{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




by Michael Morrison
Few programs can be developed without at least some usage of data structures, which are responsible for storing and maintaining information used by a program. Whether you develop your own data structures from scratch or rely on those developed and tested by others, you will undoubtedly need to use data structures at some point in your Java programming endeavors. Today's lesson takes a look at data structures as they relate to Java. It covers the following topics:
By the end of today's lesson, you'll have a good idea of what data structures are readily available in the standard Java packages, along with some data structures you can implement yourself without too much pain. Let's get started!
Like algorithms in general, data structures are one of those general concepts in computer science whose usefulness spreads far and wide. Consequently, a solid understanding of data structures and when to apply certain ones is the trademark of any good programmer. Java programming is no different, and you should take data structures no less seriously in Java than in any other language. Just because many Java programs come in the form of applets, which sound cuter and less auspicious than C or C++ applications, doesn't mean that they don't rely on a solid means of storing and manipulating data.
Almost every Java applet works with information to some extent. Even very simple animation applets that display a series of images must somehow store the images in such a way that the images can be referenced quickly. In this example, a very elementary data structure such as an array might be the best solution, since all that is required of the data structure is the storage of multiple images. Even so, consider the fact that every program has its own set of data requirements that greatly affect the applicability of different data structures. If you don't understand the full range of programming options in terms of data structures, you'll find yourself trying to use an array in every program you write. This tendency to rely on one solution for all your programming problems will end up getting you into trouble. In other words, by understanding how to use a wide variety of data structures, you broaden your perspective on how to solve the inevitable problems arising from new programming challenges.
I mentioned arrays being a very simple data structure. In fact, outside of member variables themselves, arrays are the most simple data structure supported by Java. An array is simply an aggregate series of data elements of the same type. I say that arrays are aggregate because they are treated as a single entity, just like any other member variable. However, they actually contain multiple elements that can be accessed independently. Based on this description, it's logical that arrays are useful any time you need to store and access a group of information that is all of the same type. For example, you could store your picks for a lottery in an array of integers. However, the glaring limitation of arrays is that they can't change in size to accommodate more (or fewer) elements. This means that you can't add new elements to an array that is already full.
It turns out that the data requirements for many practical programs
reach far beyond what arrays provide. In other languages, it is
often necessary to develop custom data structures whenever the
requirements go beyond arrays. However, the Java class library
provides a set of data structures in the java.util
package that give you a lot more flexibility in how to approach
organizing and manipulating data. There still may be situations
in which these standard data structures don't fit your needs,
in which case you'll have to write your own. You'll learn how
to implement your own custom data structures later in today's
lesson.
| Technical Note |
Unlike the data structures provided by the java.util package, arrays are considered such a core component of the Java language that they are implemented in the language itself. Therefore, you can use arrays in Java without importing any packages. |
The data structures provided by the Java utility package are very powerful and perform a wide range of functions. These data structures consist of the following interface and five classes:
The Enumeration interface isn't itself a data structure, but it is very important within the context of other data structures. The Enumeration interface defines a means to retrieve successive elements from a data structure. For example, Enumeration defines a method called nextElement that is used to get the next element in a data structure that contains multiple elements.
The BitSet class implements
a group of bits, or flags, that can be set and cleared individually.
This class is very useful in cases where you need to keep up with
a set of boolean values; you just assign a bit to each value and
set or clear it as appropriate.
| New Term |
A flag is a boolean value that is used to represent one of a group of on/off type states in a program. |
The Vector class is similar to a traditional Java array, except that it can grow as necessary to accommodate new elements. Like an array, elements of a Vector object can be accessed via an index into the vector. The nice thing about using the Vector class is that you don't have to worry about setting it to a specific size upon creation; it shrinks and grows automatically when necessary.
The Stack class implements a last-in-first-out (LIFO) stack of elements. You can think of a stack literally as a vertical stack of objects; when you add a new element, it gets stacked on top of the others. When you pull an element off the stack, it comes off the top. In other words, the last element you added to the stack is the first one to come back off.
The Dictionary class is an
abstract class that defines a data structure for mapping keys
to values. This is useful in cases where you want to be able to
access data via a particular key rather than an integer index.
Since the Dictionary class
is abstract, it provides only the framework for a key-mapped data
structure rather than a specific implementation.
| New Term |
A key is a numeric identifier used to reference, or look up, a value in a data structure. |
An actual implementation of a key-mapped data structure is provided by the Hashtable class. The Hashtable class provides a means of organizing data based on some user-defined key structure. For example, in an address list hash table you could store and sort data based on a key such as ZIP code rather than on a person's name. The specific meaning of keys in regard to hash tables is totally dependent on the usage of the hash table and the data it contains.
That pretty well sums up the data structures provided by the Java utility package. Now that you have a cursory understanding of them, let's dig into each in a little more detail and see how they work.
The Enumeration interface provides a standard means of iterating through a list of sequentially stored elements, which is a common task of many data structures. Even though you can't use the interface outside the context of a particular data structure, understanding how it works will put you well on your way to understanding other Java data structures. With that in mind, take a look at the only two methods defined by the Enumeration interface:
public abstract boolean hasMoreElements(); public abstract Object nextElement();
The hasMoreElements method is used to determine if the enumeration contains any more elements. You will typically call this method to see if you can continue iterating through an enumeration. An example of this is calling hasMoreElements in the conditional clause of a while loop that is iterating through an enumeration.
The nextElement method is responsible for actually retrieving the next element in an enumeration. If no more elements are in the enumeration, nextElement will throw a NoSuchElementException exception. Since you want to avoid generating exceptions whenever possible, you should always use hasMoreElements in conjunction with nextElement to make sure there is another element to retrieve. Following is an example of a while loop that uses these two methods to iterate through a data structure object that implements the Enumeration interface:
// e is an object that implements the Enumeration interface
while (e.hasMoreElements()) {
Object o = e.nextElement();
System.out.println(o);
}
This sample code prints out the contents of an enumeration using
the hasMoreElements and nextElement
methods. Pretty simple!
| Technical Note |
Since Enumeration is an interface, you'll never actually use it as a data structure directly. Rather, you will use the methods defined by Enumeration within the context of other data structures. The significance of this architecture is that it provides a consistent interface for many of the standard data structures, which makes them easier to learn and use. |
The BitSet class is useful whenever you need to represent a group of boolean flags. The nice thing about the BitSet class is that it allows you to use individual bits to store boolean values without the mess of having to extract bit values using bitwise operations; you simply refer to each bit using an index. Another nice feature about the BitSet class is that it automatically grows to represent the number of bits required by a program. Figure 23.1 shows the logical organization of a bit set data structure.
Figure 23.1 : The logical organization of a bit set data structure.
For example, you can use BitSet as an object that has a number of attributes that can easily be modeled by boolean values. Since the individual bits in a bit set are accessed via an index, you can define each attribute as a constant index value:
class someBits {
public static final int readable = 0;
public static final int writeable = 1;
public static final int streamable = 2;
public static final int flexible = 3;
}
Notice that the attributes are assigned increasing values, beginning with 0. You can use these values to get and set the appropriate bits in a bit set. But first, you need to create a BitSet object:
BitSet bits = new BitSet();
This constructor creates a bit set with no specified size. You can also create a bit set with a specific size:
BitSet bits = new BitSet(4);
This creates a bit set containing four boolean bit fields. Regardless of the constructor used, all bits in new bit sets are initially set to false. Once you have a bit set created, you can easily set and clear the bits using the set and clear methods along with the bit constants you defined:
bits.set(someBits.writeable); bits.set(someBits.streamable); bits.set(someBits.flexible); bits.clear(someBits.writeable);
In this code, the writeable, streamable, and flexible attributes are set, and then the writeable bit is cleared. Notice that the fully qualified name is used for each attribute, since the attributes are declared as static in the someBits class.
You can get the value of individual bits in a bit set using the get method:
boolean canIWrite = bits.get(someBits.writeable);
You can find out how many bits are being represented by a bit set using the size method. An example of this follows:
int numBits = bits.size();
The BitSet class also provides other methods for performing comparisons and bitwise operations on bit sets such as AND, OR, and XOR. All these methods take a BitSet object as their only parameter.
The Vector class implements a growable array of objects. Since the Vector class is responsible for growing itself as necessary to support more elements, it has to decide when and by how much to grow as new elements are added. You can easily control this aspect of vectors upon creation. Before getting into that, however, take a look at how to create a basic vector:
Vector v = new Vector();
That's about as simple as it gets! This constructor creates a
default vector containing no elements. Actually, all vectors are
empty upon creation. One of the attributes important to how a
vector sizes itself is the initial capacity of a vector, which
is how many elements the vector allocates memory for by default.
| New Term |
The size of a vector is the number of elements currently stored in the vector. |
| New Term |
The capacity of a vector is the amount of memory allocated to hold elements, and is always greater than or equal to the size. |
The following code shows how to create a vector with a specified capacity:
Vector v = new Vector(25);
This vector is created to immediately support up to 25 elements. In other words, the vector will go ahead and allocate enough memory to support 25 elements. Once 25 elements have been added, however, the vector must decide how to grow itself to accept more elements. You can specify the value by which a vector grows using yet another Vector constructor:
Vector v = new Vector(25, 5);
This vector has an initial size of 25 elements, and will grow in increments of 5 elements whenever its size grows to more than 25 elements. This means that the vector will first jump to 30 elements in size, then 35, and so on. A smaller grow value for a vector results in more efficient memory management, but at the cost of more execution overhead since more memory allocations are taking place. On the other hand, a larger grow value results in fewer memory allocations, but sometimes memory may be wasted if you don't use all the extra space created.
Unlike with arrays, you can't just use square brackets ([]) to access the elements in a vector; you have to use methods defined in the Vector class. To add an element to a vector, you use the addElement method:
v.addElement("carrots");
v.addElement("broccoli");
v.addElement("cauliflower");
This code shows how to add some vegetable strings to a vector. To get the last string added to the vector, you can use the lastElement method:
String s = (String)v.lastElement();
The lastElement method retrieves the last element added to the vector. Notice that you have to cast the return value of lastElement, since the Vector class is designed to work with the generic Object class. Although lastElement certainly has its usefulness, you will probably find more use with the elementAt method, which allows you to index into a vector to retrieve an element. Following is an example of using the elementAt method:
String s1 = (String)v.elementAt(0); String s2 = (String)v.elementAt(2);
Since vectors are zero based, the first call to elementAt retrieves the "carrots" string, and the second call retrieves the "cauliflower" string. Just as you can retrieve an element at a particular index, you can also add and remove elements at an index using the insertElementAt and removeElementAt methods:
v.insertElementAt("squash", 1);
v.insertElementAt("corn", 0);
v.removeElementAt(3);
The first call to insertElementAt inserts an element at index 1, between the "carrots" and "broccoli" strings. The "broccoli" and "cauliflower" strings are moved up a space in the vector to accommodate the inserted "squash" string. The second call to insertElementAt inserts an element at index 0, which is the beginning of the vector. In this case, all existing elements are moved up a space in the vector to accommodate the inserted "corn" string. At this point, the contents of the vector look like this:
"corn" "carrots" "squash" "broccoli" "cauliflower"
The call to removeElementAt removes the element at index 3, which is the "broccoli" string. The resulting contents of the vector consist of the following strings:
"corn" "carrots" "squash" "cauliflower"
You can use the setElementAt method to change a specific element:
v.setElementAt("peas", 1);
This method replaces the "carrots" string with the "peas" string, resulting in the following vector contents:
"corn" "peas" "squash" "cauliflower"
If you want to clear out the vector completely, you can remove all the elements with the removeAllElements method:
v.removeAllElements();
The Vector class also provides some methods for working with elements without using indexes. These methods actually search through the vector for a particular element. The first of these methods is the contains method, which simply checks to see if an element is in the vector:
boolean isThere = v.contains("celery");
Another method that works in this manner is the indexOf method, which finds the index of an element based on the element itself:
int i = v.indexOf("squash");
The indexOf method returns
the index of the element in question if it is in the vector, or
-1 if not. The removeElement
method works similarly in that it removes an element based on
the element itself rather than on an index:
v.removeElement("cauliflower");
If you're interested in working with all the elements in a vector sequentially, you can use the elements method, which returns an enumeration of the elements:
Enumeration e = v.elements();
Recall from earlier in today's lesson that you can use an enumeration to step through elements sequentially. In this example, you can work with the enumeration e using the methods defined by the Enumeration interface.
You may find yourself wanting to work with the size of a vector. Fortunately, the Vector class provides a few methods for determining and manipulating the size of a vector. First, the size method determines the number of elements in the vector:
int size = v.size();
If you want to explicitly set the size of a vector, you can use the setSize method:
v.setSize(10);
The setSize method expands or truncates the vector to accommodate the new size specified. If the vector is expanded because of a larger size, null elements are inserted as the newly added elements. If the vector is truncated, any elements at indexes beyond the specified size are discarded.
If you recall, vectors have two different attributes relating to size: size and capacity. The size is the number of elements in the vector and the capacity is the amount of memory allocated to hold all elements. The capacity is always greater than or equal to the size. You can force the capacity to exactly match the size using the trimToSize method:
v.trimToSize();
You can also check to see what the capacity is, using the capacity method:
int capacity = v.capacity();
You'll find that the Vector class is one of the most useful data structures provided in the Java API. Hopefully this tour of the class gives you an idea of how powerful vectors are and how easy it is to use them.
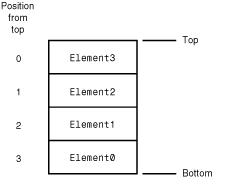
Stacks are a classic data structure used to model information that is accessed in a specific order. The Stack class in Java is implemented as a last-in-first-out (LIFO) stack, which means that the last item added to the stack is the first one to come back off. Figure 23.2 shows the logical organization of a stack.
Figure 23.2 : The logical organization of a stack data structure.
You may be wondering from Figure 23.2 why the numbers of the elements don't match their position from the top of the stack. Keep in mind that elements are added to the top, so Element0, which is on the bottom, was the first element added to the stack. Likewise, Element3, which is on top, is the last element added to the stack. Also, since Element3 is at the top of the stack, it will be the first to come back off.
The Stack class only defines one constructor, which is a default constructor that creates an empty stack. You use this constructor to create a stack like this:
Stack s = new Stack();
You add new elements to a stack using the push method, which pushes an element onto the top of the stack:
s.push("One");
s.push("Two");
s.push("Three");
s.push("Four");
s.push("Five");
s.push("Six");
This code pushes six strings onto the stack, with the last string ("Six") remaining on top. You pop elements back off the stack using the pop method:
String s1 = (String)s.pop(); String s2 = (String)s.pop();
This code pops the last two strings off the stack, leaving the first four strings remaining. This code results in the s1 variable containing the "Six" string and the s2 variable containing the "Five" string.
If you want to get the top element on the stack without actually popping it off the stack, you can use the peek method:
String s3 = (String)s.peek();
This call to peek returns the "Four" string but leaves the string on the stack. You can search for an element on the stack using the search method:
int i = s.search("Two");
The search method returns
the distance from the top of the stack of the element if it is
found, or -1 if not. In this
case, the "Two"
string is the third element from the top, so the search
method returns 2 (zero based).
| Technical Note |
As in all Java data structures that deal with indexes or lists, the Stack class reports element position in a zero-based fashion. This means that the top element in a stack has a location of 0, and the fourth element down in a stack has a location of 3. |
The only other method defined in the Stack class is empty, which determines whether a stack is empty:
boolean isEmpty = s.empty();
Although maybe not quite as useful as the Vector class, the Stack class provides the functionality for a very common and established data structure.
The Dictionary class defines a framework for implementing a basic key-mapped data structure. Although you can't actually create Dictionary objects since the class is abstract, you can still learn a lot about key-mapped data modeling by learning how the Dictionary class works. You can put the key-mapped approach to work using the Hashtable class, which is derived from Dictionary, or by deriving your own class from Dictionary. You learn about the Hashtable class in the next section of today's lesson.
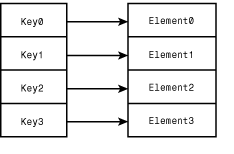
The Dictionary class defines a means of storing information based on a key. This is similar in some ways to how the Vector class works, in that elements in a vector are accessed via an index, which is a specific type of key. However, keys in the Dictionary class can be just about anything. You can create your own class to use as the keys for accessing and manipulating data in a dictionary. Figure 23.3 shows how keys map to data in a dictionary.
Figure 23.3 : The logical organization of a dictionary data structure.
The Dictionary class defines a variety of methods for working with the data stored in a dictionary. All these methods are defined as abstract, meaning that derived classes will have to implement all of them to actually be useful. The put and get methods are used to put objects in the dictionary and get them back. Assuming dict is a Dictionary-derived class that implements these methods, the following code shows how to use the put method to add elements to a dictionary:
dict.put("small", new Rectangle(0, 0, 5, 5));
dict.put("medium", new Rectangle(0, 0, 15, 15));
dict.put("large", new Rectangle(0, 0, 25, 25));
This code adds three rectangles to the dictionary, using strings as the keys. To get an element from the dictionary, you use the get method and specify the appropriate key:
Rectangle r = (Rectangle)dict.get("medium");
You can also remove an element from the dictionary with a key using the remove method:
dict.remove("large");
You can find out how many elements are in the dictionary using the size method, much as you did with the Vector class:
int size = dict.size();
You can also check whether the dictionary is empty using the isEmpty method:
boolean isEmpty = dict.isEmpty();
Finally, the Dictionary class includes two methods for enumerating the keys and values contained within: keys and elements. The keys method returns an enumeration containing all the keys contained in a dictionary, while the elements method returns an enumeration of all the key-mapped values contained. Following is an example of retrieving both enumerations:
Enumeration keys = dict.keys(); Enumeration elements = dict.elements();
Note that since keys are mapped to elements on a one-to-one basis, these enumerations are of equal length.
The Hashtable class is derived from Dictionary and provides a complete implementation of a key-mapped data structure. Similar to dictionaries, hash tables allow you to store data based on some type of key. Unlike dictionaries, hash tables have an efficiency associated with them defined by the load factor of the table.
The load factor of a hash table is a number between 0.0 and 1.0 that determines how and when the hash table allocates space for more elements.
Like vectors, hash tables have a capacity, which is the amount of memory allocated for the table. Hash tables allocate more memory by comparing the current size of the table with the product of the capacity and the load factor. If the size of the hash table exceeds this product, the table increases its capacity by rehashing itself.
Load factors closer to 1.0 result in a more efficient use of memory at the expense of a longer look-up time for each element. Similarly, load factors closer to 0.0 result in more efficient look-ups but also tend to be more wasteful with memory. Determining the load factor for your own hash tables is really dependent on the usage of the hash table and whether your priority is on performance or memory efficiency.
You create hash tables using one of three methods. The first method creates a default hash table:
Hashtable hash = new Hashtable();
The second constructor creates a hash table with the specified initial capacity:
Hashtable hash = new Hashtable(20);
Finally, the third constructor creates a hash table with the specified initial capacity and load factor:
Hashtable hash = new Hashtable(20, 0.75);
All the abstract methods defined in Dictionary are implemented in the Hashtable class. Since these methods perform the exact same function in Hashtable, there's no need to cover them again. However, they are listed here just so you'll have an idea of what support Hashtable provides:
elements get isEmpty keys put remove size
In addition to these methods, the Hashtable class implements a few others that perform functions specific to supporting hash tables. One of these is the clear method, which clears a hash table of all its keys and elements:
hash.clear();
The contains method is used to see if an object is stored in the hash table. This method searches for an object value in the hash table rather than a key. The following code shows how to use the contains method:
boolean isThere = hash.contains(new Rectangle(0, 0, 5, 5));
Similar to contains, the containsKey method searches a hash table, but it searches based on a key rather than a value:
boolean isThere = hash.containsKey("Small");
I mentioned earlier that a hash table will rehash itself when it determines that it must increase its capacity. You can force a rehash yourself by calling the rehash method:
hash.rehash();
That pretty much sums up the important methods implemented by
the Hashtable class. Even
though you've seen all the methods, you still may be wondering
exactly how the Hashtable
class is useful. The practical usage of a hash table is actually
in representing data that is too time-consuming to search or reference
by value. In other words, hash tables often come in handy when
you're working with complex data, where it's much more efficient
to access the data using a key rather than by comparing the data
objects themselves. Furthermore, hash tables typically compute
a key for elements, which is called a hash code. For example,
an object such as a string can have an integer hash code computed
for it that uniquely represents the string. When a bunch of strings
are stored in a hash table, the table can access the strings using
integer hash codes as opposed to using the contents of the strings
themselves. This results in much more efficient searching and
retrieving capabilities.
| New Term |
A hash code is a computed key that uniquely identifies each element in a hash table. |
This technique of computing and using hash codes for object storage and reference is exploited heavily throughout the Java system. This is apparent in the fact that the parent of all classes, Object, defines a hashCode method that is overridden in most standard Java classes. Any class that defines a hashCode method can be efficiently stored and accessed in a hash table. A class wishing to be hashed must also implement the equals method, which defines a way of telling if two objects are equal. The equals method usually just performs a straight comparison of all the member variables defined in a class.
Hash tables are an extremely powerful data structure that you will probably want to integrate into some of your programs that manipulate large amounts of data. The fact that they are so widely supported in the Java API via the Object class should give you a clue as to their importance in Java programming.
Even though the Java utility package provides some very powerful and useful data structures, there may be situations in which you need something a little different. I encourage you to make the most of the standard Java data structures whenever possible, since reusing stable code is always a smarter solution than writing your own code. However, in cases where the standard data structures just don't seem to fit, you may need to turn your attention toward other options.
Throughout the rest of today's lesson you'll learn all about one of these other options. More specifically, you'll learn about linked lists, which are a very useful type of data structure not provided in the standard Java data structures. Not only will you learn about linked lists, but you'll also develop your own linked list class that you can reuse in your own Java programs. You'll see that building custom data structures isn't all that difficult. Let's get started!
Like vectors and arrays, linked lists are used to store a sequential list of objects. The primary difference between these data structures is that arrays and vectors are better at referencing elements via a numeric index, whereas linked lists are better at accessing data in a purely sequential manner. In other words, linked lists aren't suited for the type of random access provided by arrays and vectors. This may seem like a limitation of linked lists, but it is in fact what makes them unique as a data structure; they are much more efficient when it comes to adding, inserting, and removing elements.
To get a better idea of why linked lists have the properties mentioned, take a look at the logical organization of linked lists shown in Figure 23.4.
Figure 23.4 : The logical organization of a doubly linked list data structure.
The figure shows the linked list having a distinct start and end, which is somewhat different from arrays and vectors. Sure, arrays and vectors have a first element and a last element, but the elements have no more significance than any other elements. The start and end of linked lists are a strict requirement since linked lists don't hold elements in a fixed amount of memory. This actually touches on the biggest difference between linked lists and vectors/arrays. Linked lists simply hold references to the start and end elements contained within, whereas vectors and arrays contain references to all of their elements.
Another key point to note from Figure 23.4 is that each element in a linked list contains a reference to both the element before and the element after it. This is how elements in linked lists are accessed: by traversing the list through the references to successive elements. In other words, to get the third element in a linked list, you have to start with the first element and follow its reference to the second element, and then repeat the process to get to the third element. This may seem like a tedious process, but it actually works quite well in some situations.
In the discussion thus far, I've glossed over one fine point in regard to linked lists, and that is the two types of linked lists. The type shown in Figure 23.4 is called a doubly linked list because it contains references to both the element following and the element preceding a particular element. Another popular type of linked list is the singly linked list, where each element contains only a reference to the element following it. Figure 23.5 shows the logical organization of a singly linked list.
Figure 23.5 : The logical organization of a singly linked list data structure.
Since doubly linked lists tend to be more general and therefore have a wider range of application, you'll focus on them in today's lesson. Besides, a doubly linked list is really just a singly linked list with more features, which means you can use it just like a singly linked list if you want.
Now that you have an idea of what a linked list is, let's go ahead and take a stab at developing a fully functioning linked list class. Before jumping into the details of a specific linked list implementation, however, consider the fact that the linked list class you're developing is actually an extension to the standard Java data structures you learned about earlier today. This means that it is to your advantage to design the class to fit in well with the design of the existing data structures. A good approach, then, would be to model the linked list class around the Vector class, at least in regard to some of the basic techniques of manipulating elements through methods. The reason for this is so anyone else using your linked list class can easily see how to use the class based on their understanding of other standard Java classes like Vector. This mindset in terms of extending the standard Java classes is very important when it comes to writing reusable code.
Even though I've been discussing the linked list implementation in terms of a single class, it turns out that it takes a few classes to realistically build a complete linked list. These classes consist of a linked list class, a linked list entry class, and a linked list enumeration class. The linked list class models the list itself and is the only class anyone using the linked list will come into contact with. The other two classes are helper classes that provide some type of behind-the-scenes functionality for the linked list class. The linked list entry class models an individual element within the linked list, and the linked list enumerator class provides support for the Enumeration interface.
Since it is by far the most simple of the three classes, let's start by looking at the linked list entry class, which is called LinkedListEntry:
class LinkedListEntry {
protected Object val = null;
protected LinkedListEntry next = null;
protected LinkedListEntry prev = null;
public LinkedListEntry(Object obj) {
// Make sure the object is valid
if (obj == null)
throw new NullPointerException();
val = obj;
}
}
The LinkedListEntry class contains three member variables that keep up with the value of the entry (the element being stored) and a reference to the next and previous elements. This class has a single constructor defined, which simply checks the validity of the object being stored in the entry and assigns it to the entry's val member variable.
Based on the simplicity of LinkedListEntry, you're probably guessing that most of the functionality of the linked list is provided by the main linked list class. You guessed right! This class is called LinkedList and contains a few member variables, which follow:
protected LinkedListEntry start = null; protected LinkedListEntry end = null; protected int numElements;
The start and end member variables hold references to the beginning and end elements in the list, while the numElements member keeps up with the size of the list. There are also a variety of methods defined in the LinkedList class that resemble methods in the Vector class. One of the most important methods is addElement, which adds a new element to the end of the list. The source code for addElement is shown in Listing 23.1.
Listing 23.1. The LinkedList class's addElement method.
1: public void addElement(Object obj) {
2: // Make sure the object is valid
3: if (obj == null)
4: throw new NullPointerException();
5:
6: // Create the new entry
7: LinkedListEntry newElement = new LinkedListEntry(obj);
8: numElements++;
9:
10: // See if the new element is the start of the list
11: if (start == null) {
12: start = newElement;
13: end = newElement;
14: }
15: else {
16: end.next = newElement;
17: newElement.prev = end;
18: end = newElement;
19: }
20: }
| Analysis |
The addElement method first checks to make sure the new object is valid. It then creates an entry to hold the object and checks to see if the new element will be placed at the start of the list. addElement then adjusts the references of elements related to the new element so the list's structure is maintained. |
Just as the addElement method is important for adding a new element to the end of the list, the insertElementAt method is useful for inserting a new element at any point in the list. Listing 23.2 contains the source code for insertElementAt.
Listing 23.2. The LinkedList class's insertElementAt method.
1: public void insertElementAt(Object obj, Object pos) {
2: // Make sure the objects are valid
3: if (obj == null || pos == null)
4: throw new NullPointerException();
5:
6: // Make sure the position object is in the list
7: LinkedListEntry posEntry = find(pos);
8: if (posEntry == null)
9: throw new NullPointerException();
10:
11: // Create the new entry
12: LinkedListEntry newElement = new LinkedListEntry(obj);
13: numElements++;
14:
15: // Link in the new entry
16: newElement.next = posEntry;
17: newElement.prev = posEntry.prev;
18: if (posEntry == start)
19: start = newElement;
20: else
21: posEntry.prev.next = newElement;
22: posEntry.prev = newElement;
23: }
| Analysis |
The insertElementAt method takes two parameters that specify the new object to be added to the list, along with the object at the position where the new object is to be inserted. insertElementAt first makes sure both objects are valid; then it checks to see if the position object is in the list. If things are okay at this point, a new entry is created to hold the new object, and the references of adjacent elements are adjusted to reflect the insertion. |
At this point you have two methods that allow you to add and insert elements to the linked list. However, there still isn't any means to remove elements from the list. Enter the removeElement method! Listing 23.3 contains the source code for removeElement, which allows you to remove an element by specifying the object itself.
Listing 23.3. The LinkedList class's removeElement method.
1: public boolean removeElement(Object obj) {
2: // Make sure the object is valid
3: if (obj == null)
4: throw new NullPointerException();
5:
6: // Make sure the object is in the list
7: LinkedListEntry delEntry = find(obj);
8: if (delEntry == null)
9: return false;
10:
11: // Unlink the entry
12: numElements--;
13: if (delEntry == start)
14: start = delEntry.next;
15: else
16: delEntry.prev.next = delEntry.next;
17: if (delEntry == end)
18: end = delEntry.prev;
19: else
20: delEntry.next.prev = delEntry.prev;
21: return true;
22: }
| Analysis |
The removeElement method first checks to see if the object passed in is valid, and then searches to make sure the object is in the list. It performs the search by calling the find method, which is a private method you'll learn about in just a moment. Upon finding the entry in the list, the removeElement method unlinks the entry by adjusting the references of adjacent entries. |
The find method is a private method used internally by the LinkedList class to find entries in the list based on the object they store. Following is the source code for the find method:
private LinkedListEntry find(Object obj) {
// Make sure the list isn't empty and the object is valid
if (isEmpty() || obj == null)
return null;
// Search the list for the object
LinkedListEntry tmp = start;
while (tmp != null) {
if (tmp.val == obj)
return tmp;
tmp = tmp.next;
}
return null;
}
The find method first checks to make sure the list isn't empty and that the object in question is valid. It then traverses the list using a while loop, checking the val member variable of each entry against the object passed in. If there is a match, the entry holding the object is returned; otherwise, null is returned.
The find method isn't public because you don't want outside users of the LinkedList class to know anything about the LinkedListEntry class. In other words, the LinkedListEntry class is a purely internal helper class, so the LinkedListEntry object returned from find wouldn't make any sense to a user of LinkedList. Even though find is private, there is a public method that can be used to see if an object is in the list. This method is called contains; its source code follows:
public boolean contains(Object obj) {
return (find(obj) != null);
}
As you can see, all the contains method does is call find and compare the return value to null. Since find only returns a non-null value if an object is found, this little trick works perfectly!
You may have noticed earlier that the find method made a call to the isEmpty method to see if the list was empty. The code for this method follows:
public boolean isEmpty() {
return (start == null);
}
Since the start reference in LinkedList only contains a null value if the list is empty, the isEmpty method simply checks to see if it is in fact set to null. This is a very simple and effective way to see if the list is empty.
That pretty much sums up the LinkedList class, except for how it supports the Enumeration interface. In deciding how to support the Enumeration interface, your best bet is to look to the Vector class. The Vector class supports the Enumeration interface through a method called elements. The elements method returns an object of type Enumeration that can be used to enumerate the elements in a vector. Let's use this same approach to add enumeration capabilities to the linked list. Following is the source code for the elements method in the LinkedList class:
public Enumeration elements() {
return new LinkedListEnumerator(this);
}
The elements method is probably a lot simpler than you expected. That's because the work of actually supporting the Enumeration interface is left to the LinkedListEnumerator class. Listing 23.4 contains the source code for the LinkedListEnumerator class.
Listing 23.4. The LinkedListEnumerator class.
1: class LinkedListEnumerator implements Enumeration {
2: protected LinkedListEntry pos;
3:
4: public LinkedListEnumerator(LinkedList list) {
5: pos = list.start;
6: }
7:
8: public boolean hasMoreElements() {
9: return (pos != null);
10: }
11:
12: public Object nextElement() {
13: // Make sure the current object is valid
14: if (pos == null)
15: throw new NoSuchElementException();
16:
17: // Increment the list and return the object
18: LinkedListEntry tmp = pos;
19: pos = pos.next;
20: return tmp.val;
21: }
22: }
| Analysis |
The first thing to notice in the LinkedListEnumerator class is that it implements the Enumeration interface, which is evident in the class definition. The LinkedListEnumerator class contains one member variable, pos, which keeps up with the current entry in the enumeration. The constructor simply sets the pos member to the start of the list. |
Other than saying so in the class definition, implementing the Enumeration interface involves supporting two methods: hasMoreElements and nextElement. The hasMoreElements method simply checks to see if the pos member is non-null, in which case there are more elements to enumerate. The nextElement method makes sure the current entry is valid and then returns the object stored in this entry. And that's really all there is to the LinkedListEnumerator class!
You now have a complete linked list class that is ready to be put to use in a practical Java program. I'll leave it up to you to figure out a neat application of it. Incidentally, all the source code for the linked list classes is located on the accompanying CD-ROM.
In today's lesson you have learned all about data structures and their relevance to Java programming. You began the lesson with a brief overview of data structures in general and why it is important to have a solid understanding of how to use them. You then moved on to learning about the standard data structures provided in the Java utility package. These standard data structures provide a range of options that cover many practical programming scenarios. However, for those cases where you need something a little different to hold data, you also learned about a type of data structure that isn't provided by the Java utility package: linked lists. You even implemented a linked list class that you can reuse in your own Java programs. This knowledge, combined with an understanding of the standard Java data structures, should serve as a solid foundation for your handling of data in practical programming scenarios.
If you thought the topic of data structures was a little dry, don't worry, because tomorrow's lesson gets much more exciting. Tomorrow you'll learn about advanced animation techniques and the handling of distributed media. You'll even use your newfound understanding of vectors to implement some really neat animation classes!
| If Java arrays are data structures, why aren't they implemented as classes? | |
| Actually, Java arrays are implemented as classes; they just aren't used as classes in the traditional sense of calling methods, and so on. Even though you won't find a class called Array in the Java API documentation, you can rest assured that under Java's hood there is an array class that is at least vaguely similar to the Vector class. | |
| Do all of the standard Java data structures implement the Enumeration interface? | |
| No, because the design of the Enumeration interface is based on a sequential data structure. For example, the Vector class is sequential and fits in perfectly with supporting the Enumeration interface. However, the BitSet class is very much nonsequential, so supporting the Enumeration interface wouldn't make any sense. | |
| I still don't totally see the importance of using a hash table. What gives? | |
| The concept of calculating a hash code for a complex piece of data is important because it allows you to lessen the overhead involved in searching for the data. The hash code allows you to home in on a particular point in a large set of data before you begin the arduous task of searching based on the data itself, which can greatly improve performance. | |
| How are linked lists different from vectors when it comes to the storage of individual elements? | |
| Vectors manage the memory requirements of all elements by allocating a certain amount of memory upon creation. When a vector is required to grow, it will allocate memory large enough to hold the existing data and the new data, and then copy everything to it. Even if a vector only holds references to objects, it must still manage the memory that holds the references. Linked lists don't manage any of the memory for the elements contained in the list, except for references to the start and end elements. |