bugs, an especially useful aspect of the Developer Studio is that you can save configurations and toggle any settings all at once. So, while you still have to make each set of configuration settings, you can quickly toggle between an entire configuration-between debug and release constraints-all at once.
To configure development versus delivery constraints for warning Level 4:
A great convenience is that in addition to being able to set group configuration settings, you can also set individual file settings by expanding the list and modifying configuration items for individual files. To toggle all settings, simply choose between default project configurations from the combobox on the toolbar depicted in Figure 20.9.
The notion of asserting something and tracing code has been around awhile. The power and value they add to the software development process is weighty to say the least. Microsoft inserts them in its generated code. One of its best operating systems produced the book No Bugs! by Dave Thielen (also from Microsoft), published by Addison-Wesley, and littered with assertions and code tracing. It is shocking that the more subjective issues of quality software design are not taught nor emphasized in college curriculums (based on limited observation, at least). Equally shocking is that many mainstream languages do not directly support good debugging techniques, like assertions and tracing.
Some of you may not even know what ASSERT and TRACE are. A synonym for assert is declare. When you are asserting, in essence, you are declaring that certain assumptions were made and to transgress these assumptions is a logical violation of the expected state of the program at the point of the assertion. The easiest way to declare an assumption about the state of a program at any point is with code. However, assertions are more powerful than runtime tests but not a replacement for runtime tests. While runtime tests are important, because assertions are for design-time only, assertions are used to throw a big, red, ugly flag up when something that you have declared to be true is not.
| TIP |
ASSERT and TRACE are debug or design-time only techniques. You never leave assertions or any debug code active in the delivered product. Neither though do you actively cut and paste assertions; rather, you leave them in and let the preprocessor strip them out based on whether _DEBUG is defined or not. The #define _DEBUG is defined by debug in a Debugging build and undefined in a Release build. |
The following short code listing demonstrates a simple assertion. It is not especially useful but demonstrates the technique, what happens (in this case in a console mode application, but a windows assertion produces the same information) when an assertion fails (see fig. 20.12). And, in addition, Figure 20.13 shows the View, Call Stack which shows the _assert function underlying the macro.
Listing 20.2 (Assumption.Cpp)-A Simple Use of assert: My Assumption Was Integers Are Initialized to 0 by Default; They Are Not
// Assumptiom.Cpp - Simpe demonstration of assert.
// Copyright 1996. All Rights Reserved.
// by Paul Kimmel. Okemos, MI USA
#include <assert.h>
void main()
{
const int zero = 0;
int initializesTo;
// My assumption is that integers initialize to 0
// Is the assumption True or False?
assert( initializesTo == zero );
}
For example, suppose you declare an array of 10 elements. It would be an error to ever access the array outside of the range of 0 to 9. You should certainly test for this with conditional statements, and, better yet, use a smart class to bind the testing process to the array. But an assertion is used to tell the developer that her assertion/declaration/assumption is being violated. Using a bad index will cause bad things to happen, especially in Windows programs, so why go on? The assert macro is for the developer. It throws a red flag, so the problem can be addressed before it ever leaves the production line.
| NOTE |
When referring to the assertion macro you may notice several case usages, ASSERT or assert, for example. This is not unintentional carelessness; rather, it was done intentionally because there are variations of the assertion macro-older C uses lowercase assert and MFC uses uppercase ASSERT among others-which all perform roughly the same activity and are used identically. The biggest difference between the variations of assert is the environments in which each is used. N |
A simple assertion can be implemented with a Boolean argument and some kind of code locator, like a file name and line number. If the Boolean argument evaluates to False then it is determined that the assumption is in error. You can then fix the code or fix the assumption before anyone is the wiser.
The concept behind tracing is that, instead of actively watching your program's activity, you can employ an agent to display the code progress to a second source. Examples of agents have historically been code that writes to a second monochrome monitor's debug windows within one screen, files, and printers. Actively steeping through a program and constantly turning on watch values is a pain in the neck. Using trace and assert macros makes the activity more passive, and you can get volumes of information at execution speeds.
The old standby DOS-based CRT assert macro exists written to the DOS-mode CRT. In a 32-bit, graphical user interface, switching to the text view and the windows view might be disruptive at a minimum. Therefore, Microsoft has created high-powered spinoffs that work within GUI environments-a normal and necessary transition.
What is the big hullabaloo? Well, using macros is flexible because you locate the code when the preprocessor pastes the macro inline. Better still, and much more important, is that asserts and traces become enforcers. With macros like assert, which immediately causes developers to become aware of misapplied logic; and trace, which provides a wealth of information, software developers can create styles of software development. One style is contractual programming. A contractual style of programming is where you document an expectation-like a hypothetical function that processes a pointed-to object, where the caller must ensure that the pointer points to a valid object-and you enforce it with an assertion. A pseudo-code example follows:
// Contract: User must ensure pointer is valid
void ProcessObject( Foo * fooObject )
{
assert( fooObject != 0 );
// process object
}
The developer clearly comments that the user must ensure the validity of the pointer. The assertion macro ensures that the contract is abided by. Contract programming without a town marshal is like lending money without a collection strategy: You may go bankrupt. The obligation in contract programming is that you have relegated responsibility, and if something goes wrong it's not your fault if the contract is broken. More importantly, as with written contracts, you are making it eminently clear what is expected of your programmer-user community.
| TIP |
Contract programming is useful if all developers are using some common practices. One such practice is that, except for the most trivial of applications, you should build debug versions of your applications before release version. If a developer avoids abiding by the contract by never enabling debugging, then the curative is to get rid of the programmer. |
The notion of tracing is equally important. How can you be reasonably sure your code is bug-free if you have not tested all code paths? And, how can you be sure when you are testing specific code paths? Code-tracing is the solution. If the clichŽ "information is power" is true then the way to gather information is to apply code tracing and asserting proactively.
There are several specific assert macros. They all work relatively the same way and perform the same action; that is, they send a message to the user of the asserted code and halt all activity, thus enabling the problem to be addressed at its earliest possible opportunity.
Using ASSERT constructively is not that hard. First, you have to determine which assert to use. Simple enough: Use lowercase assert by including <assert.h> and turning it off with #define NDEBUG when building console applications or scaffolding, and use uppercase ASSERT when building everything else. The assert macro can get the __LINE__ and __FILE__ values because they are maintained by the compiler, and the preprocessor pastes code in the macro at the location of the assert. Hence, when the assertion fails, a message indicating an assertion failure, the line number, and file name are readily available. You never have to remove the assertion code either. By toggling #define NDEBUG to disable all assertions and #undef NDEBUG to enable all assertions, you can write the assertion code as you go and leave the assertions in place for maintenance and future debugging.
The following are rules for using assert:
Some examples of assertions might appear in different code fragments like the following:
// #define NDEBUG // Uncomment to disable assertions
#include <assert.h>
void ApplyRadiation( unsigned long rads )
{
assert( rads < makesUmGlow ); // never make them glow
if( rads >= makesUmGlow ) // normal runtime checking
// perform shutdown
}
The preceding code demonstrates an assertion that enforces the notion that it is always a bad practice to irradiate something or someone too much. The test if( rads >= makesUmGlow ) will shut down the system but the assert will alert us that perhaps we need to find out why bad values are being sent and what code-agent is sending the bad values. Assertions are not only to keep bad things from happening in our code, they are to alert us that they are happening so we can address them.
When you use the wizard to generate MFC applications, you may get a different flavor of assertion, but underneath it is and does pretty much the same thing.
/////////////////////////////////////////////////////////////////////////////
// CMainFrame diagnostics
#ifdef _DEBUG
void CMainFrame::AssertValid() const
{
CFrameWnd::AssertValid();
}
Assertions come up in an increasing variety. In the previous example, the idea behind a method like AssertValid() is to apply assertions to an object's state. The function can be used to assert the integrity of an entire object. Regardless of the specific orchestration, the goal behind assertions is to provide an early warning system as to when something goes far astray from its intended course, early and clearly.
Microsoft, having easily a user community in the 100+ million range and competing in a global market, is in a position to feel a reeling shockwave if it distributes applications with grave bugs. It is no wonder that its wizards produce code littered with assertions and traces.
These macros eke out things that could make even Microsoft's multi-billion dollar bank book squishy. If you are using MFC code, you don't have a lot of choice whether or not to use them, but Microsoft is using them to combat real economic disaster. If you are not using these techniques, you may want to consider becoming proactive. Learn to employ them by emulating the code produced by the wizards and existing code.
There are actually several TRACE macros. There is TRACE, TRACE0, TRACE1, TRACE2, and TRACE3. The number-suffix indicates the number of parametric arguments beyond a simple string, working much like printf. The different versions were implemented to save data segment space. All of the macros except TRACE place the code in the code segment saving DGROUP space.
The TRACE macros only work when compiled with the debug MFC classes and are stripped out when compiling the release version of an application.
The following code shows you an example of where and how the MFC wizards may add traces to your code.
1: if (!m_wndToolBar.Create(this) ||
2: !m_wndToolBar.LoadToolBar(IDR_MAINFRAME))
3: {
4: TRACE0("Failed to create toolbar\n");
5: return -1; // fail to create
6: }
The TRACE macros write to afxDump, which can be defined as a debug window, a debug CRT, or stderr in Console applications. The number-suffix indicates the parametric argument count, and you use the parametric values within the string to indicate the passed data type. For example, to pass an integer:
TRACE1("Error Number: %d\n", -1 );
Or, to pass two arguments, maybe a string and an integer:
TRACE2("File Error %s, error number: %d\n", __FILE__, -1 );
The most difficult part of tracing is making it a habit. As with assertions, trace critical code paths to ensure they are actually tested. TRACE problem areas because it is faster to plot the course of code passively as opposed to stepping through it, and employ traces while coding, not in one monolithic effort to squeeze out all bugs at once.
Microsoft's approach to help documentation is to provide you access to articles as well as more traditional explanations and uses of functions. Because of this topic/article approach, there are literally more pages of information in the help system regarding help and diagnostics than were allotted for this entire chapter. Therefore, the approach chosen is to generalize what many of the primary features of the MFC diagnostic support are, tell you what articles and documentation you may find most useful, and finally demonstrate those techniques that support some of these ideas.
The following are general MFC debugging features:
In addition, it may ease your mind to note that there are only three other details you need to address to enable debugging.
Enabling and disabling debugging is as easy as 1-2-3; just follow these steps:
In the remainder of this section, you will see examples demonstrating how to perform each of these three steps.
The MFC Tracer utility is a stand-alone application with an integrated menu item in the Developer Studio. You may run it from the Developer Studio in any way you run any other Windows application. The good news is that application tracing is enabled by default. I'll explain in a second. The bad news is that we need to discuss what that means, so you will know when it is off or on and how to modulate it.
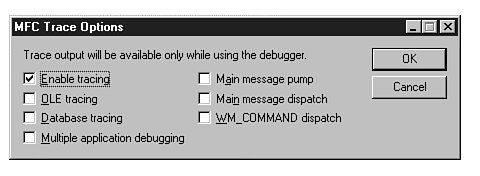
To enable tracing you must define _DEBUG, and the value of afxTraceFlags, which modifies an AFX.INI file. It is enabled by default because the default build is a debug build, which defines _DEBUG. And if you look in the Tracer utility (shown in fig. 20.12) you will see that the enable tracing checkbox is also selected by default.
The easiest way to disable tracing is to simply rebuild the entire application with the release configuration selected, which undefines _DEBUG. You can modify the afxTraceFlags with code by assigning it flag values defined in afxwin.h. Listing 20.3 displays the values of each flag. Use Tracer to set the afxTraceFlags value.
Listing 20.3 afxwin.h-Possible Values for afxTraceFlags
extern AFX_DATA UINT afxTraceFlags;
enum AfxTraceFlags
{
traceMultiApp = 1, // multi-app debugging
traceAppMsg = 2, // main message pump trace (includes DDE)
traceWinMsg = 4, // Windows message tracing
traceCmdRouting = 8, // Windows command routing trace (set 4+8 for ›;control notifications)
traceOle = 16, // special OLE callback trace
traceDatabase = 32 // special database trace
};
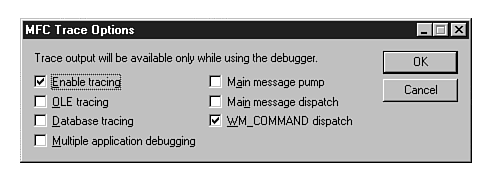
The code for the Tracer utility is included with Microsoft Visual C++, enabling you to customize it. A good way to experiment with the output provided by different Tracer values is to experiment with this application. As an exercise, load the Project Workspace \MSDev\Samples\ Mfc\Utiltiy\Tracer\Tracer.Mdp. Figure 20.13 shows the Debug output window with Enable tracing and WM_COMMAND dispatch checked in the MFC Trace utility. The highlighted line in the debug window shows the Tracer logging the Cancel button click.
The class CObject defines the member Dump. It is defined as:
virtual void Dump(CDumpContext& dc ) const;
In English, it is a virtual const member function. The virtual specifier suggests you should override the method in your derived classes, and the const specifier indicates that Dump works with both constant and non-constant objects, but you cannot modify the object state while Dumping.
The Dump member is used with debug compilations only. Therefore, you should wrap the declaration in the interface file, otherwise known as a header file, and also wrap the definition in a conditional compiler directive in the implementation file, usually referred to as the module or .CPP file.
In the header file, the declaration, including the preprocessor directive, appears like the following:
// CNewClass.H - Contains new class definition
// Copyright 1996. All Rights Reserved.
// By Joe CodeWriter
class CNewClass : public CObject
{
public:
// other class stuff
#ifdef _DEBUG
virtual void Dump( CDumpContext& dc) const
#endif
// ...
};
And in the implementation file, the definition, which includes a code body, might look like this:
// CNewClass.CPP - Contains new class member definitions.
// Copyright 1996. All Rights Reserved.
// By Joe CodeWriter
#include "cnewclass.h"
#ifdef _DEBUG
void CNewClass::Dump( CDumpContext& dc ) const
{
CObject::Dump( dc ); // Dump parent;
// perhaps dump individual members, works like cout
dc << "member: " << /* member here */ endl;
}
#endif
Using the CDumpContext Class The MFC class CDumpContext is used by the Dump method to direct dump output to the debug window if the afxDump object is used. The object afxDump is instantiated as a CDumpContext when you are debugging. Typically this is the object you pass to Dump methods. The CDumpContext has an overloaded ostream<< operator, which you can use to write the contents of your object to either the output-debug window for Windows applications or the stderr (usually the Console) for Console applications.
If you want to use another CDumpContext object, the constructor is defined to take a pointer to a CFile object. Therefore, you have to initialize a CFile object first. The code listing in the next section demonstrates defining a Dump method, using the afxDump object and defining a CFile and CDumpContext object.
A Demo Using CDumpContext, CFile, and axfDump The demo in this section provides a codified example of using the MFC debugging class CDumpContext, another MFC class Cfile, which is an argument type of CDumpContext's constructor, and the global axfDump object. The debug window output from this demo and the output CFile code are in Listing 20.4.
Listing 20.4 DumpContextDemo.Cpp-Demonstrates the MFC Debugging Class CDumpContext and Cfile
1: // DumpContextDemo.Cpp - Demonstrates using Dump, CDumpContext, afxDump, ›;and CFile
2: // Copyright 1996. All Rights Reserved.
3: // by Paul Kimmel. Okemos, MI USA
4: #include <afx.h>
5: // _DEBUG defined for debug build
6: class CPeople : public CObject
7: {
8: public:
9: // constructor
10: CPeople( const char * name );
11: // destructor
12: virtual ~CPeople();
13: #ifdef _DEBUG
14: virtual void Dump(CDumpContext& dc) const;
15: #endif
16: private:
17: CString * person;
18: };
19: // constructor
20: CPeople::CPeople( const char * name) : person( new CString(name)) {};
21: // destructor
22: CPeople::~CPeople(){ delete person; }
23: #ifdef _DEBUG
24: void CPeople::Dump( CDumpContext& dc ) const
25: {
26: CObject::Dump(dc);
27: dc << person->GetBuffer( person->GetLength() + 1);
28: }
29: #endif
30: int main()
31: {
32: CPeople person1("Nicholas Benavides");
33: CPeople person2("Jim Kimmel");
34: CPeople person3("Alex Kimmel");
35: // Use existing afxDump with virtual dump member function
36: person1.Dump( afxDump );
37: // Instantiate a CFile object
38: CFile dumpFile("discardme.txt", CFile::modeCreate |
39: CFile::modeWrite);
40: if( !dumpFile )
41: {
42: afxDump << "File open failed.";
43: }
44: else
45: {
46: // Dump with other CDumpContext
47: CDumpContext context(&dumpFile);
48: person2.Dump(context);
49: }
50: return 0;
51: }
At line 4, the <afx.h> header file is included, which contains the CObject class definition and provides access to afxDump. The comment on line 5 was placed there to indicate that either the /D_DEBUG switch or definition of _DEBUG is defined when you compile the Debug version in the Developer Studio.
Lines 6 through 18 define a class CPeople derived from CObject. The purpose of the class was to demonstrate the placement of the redefined virtual Dump method and the conditional compiler wrap. When you are done testing a program using Dump, you will actually need to wrap all uses of Dump in conditional compiler directives.
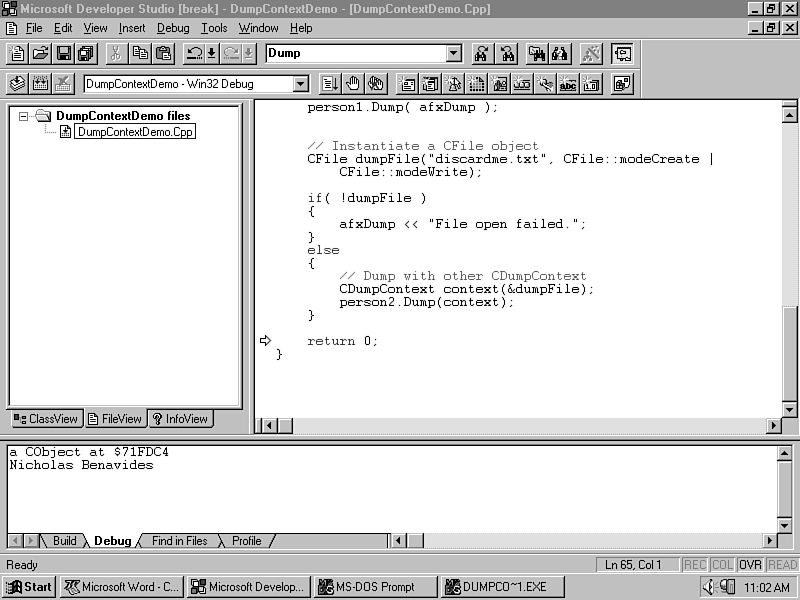
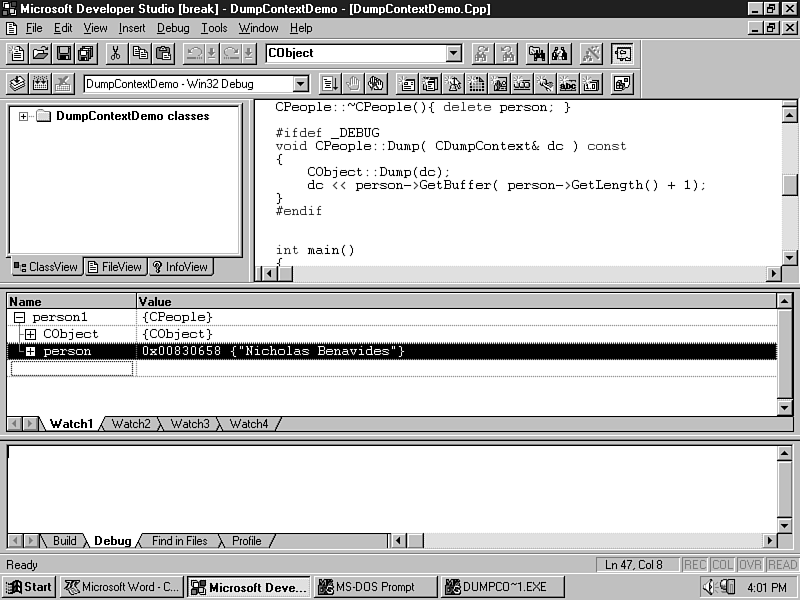
Lines 23 through 29 show the Dump member definition. Use it to display the contexts of the object to a CDumpContext like the output-debug window (see fig. 20.14) or a text file (see Listing 20.5).
Figure 20.14 : Shows the debug-output window where the afxDump object writes its output.
In the test main on line 16 the DumpContext afxDump which writes the output to the debug window, is used. Lines 38 to 48 demonstrate how you can create an alternate CDumpContext. Specifically, line 38 creates a CFile object. Line 47 shows you how to create and use a CFile object to create an alternate CDumpContext, passing the address because the CDumpContext constructor takes a pointer to a CFile. And finally, on line 48, the CDumpContext object can also be passed to the CPeople Dump method. The uses are similar whether you are writing Windows GUI applications or are actually targeting a Console program.
The debug-output window is shown in Figure 20.14. Refer to it during the description of the Dump function's output. The text file output, demonstrating the role of the CFile object is as follows:
Listing 20.5 discardme.txt-Output File from DumpContextDemo.Exe
a CObject at $71FDE4 Jim Kimmel
If you have learned the C++ language, then using any class requires relatively the same kinds of processes. You might ask, where was the CObject base class instantiated? Remember that if a child class does not call a constructor expressly, then the default base constructor is called. If you step through the demo program you see that that is exactly what happens.
There are additional measures that can be employed with MFC debugging classes. Among the lot is the CMemoryState class and the DEBUG_NEW macro. These are described in the last section of the chapter "Techniques for Sealing Memory Leaks."
MFC does not use the ANSI C++ specification for Runtime Type Identification (RTTI). Instead, MFC associates a class named CRunTimeClass with CObject, offering runtime type checking. One article you may find informative is CObject Class: Accessing Run-Time Class Information. The following section summarizes the idea of runtime checking using this class, and offers a short code example.
Before we embark, let me offer a few things for you to rattle about in your head. RTTI is a more recent introduction into the ANSI C++ specification. And so too is the introduction of non-RTTI classes like CRuntimeClass. The reason for this is because originally it was intended that you use virtual methods and enable polymorphism to determine or perform the precise, type-specific behavior. You may come across some rare circumstances where you feel you absolutely need to know the type of an object, but rampant use of type checking is probably indicative of a suffering design. With that in mind, let's take a look at what MFC has to offer.
There are several pieces of the puzzle to be assembled before you can use the MFC type- checking mechanisms. One is that the base class CObject has a method called IsKindOf. To use IsKindOf you need to use three macros in your code, the first, which detects compatibility, is IMPLEMENT_DYNAMIC( CChildClass, CParentClass ). Another is
DECLARE_DYNAMIC( CChildClass )
in the class definition. And, add
RUNTIME_CLASS( CChildClass )
to the implementation (also referred to as the .CPP) file. Listing 20.6 lists the RunTimeDemo.Cpp source, which demonstrates the locality of the assembled pieces.
Listing 20.6 RunTimeDemo.Cpp-Demonstrates the MFC CRuntimeClass
1: // RunTimeDemo.Cpp - Demonstrates using the CRuntimeClass.
2: // Copyright 1996. All Rights Reserved.
3: // by Paul Kimmel. Okemos, MI USA
4: #include <afx.h>
5: class CTypeCheck : public CObject
6: {
7: // Preprocesor generates runtime type declarations
8: DECLARE_DYNAMIC( CTypeCheck );
9: public:
10: CTypeCheck(){};
11: };
12: // Preprocessor generates runtime type definitions.
13: IMPLEMENT_DYNAMIC( CTypeCheck, CObject );
14: int main()
15: {
16: CObject * newObject = new CTypeCheck();
17: if( newObject->IsKindOf( RUNTIME_CLASS( CTypeCheck) ))
18: afxDump << "newObject Is CTypeCheck\n";
19: else
20: afxDump << "type mismatch\n";
21: delete newObject;
22: return 0;
23: }
The example in Listing 20.6 is contrived for the sole purpose of demonstrating the relative placement of each of the pieces and the use of the member functions. The class CTypeCheck is derived from a public CObject. CObjects have a relationship to the struct CRuntimeClass via the method IsKindOf, the macros mentioned previously, and the _GetBaseClass member, which returns a pointer to a CRuntimeClass. (That's why you don't see CRuntimeClass explicitly in the preceding code.)
In the class (refer to line 8 of Listing 20.6), you need to call the macro DECLARE_DYNAMIC(CTypeCheck)-with whatever class name it is-to generate the class code necessary to use MFC runtime checking. If you examine the macro defined in afx.h, you will see why a macro is used. The macro definition is shown in Listing 20.7.
Listing 20.7 afx.h-Short Listing Head
1: // Shows the non-DLL version of DECLARE_DYNAMIC 2: #define DECLARE_DYNAMIC(class_name) \ 3: public: \ 4: static AFX_DATA CRuntimeClass class##class_name; \ 5: virtual CRuntimeClass* GetRuntimeClass() const; \ 6: #endif
The macro adds two public declarations to your class (lines 4 and 5). Line 4 explains why you have to use macros: the ## is referred to as string-izing; in essence, the preprocessor generates code by concatenating a specific name-the one you passed to the macro-to the word class. Using our demo program, the resultant additional class definition looks like this for the CTypeCheck class:
public: static AFX_DATA CRuntimeClass classCTypeCheck; virtual CRuntimeClass * GetRuntimeClass() const;
If you generate a map file, it is easy to find the names in the produced symbol table. Fortunately, we only need to use the macros. Of course, if there are declarations in the class, then we need the definitions in the CPP file too. That's what the macro IMPLEMENT_DYNAMIC does on line 12. DECLARE_DYNAMIC makes the class entries and IMPLEMENT_DYNAMIC completes the definitions. It, too, is a macro because of the string-izing code generation performed by the preprocessor.
The definition of the RUNTIME_CLASS macro plays the same kind of role. It enables you to get the correct name when you are ready to use type checking. The definition
#define RUNTIME_CLASS(class_name) (&class_name::class##class_name)
of the macro produces a reference to the static class member. The code generated by the macro and preprocessor will be
(&CTypeCheck::classCTypeCheck)
and macros, again, were used for their ability to string-ize/generate code.
In line 16 of Listing 20.6 we use polymorphism to create a dynamic (heap-allocated) child type, pointed to by a CObject pointer. Then, in line 17, we use our rather contrived example to illustrate the use of the IsKindOf member and the RUNTIME_CLASS macro.
This type of runtime checking uses macro-trickery and contrivances. It will be ultimately better when RTTI is directly supported by the implementation. As a last word, before you resort to runtime checking, consider your design and see if virtual functions can provide the desired effect.
In this section we take a look at those data watching features that make debugging easier and more enjoyable. My favorite is probably Data Tips. Data Tips are those hint-like messages that are displayed when you place the mouse over an object or variable. Besides Data Tips, we look at how the QuickWatch dialog box, the tabbed Watch dialog box, and AutoExpand and AutoDowncast make your job considerably easier.
AutoDowncast was a feature in Visual C++ 2.0. It has been extended in this version to be a feature of QuickWatch windows (see fig. 20.16) as well as Watch windows (see fig. 20.17). AutoDowncasting is what the compiler does to enable you to access the members of a child class when what you have is a pointer to a parent class. What AutoDowncast does is add an extra pointer to a parent, so if you have a pointer object like CObject (refer to Listing 20.4), but it really points to a child class such as CPeople, you can see (in a watch window) the entire object. This feature makes it easier to debug when you are employing polymorphism.
AutoExpand is useful too. When debugging, AutoExpand shows you the important aspects of a watched object. If you look at Figure 20.18, you may notice that the internal CString object person (from the demo in Listing 20.4) shows the value we might be interested in as regards to a CString object. A CString contains many things, including a char * (which is an address and a length value), but what we are most interested in is AutoExpanded. You can certainly access the rest of the members, but this approach provides what is arguably the most useful data, conserving "screen real estate."
The Data Tips feature (see fig. 20.15) is my favorite. Simply pass the mouse over the object or variable name in the text window, and, as long as the object is in scope, a fly-by hint pops up showing you the AutoExpand value. The developers were even considerate enough to avoid evaluating objects or values that might throw exceptions.
Figure 20.15 : Shows a Data Tip displayed while an application is being run.
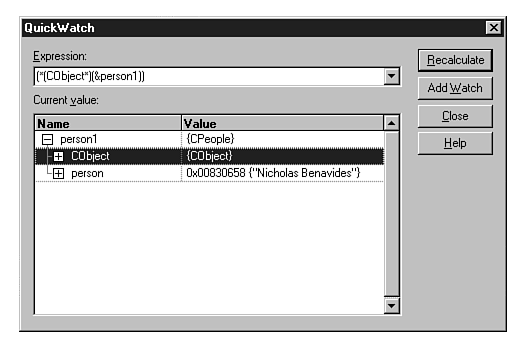
The QuickWatch window (see fig. 20.16) is easily accessed by placing the cursor on the object or variable in scope to be watched, clicking the right mouse button, and selecting QuickWatch. The QuickWatch window can be navigated by clicking plus symbols to expand nodes and minus symbols to collapse nodes. Note that in Figure 20.16-referring to the person member object-that the QuickWatch takes nice advantage of AutoExpand. With a QuickWatch view you can click the Add Watch button to add the current variable to one of the watch windows. Additionally, you can modify and Recalculate values in the QuickWatch window.
Figure 20.16 : The QuickWatch window.
The Watch window stays open permanently, as opposed to the QuickWatch, which is a modal dialog box. The Watch window has four tabs, as illustrated in Figure 20.17. You can group items on the watch window by regions, scope, file, or however it makes sense to solve the problem at hand. You can use the View, Watch menu command to display the watch, the right mouse speed menu to Hide the Watch, and add objects from the QuickWatch dialog box to open the watch. Select the Watch tab you want an object to be displayed on prior to adding the object from QuickWatch. An intuitive tool is one that does things you might suppose, and you can cut from the edit window and paste to a watch window too, bypassing the QuickWatch phase.
Figure 20.17 : Add elements to the tabbed Watch window from the QuickWatch dialog box.
A memory leak can be the most pernicious of errors. Memory leaks can take on many guises. You can introduce memory leaks in simple ways like forgetting to delete a heap-allocated object. You might accidentally delete a single element having allocated an array. Reassigning a pointer to a new heap without deallocating what was already pointed to leaves a hole of unrecoverable memory. Returning a reference to a chunk of memory from a function invites an opportunity for losing a block of memory.
The following fragments demonstrate the form of some very common errors that may not manifest themselves but cause memory leaks like those mentioned in the preceding paragraph.
// simple pointer leaving scope
{
int * one = new int;
*one = 1;
} // left scope no delete
// mismatched new and delete: new uses delete and new[] uses delete[]
{
float * f = new float[10];
// use array
delete f; // Oops! Deleted f[0] correct version is delete [] f;
}
// pointer of new memory goes out of scope before delete
{
const char * DeleteP = "Don't forget P";
char * p;
strcpy( p = new char[strlen(DeleteP) + 1], DeleteP );
} // scope ended (e.g. a function or arbitrary scope)
// before p delete[]
// returning heap allocated memory froma function
int * ReturnAnArrayOfIntegers()
{
return new int[100];
}
The code fragments all represent ways in which memory can be allocated and the references lost before deallocation. Once the reference-in simple terms a pointer-goes out of scope you cannot reclaim the memory and no one else can use it, either. The last sample is not an error, but it can be because it requires the user of the function to remember to be responsible for deleting the memory. (There is at least one standard library function, strdup, that employs this exact technique, however.)
There is an entire class of memory management problems that can introduce serious memory leaks. User defined memory management is challenging. Exceptions occurring in functions can bypass the call to delete when the stack unwinds. Sometimes programs seem to run perfectly for short periods, all the while dropping little chunks of memory. However, that same program seizes up after running for an extended period of time. Thus, the problem is twofold: one is to know an error exists, and the other is to find the source of the problem.
In this section are three methods that will assist you in discovering a leak, the well-spring from whence it came, and a technique introduced in the standard template library (STL)-a template class called auto_ptr-which even bottles up leaks occurring during an exception. Some of the memory sealing techniques covered in this section are:
You may certainly be able to disclose other tips for sealing memory leaks, but after having read this section, combining it with the rest of the chapter, you should be well armed in the war on bugs.
Here are some additional resource materials in the Help system you may find helpful:
You will find the CMemoryState class useful. It is easy to use and to the point. If you have a leak, it tells you (more or less) what, where, and how much. In keeping with the spirit of the user-friendliness of the MFC class CMemoryState, Listing 20.7 is an easy-to-follow, to the point program that demonstrates the kind of output you will get.
First, let me offer a few reminders. One is that this is a debug class, so you need to use conditional compiler directives to isolate the debug code. If you can localize that code, it makes the rest of your program more readable. When building a debug project, also remember that you will be linking the debug MFC libraries in by default. As a final note, if you get a linker LNK2001, then try rebuilding with the multi-threaded Debug libraries.
The code in Listing 20.7 simply allocates an array of characters that are not deallocated, causing a memory leak.
Listing 20.7 MemoryStateDemo.Cpp-Demonstrates the CmemoryState Class
1: // MemoryStateDemo.Cpp - Demonstrates using the MFC CMemoryState class
2: // Copyright 1996. All Rights Reserved.
3: // by Paul Kimmel
4: #include <afx.h>
5: #include <string.h>
6: // Using a macro cleans up the code where it is used.
7: #ifdef _DEBUG
8: CMemoryState start, stop, diff;
9: #define SnapShotStart() start.Checkpoint()
10: #define SnapShotStop() \
11: stop.Checkpoint(); \
12: if( diff.Difference( start, stop )) \
13: { TRACE( "Memory Leaked\n" ); \
14: diff.DumpStatistics(); \
15: }
16: #else
17: #define SnapShotStart()
18: #define SnapShotStop()
19: #endif
20:
21: int main()
22: {
23: const char * WELCOME = "Welcome to Valhalla Tower material ›;Defender!\n";
24: SnapShotStart();
25: // Wow! Looks like it could have some errors.
26: char * welcome;
27: strcpy( welcome = new char[strlen(WELCOME) + 1], WELCOME );
28: SnapShotStop();
29: return 0;
30: }
To use CMemoryState, you need to define three CMemoryState objects: one, which is used to take a snapshot of the heap for your starting point, another for an ending point, and a third to record the difference between the two. You can instantiate the three objects any time before you use them (refer to line 8). The snapshot is taken when you call the Checkpoint method (as in line 9). Passing the two relative points to the Difference method returns 0 if the images are identical, and returns non-zero otherwise.
Lines 7 through 19 can be written once, inserted into a header file, thus cleaning up your program and making it very easy to use this technique anywhere. The macro works simply: If the _DEBUG is defined, then the three objects and two other macros are defined. The macros (on lines 9 and 10 and 17 and 18 for non-debug versions) simply enable the preprocessor to paste the code automatically wherever they are used.
The code on lines 9 through 15 call start.Checkpoint(), stop.Checkpoint(), and the diff.Checkpoint(), spitting out the Difference (see Listing 20.8) if the two heap states differ. The addition of the TRACE macro (line 13) helps make it evident that what you are seeing is a memory leak condition. However, if you check Listing 20.8 you may notice that the CMemoryState object also did that on line 9.
If _DEBUG is undefined, as is the case with the Release build, then the macros are stripped out by the preprocessor. Note that the use of the CMemoryState object becomes very clean (lines 24 and 28).
The sample code on lines 20 to 21 allocate a dynamic character array with that bit of esoteric code on line 27, purposely forgetting to return the memory to the heap. Line 27 is a necessary reminder to add 1 to any string length, for the null character. As an exercise, remove that and see if the CMemoryState objects catch you.
Listing 20.8 Output from MemoryStateDemo.Exe
1: Memory Leaked
2: 0 bytes in 0 Free Blocks.
3: 46 bytes in 1 Normal Blocks.
4: 0 bytes in 0 CRT Blocks.
5: 0 bytes in 0 Ignore Blocks.
6: 0 bytes in 0 Client Blocks.
7: Largest number used: 46 bytes.
8: Total allocations: 46 bytes.
9: Detected memory leaks!
10: Dumping objects ->
11: {18} normal block at 0x00830658, 46 bytes long.
12: Data: <Welcome to Valha> 57 65 6C 63 6F 6D 65 20 74 6F 20 56 61 6C 68 61
13: Object dump complete.
14: The program MemoryStateDemo.exe has exited with code 0 (0x0).
As you can see from Listing 20.8, the CMemoryState.Difference() method provides quite a bit of detail. Here is a brief explanation. Line 1 is the output from TRACE. Line 3 indicates our error: that there were 46 bytes in one block leaked. And line 9 sums it all up nicely; there were errors. A complete explanation is found in the online help in the article Diagnostics: Detecting Memory Leaks. In essence, each line tells you the kind of memory leaked.
The last example provided us with a lot of information. Fortunately for us, though, the program was contrived, because, as is, it is easy to figure out what went wrong. In a real program, it may not be so easy. A straightforward modification to the way we do business, at no extra Release build cost, and MFC gives us the added information that makes it a trivial matter to track down the culprit.
The DEBUG_NEW macro works just like new when you build the release version. More importantly is what it does when you are debugging. When you are building the Debugging version of your application the DEBUG_NEW macro enables the preprocessor to include an overloaded new operator which tags a file name and line number to every allocation. The CMemoryState object can use this information when you DumpStatistics, for example.
| NOTE |
As a reminder new and delete are operators, though they may appear to be more appropriately labeled as functions. And, almost all operators are overloadable, which includes new and delete. The file name and line number are already maintained by the compiler in __LINE__ and __FILE__, using a macro enables the overloaded new an oppotunity to use these maintained macros. |
If we had used DEBUG_NEW, line 11 of Listing 20.8 goes from
11: {18} normal block at 0x00830658, 46 bytes long.
to the more explicit
11. MemoryStateDemo.Cpp(36) : {18} normal block at 0x00830658, 46 bytes long
Notice that the file and the line number are added to the Dump. The (36) right after the file name is the line number. (White space is removed in the text listing. That is why the listing line numbers in 20.6 and the output do not jive.)
Using DEBUG_NEW is easy too. To use it define a macro for the regular new
#define new DEBUG_NEW
This macro enables you to use new as before and the preprocessor plugs in the DEBUG_NEW call, which by the way, is the debug version during the debug build and regular for the Release build. The document Diagnostics: Tracking memory Allocations will also inform you that if you use the macros IMPLEMENT_DYNCREATE and/or IMPLEMENT_SERIAL then define the macro (#define new DEBUG_NEW) after the last use of these macros. That's all there is to it.
What is an auto_ptrfunction class and why should you consider using it? To clearly understand how an auto_ptr class is contrived and why it works, let's consider some related, general background information, before we dive into an implementation.
When a program is executing within a particular scope, like a function, all variables allocated in that function are generally allocated in the stack space. The stack, like an accordion, shrinks and grows. It does so because it is a temporary storage space. The stack is used to store the current execution address prior to a function call, the arguments passed to the function, and the local function objects and variables. When the function returns, the stack pointer is reset to that location where the prior execution point was stored. (You have little control over this process.)
Effectively, by restoring the stack pointer to its position prior
to the function call, the program has made the space available
to whatever else needs it, which means those elements allocated
on the stack in the function are gone. This process is referred
to as stack unwinding.
| NOTE |
Objects or variables defined with the keyword static are not allocated on the stack |
Stack unwinding is also what happens when an unhandled exception occurs. To reliably restore the program to its state before an exception occurred in the function, the stack is unwound. Stack-wise variables are gone and the destructors for stack-wise objects are called and are also gone. Unfortunately, the same is not true for dynamic objects. The handles (for example, pointers) are unwound but delete is never called. The result is the slicing problem.
| NOTE |
The slicing problem refers to memory leaks caused by pointers that lose the address of heap allocated memory before delete is called. |
It may be easy enough to handle this problem by putting exception handlers everywhere you use new and delete, placing the new in a try block and delete in a catch block, but then you would have messy exception handlers everywhere.
The smart pointer class implemented in the standard template library solves the problem. Basically, the clever designers implemented a template class. (Listing 20.9 demonstrates some of the key members required to make the class work.)
Listing 20.9 A Scaled Down Version of the auto_ptr Class
1: // This class is not complete. Use the complete definition in the
›;Standard Template Library.
2: template <class T>
3: class auto_ptr
4: {
5: public:
6: auto_ptr( T *p = 0) : rep(p) {} // store pointer in the class
7: ~auto_ptr(){ delete rep; } // delete internal rep
8: // include pointer conversion members
9: inline T* operator->() const { return rep; }
10: inline T& operator*() const { return *rep; }
11: private:
12: T * rep;
13: };
The class encapsulates the pointer, providing access through operator functions. Instantiating an object, given some class C, with the auto_ptr might look something like this:
auto_ptr<C> dialog_ptr(new C());
Now we can access members of C via the auto_ptr, like this:
dialog_ptr->Method(); // pseudo-code
We do not have to explicitly delete this object, even in the event of an exception, because the auto_ptr is a stack-wise object. When a stack-wise object goes out of scope, its destructor is called and, in this case, it calls delete on the contained object C.
There are many aspects of C++ you have to master before creating and using classes like this. You must understand the template idiom, operator and function overloading, and you must learn to use the classes in the STL.
The preceding stripped down class is intentionally incomplete; there are many issues left that must be addressed for a complete definition of the class.
In this chapter, you were introduced to existing concepts as they are implemented in Visual C++ and MFC and new concepts that will help you eke the bugs out of all of your code. No one technique is sufficiently more important to mitigate the necessity for learning the others, but if you have to choose a particular tactic to master first, then choose assert. Assert everything. If you do not know what testable values and assumptions are for the code you are writing, reconsider using that algorithm at all.
Some techniques, like the way MFC implements runtime checking, are unique to Microsoft's implementation of C++. Expect to see the ANSI C++ standard adopted in the near future. There are many topics you can learn to master writing bug-free code. Many of those topics, like code-tracing, assertions, using the IDE, and implementing smart pointers, were discussed in this chapter.
There are many interesting discussions, articles, and books on writing bug-free code. Since maintenance and testing encompass the greatest cost, it makes good dollar sense to spend at least as much time and resource dollars on using the bug hunting techniques described in this chapter as you spend on every other aspect of programming, if not more.
To learn about other techniques and tools, see these chapters: