{kind=link}
{kind=link}
{kind=link}
{kind=link}




Debugging CGI programs is sometimes a difficult task because they rely on different information from several different sources. There are several different ways you can test your CGI programs, both interactively over the Web and stand-alone using a debugger. Both of these approaches have different advantages and disadvantages.
In this chapter, you learn some common debugging techniques using CGI scripts and common debuggers as tools. You then learn some very common CGI errors and solutions.
There are two different approaches to testing and debugging CGI programs: testing the program over the Web server as a CGI program and testing it as a stand-alone program. Although you can open HTML and other files directly from a Web browser, you need to have a Web server running in order to test the results of a CGI program from a Web browser. If you already have a server from which you can test your CGI programs or if you set up a personal or experimental server for testing purposes, how can you debug your CGI programs?
There are several steps you can take. First, see if your program works. If it doesn't and if you receive a server error message, your program did not execute correctly. If you do not receive a server error message but your output is incorrect, then there is most likely a problem either with one of your algorithms or with the expected data.
There are several potential server error messages, the simplest being ones such as "file not found" (404). One of the most common server error messages when your CGI program is not working properly is "server error" (500), which means that your CGI program did not send an appropriate response to the server. The server always expects CGI headers (such as Content-Type) and usually some data; if the appropriate headers are not sent, then the server will return a 500 error.
| Tip |
Many servers redirect stderr to a file. The NCSA and Apache servers, for example, log error messages and stderr to the file logs/error_log by default. This is an invaluable resource for debugging CGI programs, because you can often determine the exact nature of the problem by looking at this log file. You can also log certain information to this file from within your CGI program by printing messages to stderr. |
For example, the following program returns the error 500 because the header is invalid:
#include <stdio.h>
int main()
{
printf("Cotnent-Tpye: txet/plain\r\n\r\n");
printf("Hello, World!\n");
}
If you check your server error logs, you are likely to find a message that says the headers are invalid.
If you know your program should return the appropriate headers (that is, you have the proper print statements in the proper places), then your program has failed somewhere before the headers are sent. For example, the following C code seems to be a valid CGI program:
#include <stdio.h>
#include <string.h>
int main()
{
char *name;
strcpy(name,NULL);
printf("Content-Type: text/plain\r\n\r\n");
printf("Hello, world!\n");
}
This program will compile fine and the headers it prints are valid, but when you try to run it from the Web server, the server returns an error 500. The reason is clear in this contrived example: strcpy() produces a segmentation fault when you try to copy a NULL value to a string. Because the program crashes before the header is sent, the server never receives valid information and so must return an error 500. Removing the strcpy() line from the program fixes the problem.
Another common browser message is Document contains no data. This message appears when a successful status code (200) and Content-Type are sent but no data is. If you know your program should print data following the header, you can infer that the problem lies between the header and body output. Consider the modified code:
#include <stdio.h>
#include <string.h>
int main()
{
char *name;
printf("Content-Type: text/plain\r\n\r\n");
strcpy(name,NULL);
printf("Hello, world!\n");
}
If you compile and run this program as a CGI, you will receive a Document contains no data message but no error. However, there is supposed to be data: "Hello, world!". Again, the error is clear: You cannot copy a NULL string to a variable. Because the program crashes after the header is printed, the body is never sent, and consequently, the browser thinks the document has no data. The error message helps you narrow down the location of the error and quickly identify the problem.
With a compiled language such as C, server error 500 generally means that the program has crashed before the header has been sent. Any syntax errors in the code are caught at compile-time. However, because scripting languages such as Perl are compiled languages, you don't know whether there are syntax errors until you actually run the program. If there are syntax errors, then the program will crash immediately and once again, you will see the familiar error 500. For example:
#!/usr/local/bin/perl
pirnt "Content-Type: text/plain\n\n";
print "Hello, World!\n";
There is a typo in the first print statement, so the program will not run, and consequently, the server receives no headers and sends an error 500. If your server logs stderr to an error file, you can find exactly where the syntax errors are by checking the log.
How can you debug your program if it runs correctly, does not crash, but returns the incorrect output? Normally, you could run your program through a debugger and watch the important variables to see exactly where your program is flawed. However, you cannot run the CGI program through a debugger if it is being run by the server. If you are testing your CGI program in this manner, you want to take advantage of the server and the browser to locate the error.
The poor man's method of debugging is to include a lot of print statements throughout the code. Because everything printed to the stdout is sent to the browser, you can look at the values of various variables from your Web browser. For example, the following code is supposed to output the numbers 1 factorial (1), 2 factorial (2), and 3 factorial (6):
#include <stdio.h>
int main()
{
int product = 1;
int i;
printf("Content-Type: text/html\r\n\r\n");
printf("<html><head>\n");
printf("<title>1, 2, and 6</title>\n");
printf("</head>\n\n");
printf("<body>\n");
for (i=1; i<=3; i++)
printf("<p>%d</p>\n",product*i);
printf("</body></html>\n");
}
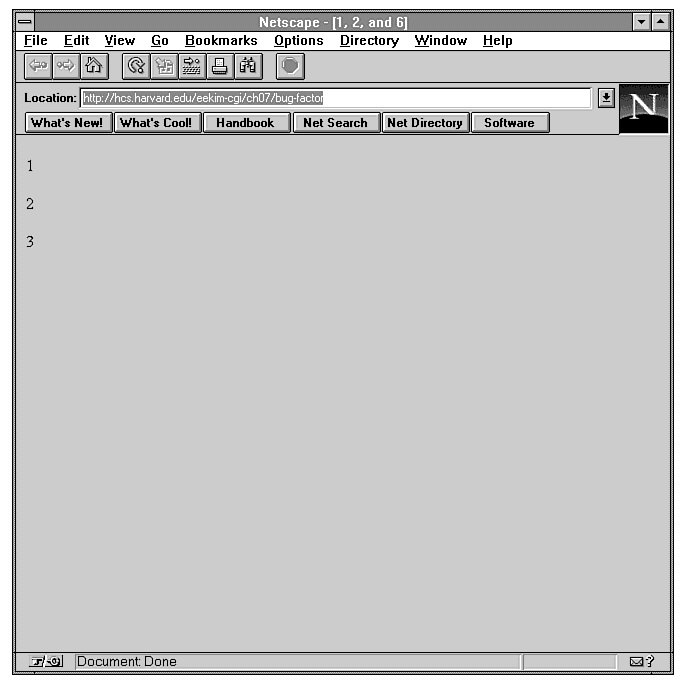
When you compile and run this program as a CGI, you get 1,
2, and 3
as shown in Figure 7.1. Suppose for the
moment that this is a vastly complex program and that you cannot
for the life of you figure out why this code is not working properly.
To give you more information and help you trace the problem, you
could print the values of product
and i at each stage of the
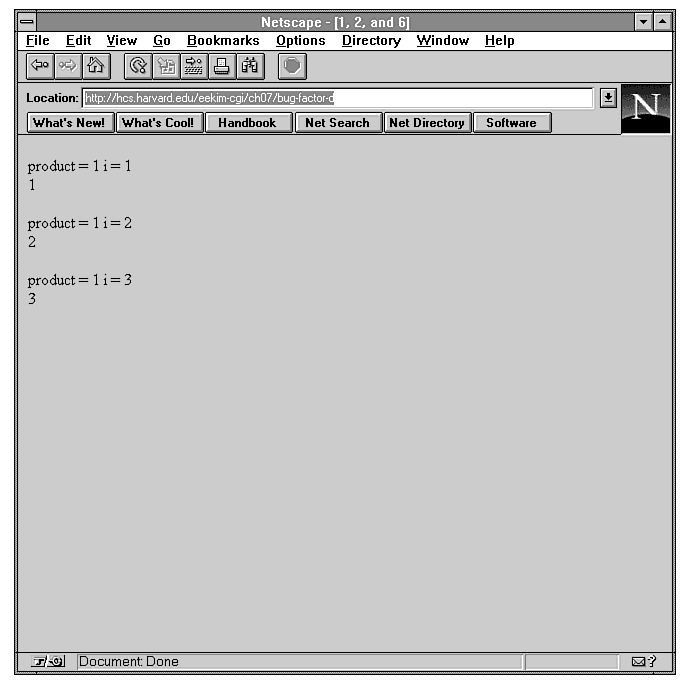
loop. Adding the appropriate lines of code produces the output
in Figure 7.2.
Figure 7.1 : Output of buggy factorial program.
Figure 7.2 : Output of buggy factorial program with debugging information.
#include <stdio.h>
int main()
{
int product = 1;
int i;
printf("Content-Type: text/html\r\n\r\n");
printf("<html><head>\n");
printf("<title>1, 2, and 6</title>\n");
printf("</head>\n\n");
printf("<body>\n");
for (i=1; i<=3; i++) {
/* print product and i */
printf("<p>product = %d i = %d<br>\n",product,i);
printf("%d</p>\n",product*i);
}
printf("</body></html>\n");
}
With this additional information, you can see that the value of
product is not updating each
time; it remains 1 at each
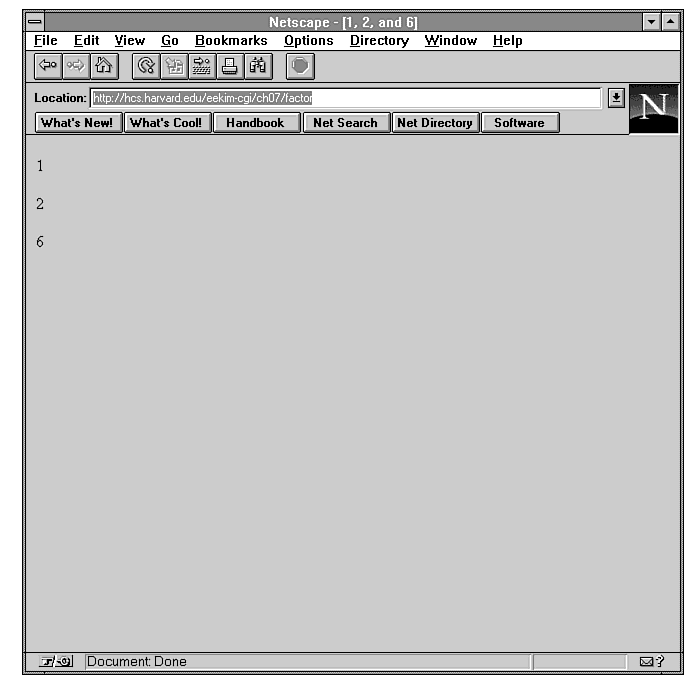
iteration. You can easily fix this bug and produce the correct
output in Figure 7.3.
Figure 7.3 : Output of correct factorial program.
#include <stdio.h>
int main()
{
int product = 1;
int i;
printf("Content-Type: text/html\r\n\r\n");
printf("<html><head>\n");
printf("<title>1, 2, and 6</title>\n");
printf("</head>\n\n");
printf("<body>\n");
for (i=1; i<=3; i++) {
product = product * i;
printf("<p>%d</p>\n",product);
}
printf("</body></html>\n");
}
Although using print statements is a simple and workable solution, it can be an inconvenient one, especially if you use a compiled language such as C. Each time you are debugging the program or making a slight change, you need to add or remove print statements and recompile. It would be easier if you could just run the program directly from within a debugger.
| Tip |
Cgiwrapd-a feature of Nathan Neulinger's cgiwrap-displays useful debugging information such as environment variables and the standard input. It enables you to redirect the stderr to stdout so that you see the error output from the Web browser rather than from the error log file. For more information about cgiwrap (and cgiwrapd), see URL: http://www.umr.edu/~cgiwrap/. |
You could run the program from within a debugger if you could correctly simulate a CGI program from the command line. This is possible but difficult because of the many variables you need to set. There are several environment variables that the CGI program might or might not rely on. For example, if you are testing a CGI program from the command line that accepts form input, you need to at least set the environment variable REQUEST_METHOD so that your program knows where to get the information. You must also properly URL encode the input, a non-trivial matter if you use a lot of non-alphanumeric characters.
There are two ways to address this problem. The first is a somewhat minimalist approach. Determine and set as many environment variables and other information as you need and then run the program. For example, if you are testing program.cgi and you know that you are using the GET method and that the input string is
name=Eugene&age=21
you could do the following (from the UNIX csh shell with the gdb debugger):
% setenv REQUEST_METHOD GET
% setenv QUERY_STRING 'name=Eugene&age=21'
% gdb program.cgi
Because all of the necessary information is set, the debugger runs the program without any problems almost as if the program were running from a Web server. You could create more advanced implementations of this solution. For example, instead of setting each variable manually, you could write a wrapper script that sets all of the appropriate environment variables and the input and runs the program through the debugger.
The second way to address the problem of simulating a CGI program from the command line is to actually run the program from the Web server and save the state information to a file. Then, when you are ready to debug, load the state file and use that information as the state information. Several CGI programming libraries have implemented features that save and load state information. Although this is a good solution for obtaining and testing CGI programs using the exact same information you would have under real Web conditions, it also requires modification of the code every time you save or load state information. This might not be a desirable task.
The main difficulty in testing forms is testing CGI programs that accept and parse input. A CGI program that just sends some output to the Web server, possibly based on the value of one environment variable such as HTTP_ACCEPT, is very simple to test from the command line because you usually do not need to worry about presetting the appropriate variables. I have already listed a few different ways of setting the input so that your CGI program runs properly from the command line. These are fairly good general solutions for debugging your programs.
One possible source of bugs is not knowing what type of input you are actually receiving. For example, suppose you wrote some code that parsed data from the following HTML form and returned the data in a different format:
<html><head>
<title>Form</title>
</head>
<body>
<h1>Form</h1>
<form action="/cgi-bin/poll.cgi" method=POST>
<p>Name: <input name="name"></p>
<p>Do you like (check all that apply):<br>
<input type=checkbox name="vegetable" value="carrot">Carrots?<br>
<input type=checkbox name="vegetable" value="celery">Celery?<br>
<input type=checkbox name="vegetable" value="lettuce">Lettuce?</p>
<input type=submit>
</form>
</body></html>
Remember, if the user does not check any checkboxes, then none of that information is submitted to the CGI program. If you-the CGI programmer-forgot this and assumed that you would have a blank value for "vegetable" rather than no entry labeled "vegetable" at all, your CGI program might produce some surprising output. Because you did not properly predict what kind of input you would receive, you inadvertently introduced a bug in your program.
Avoiding this situation means making sure the input looks as you expect it to look. You can use the program test.cgi in Listing 7.1 as a temporary CGI program for processing forms in order to see the exact format of the input. test.cgi simply lists the environment variables and values and information from the stdin if it exists.
Listing 7.1. test.cgi.
#!/usr/local/bin/perl
print "Content-type: text/plain\n\n";
print "CGI Environment:\n\n";
foreach $env_var (keys %ENV) {
print "$env_var = $ENV{$env_var}\n";
}
if ($ENV{'CONTENT_LENGTH'}) {
print "\nStandard Input:\n\n";
read(STDIN,$buffer,$ENV{'CONTENT_LENGTH'});
print $buffer;
}
| Tip |
If you want to quickly test a CGI program that is supposed to process a form, you know the exact format of the form input, and you don't want to waste time putting together the proper HTML form, you can telnet directly to the port of the Web server from a UNIX machine and enter the data directly. For example, if you wanted to post the following data: name=Eugene&age=21 to URL: http://hcs.harvard.edu/cgi-bin/test.cgi, you would use the following: % telnet hcs.harvard.edu 80 For more information on directly entering Web requests from UNIX, see Chapter 8, "Client/Server Issues." |
Although test.cgi displays the input parsed by the server, it does not return the exact request that the browser has sent. Sometimes, being able to see this low-level request can be useful. First, seeing how the browser communicates with the server is useful for learning purposes. Second, you can see the exact format of the request, look for variations in the input, and correct the appropriate bugs in your program.
I wrote a program called parrot, listed in Listing 7.2, written
in Perl for UNIX platforms. It is a Web server that simply takes
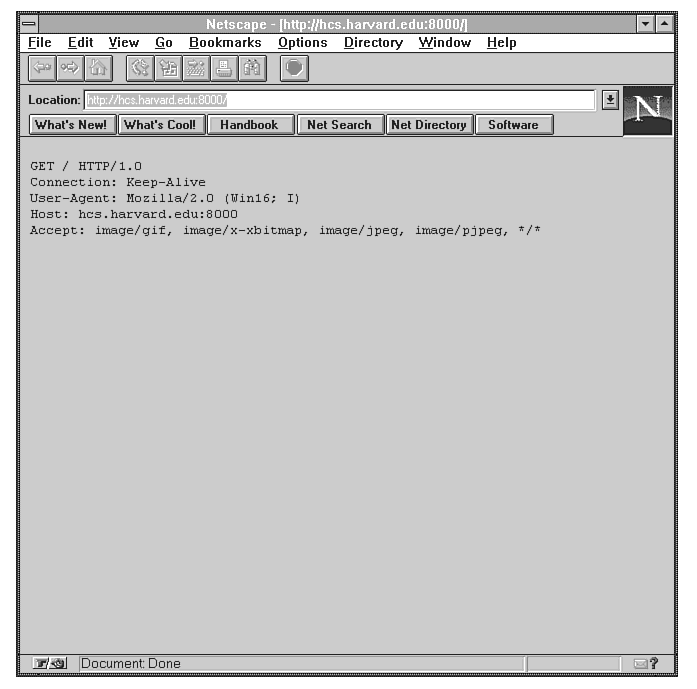
the browser's request and echoes it back to the browser. Figure 7.4
shows the sample output from a request to parrot. Parrot is essentially
a very small, very stupid Web server that can handle one connection
at a time and just repeats what the browser says to it. In order
to use the program, type parrot
at the command line. You can optionally specify the port number
for parrot by typing parrot n
where n is the port number. If
the machine already has an HTTP server running or if you're not
the site administrator, it might be a good idea to pick a high
port such as 8000 or 8080. To use it, you'd point your browser
at http://localhost:8000/
(of course, you'd substitute a different number for 8000
if you picked a different port number).
Figure 7.4 : The response from parrot.
Listing 7.2. The parrot program.
#!/usr/local/bin/perl
$debug = 0;
### trap signals
$SIG{'INT'} = 'buhbye';
$SIG{'TERM'} = 'buhbye';
$SIG{'KILL'} = 'buhbye';
### define server variables
($port) = @ARGV;
$port = 80 unless $port;
$AF_INET = 2;
$SOCK_STREAM = 1;
if (-e "/ufsboot") { # Solaris; other OS's may also have this value
$SOCK_STREAM = 2;
}
$SO_REUSEADDR = 0x04;
$SOL_SOCKET = 0xffff;
$sockaddr = 'S n a4 x8';
($name, $aliases, $proto) = getprotobyname('tcp');
select(fake_handle); $| = 1; select(stdout);
select(real_handle); $| = 1; select(stdout);
### listen for connection
$this = pack($sockaddr, $AF_INET, $port, "\0\0\0\0");
socket(fake_handle, $AF_INET, $SOCK_STREAM, $proto) || die "socket: $!";
setsockopt(fake_handle, $SOL_SOCKET, $SO_REUSEADDR, pack("l",1));
bind(fake_handle,$this) || die "bind: $!";
listen(fake_handle,5) || die "listen: $!";
while (1) {
@request = ();
($addr = accept (real_handle,fake_handle)) || die $!;
($af, $client_port, $inetaddr_e) = unpack($sockaddr, $addr);
@inetaddr = unpack('C4',$inetaddr_e);
$client_iname = gethostbyaddr($inetaddr_e,$AF_INET);
$client_iname = join(".", @inetaddr) unless $client_iname;
print "connection from $client_iname\n" unless (!$debug);
# read first line
$input = <real_handle>;
$input =~ s/[\r\n]//g;
push(@request,$input);
$POST = 0;
if ($input =~ /^POST/) {
$POST = 1;
}
# read header
$done = 0;
$CONTENT_LENGTH = 0;
while (($done == 0) && ($input = <real_handle>)) {
$input =~ s/[\r\n]//g;
if ($input =~ /^$/) {
$done = 1;
}
elsif ($input =~ /^[Cc]ontent-[Ll]ength:/) {
($CONTENT_LENGTH = $input) =~ s/^[Cc]ontent-[Ll]ength: //;
$CONTENT_LENGTH =~ s/[\r\n]//g;
}
push(@request,$input);
}
# read body if POST
if ($POST) {
read(real_handle,$buffer,$CONTENT_LENGTH);
push(@request,split("\n",$buffer));
}
&respond(@request);
close(real_handle);
}
sub respond {
local(@request) = @_;
# HTTP headers
print real_handle "HTTP/1.0 200 Transaction ok\r\n";
print real_handle "Server: Parrot\r\n";
print real_handle "Content-Type: text/plain\r\n\r\n";
# body
foreach (@request) {
print real_handle "$_\n";
}
}
sub buhbye {
close(fake_handle);
exit;
}
As an example of parrot's usefulness for CGI programming, I wanted to learn how to use Netscape's support for the HTML File Upload feature supported in its 2.0 browser (discussed in detail in Chapter 14, "Proprietary Extensions"). However, the RFC on File Upload was flexible, and I was interested specifically in how Netscape implemented it. Because Netscape did not document this feature well, I created a sample file upload form and had it connect to the parrot server. After submitting the file, parrot returned exactly what Netscape had submitted. After obtaining the format of the upload, I was able to write the scripts in Chapter 14 that correctly handled file upload.
There are several common errors people tend to make when programming CGI. A large percentage of the problems people generally have with CGI programming (other than a lack of conceptual understanding that this book hopefully addresses) falls under one of the categories described next. You should be familiar with all of these errors, their symptoms, and their solutions; they will save you a lot of time chasing after tiny mistakes.
The most common mistake is not to send a proper CGI header. You need to have either a Content-Type or a Location CGI header, and you can send only one or the other but not both. Each line should technically end with a carriage return and a line feed (CRLF), although a line feed alone usually works. The headers and the body of the CGI response must be separated by a blank line.
Assuming you use the proper header format, you also want to make sure you use the proper MIME type. If you are sending an image, make sure you send the proper MIME type for that image rather than text/html or some other wrong type. Finally, if you are using an nph script, the program must send an HTTP status header as well.
HTTP/1.0 200 Ok
Content-Type: text/plain
Hello, World!
One common problem especially pertinent to UNIX systems is making sure the server can run the scripts. You want to make sure first that the server recognizes the program as a CGI program, which means that it is either in a designated scripts directory (such as cgi-bin) or its extension is recognized as a CGI extension (that is, *.cgi). Second, the server must be able to run the script. Normally, this means that the program must be world-executable; if it is a script, it must be world-readable as well. Additionally, it means you must be familiar with how your server is configured.
Always use complete pathnames when writing a CGI program. CGI programs can take advantage of the PATH environment variable if it is trying to run a program, but it is more secure and reliable to use the full pathname rather than rely on the environment variable. Additionally, you want to make sure data files that you open and close are referred to as a complete pathname rather than a relative pathname.
There are situations in which you use paths relative to the document root rather than the complete path. For example, within HTML files, the path is always listed as relative to the document root. If your GIF file is located in
/usr/local/etc/httpd/htdocs/images/pic.gif
and your document root is
usr/local/etc/httpd/htdocs/
you reference this picture as
<img src="/images/pic.gif">
and not as
<img src="/usr/local/etc/httpd/htdocs/pic.gif">
This latter tag will give you a broken image message. In general, use relative paths from within HTML files and use full paths for data files and other such input and output.
Know what type of input to expect. Remember that certain form elements such as checkboxes have the unique quality that they only get passed to the server when they have been checked, and you need to make note of these quirks. Finally, if you're using an NCSA-style authentication for your Web server, you want to make sure you set the limitations on both GET and POST.
There are many language-specific problems that are often useful to know, especially if you are using several different languages. C users should remember to compile the proper libraries when linking and to make sure your include files are in the proper place. Watch out for pointer code that could cause segmentation faults within the program. Finally, use the full pathname.
You can approach testing and debugging CGI programs from two perspectives: actually testing the programs over the Web and testing them from the command line. Both have different advantages and disadvantages. Testing your programs over the Web enables you to see whether your CGI program works properly under expected conditions given real input. On the other hand, it can be a difficult and sometimes inefficient process. Testing from the command line gives you greater flexibility to debug your programs thoroughly at the cost of testing your scripts using real input from a true Web environment. You can also learn a lot by determining the exact format and content of the input from the Web.
Most CGI errors can be attributed to a few common errors. Before you spend a lot of time doing exhaustive testing and debugging, check to make sure you did not make one of the following mistakes: