{kind=link}
{kind=link}
{kind=link}
{kind=link}




A few years ago, I was setting up World Wide Web pages for Harvard college, and I wanted to include a page where people could submit their comments about the pages. At the time, the Web was young and the documentation scarce. I, like many others, depended on the terse documentation and other people's code to learn how to program CGI. Although this method of learning required some searching, plenty of experimentation, and a lot of questions, it was very effective. This chapter is a mirror of my early struggles with CGI (with several refinements, of course!).
Although gaining a complete understanding and mastery of the Common Gateway Interface takes some time, the protocol itself is fairly simple. Anyone with some basic programming skills and familiarity with the Web is capable of quickly learning how to program fairly sophisticated CGI applications in the same way I and others learned a few years ago.
The objective of this chapter is to present the basics of CGI in a comprehensive and concise manner. Every concept discussed here is covered in greater detail in later chapters. However, upon finishing this chapter, you should be immediately capable of programming CGI applications. Once you reach that point, you have the option of learning the remaining subtle nuances of CGI either by reading the rest of this book or by simply experimenting on your own.
You can reduce CGI programming to two tasks: getting information
from the Web browser and sending information back to the browser.
This is fairly intuitive once you realize how CGI applications
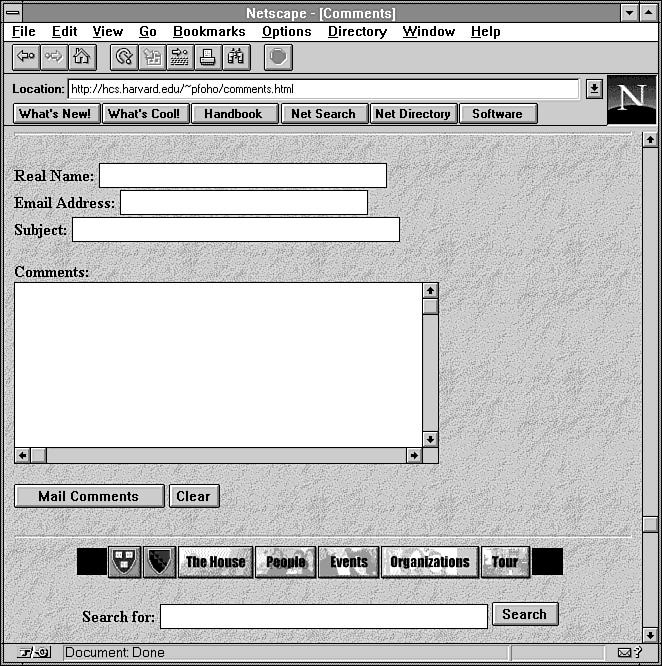
are usually used. Often, the user is presented with a form to
complete, such as the one in Figure 2.1.
Once the user fills out this form and submits it, the information
is sent to a CGI program. The CGI program must then convert that
information into something it understands, process it appropriately,
and then send something back to the browser, whether it is a simple
acknowledgment or the results of a complex database search.
In other words, programming CGI requires understanding how to get input from and how to send output back to the Web browser. What goes on between the input and output stages of a CGI program depends on what the developer wants to accomplish. You'll find that the main complexity of CGI programming lies in that in-between stage; after you figure out how to deal with the input and output, you have essentially accomplished what you need to know to become a CGI developer.
In this chapter, you learn the basic concepts behind CGI input and output as well as other rudimentary skills you need to write and use CGI, including how to create HTML forms and how to call your CGI programs. The chapter covers the following topics:
Because of the nature of this chapter, I only casually discuss certain topics. Don't worry; all of these topics are explored in much more detail in the other chapters.
You begin with the traditional introductory programming problem. You want to write a program that will display Hello, world! on your Web browser. Before you can write this program, you must understand what information the Web browser expects to receive from CGI programs. You also need to know how to run this program so you can see it in action.
CGI is language-independent, so you can implement this program in any language you want. A few different ones are used here to demonstrate this language independence. In Perl, the "Hello, world!" program looks like Listing 2.1.
Listing 2.1. Hello, world! in Perl.
#!/usr/local/bin/perl
# hello.cgi - My first CGI program
print "Content-Type: text/html\n\n";
print "<html> <head>\n";
print "<title>Hello, world!</title>";
print "</head>\n";
print "<body>\n";
print "<h1>Hello, world!</h1>\n";
print "</body> </html>\n";
Save this program as hello.cgi, and install it in the appropriate place. (If you are not sure where that is, relax; you'll learn this in "Installing and Running Your CGI Program," later in this chapter.) For most people, the proper directory is called cgi-bin. Now, call the program from your Web browser. For most people, this means opening the following Uniform Resource Locator (URL):
http://hostname/directoryname/hello.cgi
hostname is the name
of your Web server, and directoryname
is the directory in which you put hello.cgi (probably cgi-bin).
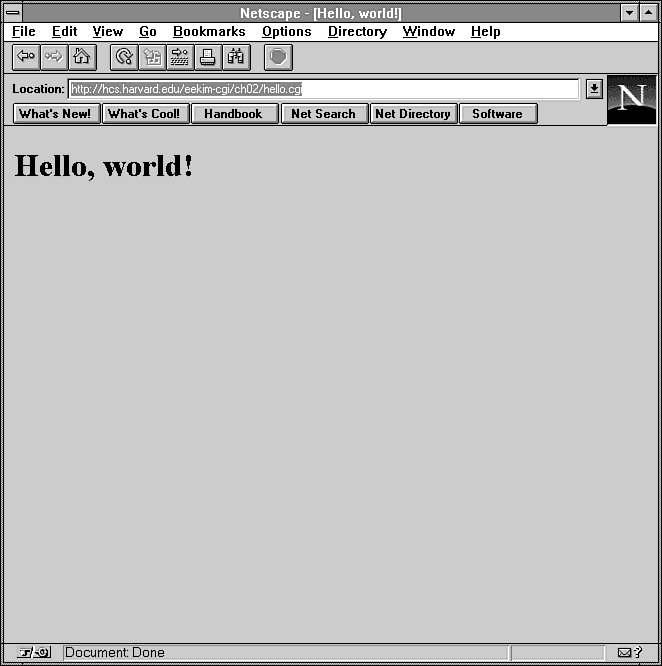
Your Web browser should look like Figure 2.2.
Figure 2.2 : Your first CGI program, if all goes well, will display Hello, world!.
There are a couple of things worth mentioning about hello.cgi. First, you're using simple print commands. CGI programs do not require any special file handles or descriptors for output. In order to send output to the browser, simply print to the stdout.
Second, notice that the content of the first print statement (Content-Type: text/html) does not show up on your Web browser. You can send whatever information you want back to the browser (an HTML page or graphics or sound), but first, you need to tell the browser what type of data you're sending it. This line tells the browser what sort of information to expect-in this case, an HTML page.
Third, the program is called hello.cgi. It's not always necessary to use the extension .cgi with your CGI program name. Although the source code for many languages also use extensions, the .cgi extension is not being used to denote language type, but is a way for the server to identify the file as an executable rather than a graphic file or HTML or text file. Servers are often configured to only try to run those files which have this extension, displaying the contents of all others. Although it might not be necessary to use the .cgi extension, it's still good practice.
In summary, hello.cgi consists of two main parts:
To demonstrate the language-independence of CGI programs, Listing 2.2 contains the equivalent hello.cgi program written in C.
Listing 2.2. Hello, world! in C.
/* hello.cgi.c - Hello, world CGI */
#include <stdio.h>
int main() {
printf("Content-Type: text/html\r\n\r\n");
printf("<html> <head>\n");
printf("<title>Hello, World!</title>\n");
printf("</head>\n");
printf("<body>\n");
printf("<h1>Hello, World!</h1>\n");
printf("</body> </html>\n");
}
| Note |
Note that the Perl version of hello.cgi uses print "Content-Type: text/html\n\n"; whereas the C version uses printf("Content-Type: text/html\r\n\r\n"); Why does the Perl print statement end with two newlines (\n) while the C printf ends with two carriage returns and newlines (\r\n)? Officially, the headers (all the output before the blank line) are supposed to be separated by a carriage return and a newline. Unfortunately, on DOS and Windows machines, Perl will translate the \r as another newline rather than as a carriage return. Although omitting the \rs in Perl is technically wrong, it will work on almost all protocols and is also portable across platforms. Hence, in all Perl examples in this book, I use newlines separating the headers rather than carriage returns and newlines. A proper solution to this problem is presented in Chapter 4, "Output." |
Neither the Web server nor the browser care which language you use to write your program. Although every language has advantages and disadvantages as a CGI programming language, it is best to use the language with which you are most comfortable. (A more detailed discussion on choosing your programming language is in Chapter 1, "Common Gateway Interface (CGI).")
You can now take a closer look at how to send information to the
Web browser. As you saw in the "Hello, world!" example,
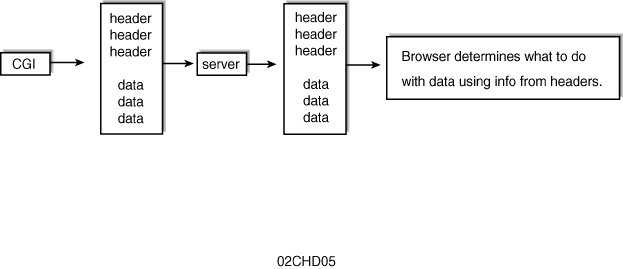
Web browsers expect two sets of data (see Figure 2.3):
a header that contains information such as the type of information
to display (such as the Content-Type:
line) and the actual information (what shows up on the Web browser).
These two blocks of information are separated by a blank line.
Figure 2.3 : Browsers expect a header and the data from CGI programs, separated by a blank line.
The header is called an HTTP header. It provides important information about the information the browser is about to receive. There are several different types of HTTP headers, and the most common is the one you used previously: the Content-Type: header. You can use different combinations of HTTP headers by separating them with a carriage return and a newline (\r\n). The blank line separating the header from the data also consists of a carriage return and a newline (why you need both is described briefly in the preceding note and in detail in Chapter 4). You learn the other HTTP headers in Chapter 4; for now, you focus on the Content-Type: header.
The Content-Type: header describes the type of data the CGI is returning. The proper format for this header is
Content-Type: subtype/type
where subtype/type is a valid multipurpose Internet mail extensions (MIME) type. The most common MIME type is the HTML type: text/html. Table 2.1 lists a few of the more common MIME types you will see; a more complete list and discussion of MIME types is in Chapter 4.
| Note |
MIME was originally invented as a way to describe the content of mail message bodies. It has become a fairly common way of expressing content-type information. You can get more information on MIME from RFC1521. Internet RFCs are "Requests for Comments," which are summaries of decisions made by groups on the Internet attempting to set standards. You can see the results of RFC1521 at the following URL: http://andrew2.andrew.cmu.edu/rfc/rfc1521.html |
| MIME Type | |
| text/html | HyperText Markup Language (HTML) |
| text/plain | Plain text files |
| image/gif | GIF graphics files |
| image/jpeg | JPEG compressed graphics files |
| audio/basic | Sun *.au audio files |
| audio/x-wav | Windows *.wav files |
Following the header and the blank line, you simply print the data as you want it to appear. If you are sending HTML, then print the HTML tags and data to stdout following the header. You can send graphics, sound, and other binary files as well simply by printing the contents of the file to stdout. There are some examples of this in Chapter 4.
This section digresses briefly from CGI programming and talks about configuring your Web server to use CGI and installing and running your programs. You learn a few different servers for different platforms here in some detail, but you will want to consult your server documentation for the best instructions.
All servers require space for the server files and space for the HTML documents. In this book, the server area is called ServerRoot and the document area is called DocumentRoot. On UNIX machines, the ServerRoot is typically in /usr/local/etc/httpd/ and the DocumentRoot is typically in /usr/local/etc/httpd/htdocs/. This is by no means necessarily true on your system, however, so make sure you replace all references to ServerRoot and DocumentRoot with your own ServerRoot and DocumentRoot.
When you access files using your Web browser, you specify the file in the URL relative to the DocumentRoot. For example, if you have the file /usr/local/etc/httpd/htdocs/index.html on your machine mymachine.org, you would access that file with the following URL:
http://mymachine.org/index.html
Most Web servers are preconfigured to use CGI programs. There are generally two things that tell a server whether a file is a CGI application or not:
The designated directory method is somewhat of a historical relic (the earliest servers used this as their sole method for determining which files were CGI programs), but it has several advantages.
Indicating CGI by filename extension can be useful because of
its flexibility. You are not restricted to one single directory
for CGI programs. Most servers can be configured to recognize
CGI by filename extension, although not all of them are configured
this way by default.
| Caution |
Remember that there are important security considerations you need to remember when you are configuring your server for CGI. Some hints will be discussed here, but make sure to read Chapter 9, "CGI Security," for more details on CGI security. |
No matter how your UNIX server is configured, you need to take a few steps to make sure your CGI applications run properly. Your Web server will normally be running as a non-existent user (that is, the UNIX user nobody, an account which has no file access rights, and can't be logged into). Consequently, compiled CGI applications should be world-executable and CGI scripts (written in Perl, Bourne shell, or another scripting language) should be both world-executable and world-readable.
| Tip |
To make your files world-readable and world-executable, use the following UNIX command, where filename is the name of the file: chmod 755 filename |
If you are using a scripting language such as Perl or Tcl, make sure you specify the full path of your interpreter in the first line of your script. For example, a Perl script using perl in the /usr/local/bin directory should begin with the following line:
#!/usr/local/bin/perl
| Caution |
Never put your interpreter (the perl or Tcl wish binary) in your /cgi-bin directory. This creates a security hazard on your system. More details are available in Chapter 9. |
The NCSA and Apache Web servers have similar configuration files because the Apache server was originally based on the NCSA code. By default, they are configured to think any file in the cgi-bin directory (located by default in ServerRoot) is a CGI program. To change the location of your cgi-bin directory, you can edit the conf/srm.conf configuration file. The format for configuring this directory is
ScriptAlias fakedirectoryname realdirectoryname
where fakedirectoryname is the fake directory name (/cgi-bin) and realdirectoryname is the complete path where the CGI programs are actually stored. You can configure more than one ScriptAlias by adding more ScriptAlias lines.
The default configuration is sufficient for most people's needs. You should edit the line in the srm.conf file anyway to specify the correct realdirectoryname. If, for example, your CGI programs are located in /usr/local/etc/httpd/cgi-bin, the ScriptAlias line in your srm.conf file should resemble the following:
ScriptAlias /cgi-bin/ /usr/local/etc/httpd/cgi-bin/
To access or reference your CGI programs located in this directory, you would use the following URL:
http://hostname/cgi-bin/programname
where hostname is the host name of your Web server and programname is the name of your CGI. For example, suppose you copied the hello.cgi program into your cgi-bin directory (for example, /usr/local/etc/httpd/cgi-bin) on your Web server called www.company.com. To access your CGI, use the following URL:
http://www.company.com/cgi-bin/hello.cgi
If you want to configure either the NCSA or Apache server to recognize any file with the extension .cgi as CGI, you need to edit two configuration files. First, in the srm.conf file, uncomment the following line:
AddType application/x-httpd-cgi .cgi
This will associate the CGI MIME type with the extension .cgi. Now, you need to modify your access.conf file to enable CGIs to be executed in any directory. To do this, add the ExecCGI option to the Option line. It will probably look something like the following line:
Option Indexes FollowSymLinks ExecCGI
Now, any file with the extension .cgi is considered CGI; access it as you would access any file on your server.
The CERN server is configured in a similar fashion as the NCSA and Apache servers. Instead of ScriptAlias, the CERN server uses the command Exec. For example, in the httpd.conf file, you will see the following line:
Exec /cgi-bin/* /usr/local/etc/httpd/cgi-bin/*
Other UNIX servers are configurable in a similar fashion; check your server's documentation for more details.
Most of the servers available for Windows 3.1, Windows 95, and Windows NT are configured using the file-extension method for CGI recognition. Generally, reconfiguring your Windows-based server simply requires running the server's configuration program and making the appropriate changes.
Configuring your server to correctly run scripts (such as Perl) is sometimes tricky. With DOS or Windows, you cannot specify the interpreter on the first line of the script like you can with UNIX. Some servers are preconfigured to associate certain filename extensions with an interpreter. For example, many Windows web servers will assume that files ending in .pl are Perl scripts.
If your server does not do this type of file association, you can define a wrapper batch file that calls both the interpreter and the script. As with the UNIX server, don't install the interpreter in either the cgi-bin directory or in any Web-accessible directories.
The two most established server options for the Macintosh are StarNine's WebStar and its MacHTTP predecessor. Both recognize CGIs by looking at the filename's extension.
MacHTTP understands two different extensions: .cgi and .acgi, which stands for asynchronous CGI. Regular CGI programs installed on the Macintosh (with the .cgi extension) will keep the Web server busy until the CGI is finished running, forcing the server to put all other requests on hold. Asynchronous CGI, on the other hand, will enable the server to accept requests even while running.
The Macintosh CGI developer using either of these Web servers should simply use the .acgi extension rather than the .cgi extension whenever possible. This should work with most CGI programs; if it doesn't seem to work, rename the program to .cgi.
After you've installed your CGI, there are several ways to run it. If your CGI is an output-only program, such as the Hello, world! program, then you can run it by simply accessing its URL.
Most programs are run as the back end to an HTML form. Before you learn how to get information from these forms, first read a brief introduction on how to create these forms.
The two most important tags in an HTML form are the <form> and <input> tags. You can create most HTML forms using only these two tags. In this chapter, you learn these tags and a small subset of the possible <input> types or attributes. A complete guide and reference to HTML forms is in Chapter 3, "HTML and Forms."
The <form> tag is used to define what part of an HTML file is to be used for user input. It is how most HTML pages call a CGI program. The tag's attributes specify the program's name and location either locally or as a full URL, the type of encoding being used, and what method is being used to transfer the data to be used by the program.
The following line shows the specifications for the <form> tag:
<FORM ACTION="url" METHOD=[POST|GET] ENCTYPE="...">
The ENCTYPE attribute is fairly unimportant and is usually not included with the <form> tag. For more information on the ENCTYPE tag, see Chapter 3. For one use of ENCTYPE, see Chapter 14, "Proprietary Extensions."
The ACTION attribute references the URL of the CGI program. After the user fills out the form and submits the information, all of the information is encoded and passed to the CGI program. It is up to the CGI program to decode the information and process it; you learn this in "Accepting Input From the Browser," later in this chapter.
Finally, the METHOD attribute describes how the CGI program should receive the input. The two methods-GET and POST-differ in how they pass the information to the CGI program. Both are discussed in "Accepting Input From the Browser."
For the browser to be able to allow user input, all form tags and information must be surrounded by the <form> tag. Don't forget the closing </form> tag to designate the end of the form. You may not have a form within a form, although you can set up a form that enables you to submit parts of the information to different places; this is covered extensively in Chapter 3.
You can create text input bars, radio buttons, checkboxes, and other means of accepting input by using the <input> tag. This section only discusses text input fields. To implement this field, use the <input> tag with the following attributes:
<INPUT TYPE=text NAME=" . . . " VALUE=" . . . " SIZE= MAXLENGTH= >
NAME is the symbolic name of the variable that contains the value entered by the user. If you include the VALUE attribute, this text will be placed as the default text in the text input field. The SIZE attribute enables you to specify a horizontal length for the input field as it will appear on the browser. Finally, MAXLENGTH specifies the maximum number of characters the user can input into the field. Note that the VALUE, SIZE, and MAXLENGTH attributes are all optional.
If you have only one text field within your form, the user can submit the form by simply typing in the information and pressing Enter. Otherwise, you must have some way for the user to submit the information. The user submits information by using a submit button with the following tag:
<input type=submit>
This tag creates within your form a button labeled Submit. When the user has finished filling out the form, he or she can submit its content to the URL specified by the form's ACTION attribute by clicking the Submit button.
In previous examples, you saw how to write a CGI program that sends information from the server to the browser. In reality, a CGI program that only outputs data does not have many applications (but it does have some; see Chapter 4 for examples). More important is the capability of CGI to receive information from the browser, the feature that gives the Web its interactive nature.
A CGI program receives two types of information from the browser.
Knowing what environment variables are available for the CGI program
can be useful, both as a learning aid and as a debugging tool.
Table 2.2 lists some of the available CGI environment variables.
You can also write a CGI program that prints the environment variables
and their values to the Web browser.
| Environment Variable | |
| REMOTE_ADDR | The IP address of the client's machine. |
| REMOTE_HOST | The host name of the client's machine. |
| HTTP_ACCEPT | Lists the MIME types of the data the browser knows how to interpret. |
| HTTP_USER_AGENT | Browser information (such as name, version number, operating system, and so on). |
| REQUEST_METHOD | GET or POST. |
| CONTENT_LENGTH | The size of input if it is sent via POST. If there is no input or if the GET method is used, this is undefined. |
| QUERY_STRING | Contains the input information when it's passed using the GET method. |
| PATH_INFO | Enables the user to specify a path from the CGI command line (for example, http://hostname/cgi-bin/programname/path). |
| PATH_TRANSLATED | Translates the relative path in PATH_INFO to the actual path on the system. |
In order to write a CGI application that displays the environment variables, you have to know how to do two things:
You already know how to do the latter. In Perl, the environment variables are stored in the associative array %ENV, which is keyed by the environment variable name. Listing 2.3 contains env.cgi, a Perl program that accomplishes our objective.
Listing 2.3. A Perl program, env.cgi, which outputs all CGI environment variables.
#!/usr/local/bin/perl
print "Content-type: text/html\n\n";
print "<html> <head>\n";
print "<title>CGI Environment</title>\n";
print "</head>\n";
print "<body>\n";
print "<h1>CGI Environment</h1>\n";
foreach $env_var (keys %ENV) {
print "<B>$env_var</B> = $ENV{$env_var}<BR>\n";
}
print "</body> </html>\n";
A similar program can be written in C; the complete code is in Listing 2.4.
Listing 2.4. env.cgi.c in C.
/* env.cgi.c */
#include <stdio.h>
extern char **environ;
int main()
{
char **p = environ;
printf("Content-Type: text/html\r\n\r\n");
printf("<html> <head>\n");
printf("<title>CGI Environment</title>\n");
printf("</head>\n");
printf("<body>\n");
printf("<h1>CGI Environment</h1>\n");
while(*p != NULL)
printf("%s<br>\n",*p++);
printf("</body> </html>\n");
}
What is the difference between the GET and POST methods? GET passes the encoded input string via the environment variable QUERY_STRING, whereas POST passes it through stdin. POST is the preferable method, especially for forms with a lot of data, because there is no limit to how much information you can send. On the other hand, you are limited with the GET method by the amount of environment space you have. GET has some utility, however; this is discussed in detail in Chapter 5, "Input."
In order to determine which method is used, the CGI program checks the environment variable REQUEST_METHOD, which will either be set to GET or POST. If it is set to POST, the length of the encoded information is stored in the environment variable CONTENT_LENGTH.
When the user submits a form, the browser first encodes the information before sending it to the server and subsequently to the CGI application. When you use the <input> tag, every field is given a symbolic name, which can be thought of as the variable. The value entered by the user can be thought of as the value of the variable.
In order to specify this, the browser uses something called the URL encoding specification, which can be summed up as follows:
Your final encoded string will look something like the following:
name1=value1&name2=value2&name3=value3 ...
| Note |
The specifications for URL encoding are in RFC1738. |
For example, suppose you had a form that asked for name and age. The HTML used to produce this form is in Listing 2.5.
Listing 2.5. HTML to produce the name and age form.
<html> <head>
<title>Name and Age</title>
</head>
<body>
<form action="/cgi-bin/nameage.cgi" method=POST>
Enter your name: <input type=text name="name"><p>
Enter your age: <input type=text name="age"><p>
<input type=submit>
</form>
</body> </html>
Suppose the user enters Joe Schmoe in the name field, and 20 in the age field. The input will be encoded into the input string.
name=Joe+Schmoe&age=20
In order for this information to be useful, you need to be able to parse the information into something your CGI programs can use. You learn strategies for parsing the input in Chapter 5. For all practical purposes, you will never have to think about how to parse the input because several people have already written freely available libraries that do the parsing for you. Two such libraries are introduced in this chapter in the following sections: cgi-lib.pl for Perl (written by Steve Brenner) and cgihtml for C (written by me).
The general idea for most of the libraries written in different languages is to parse the encoded string and place the name and value pairs into a data structure. There is a clear advantage to using a language that has built-in data structures such as Perl; however, most of the libraries for lower-level languages such as C and C++ include data-structure implementations and routines.
Don't worry about understanding every detail of the libraries; what is really important is to learn to use them as tools to make your job as a CGI programmer easier.
cgi-lib.pl takes advantage of Perl's associative arrays. The function &ReadParse parses the input string and keys each name/value pair by the name. For example, the appropriate lines of Perl necessary to decode the name/age input string just presented would be
&ReadParse(*input);
Now, if you want to see the value entered for "name," you can access the associative array variable $input{"name"}. Similarly, to access the value for "age," you look at the variable $input{"age"}.
C does not have any built-in data structures, so cgihtml implements its own linked list for use with its CGI parsing routines. It defines the structure entrytype as follows:
typedef struct {
char *name;
char *value;
} entrytype;
In order to parse the name/age input string in C using cgihtml, you would use the following:
llist input; /* declare linked list called input */
read_cgi_input(&input); /* parse input and place in linked list */
To access the information for the age, you could either parse through the list manually or use the provided cgi_val() function.
#include <stdlib.h>
#include <string.h>
char *age = malloc(sizeof(char) * strlen(cgi_val(input,"age")) + 1);
strcpy(age,cgi_val(input,"age"));
The value for "age" is now stored in the string age.
| Note |
Instead of using a simple array (like char age[5];), I go through the trouble of dynamically allocating memory space for the string age. Although this makes the programming more complex, it is important for security reasons. See Chapter 9 for more details. |
Chapter 5 goes into more depth for these and other libraries. For now, you're ready to combine your knowledge of input and output to write a full-fledged, yet simple, CGI program.
You are going to write a CGI program called nameage.cgi that processes the name/age form. The data processing (what I like to call the "in-between stuff") is minimal. nameage.cgi simply decodes the input and displays the user's name and age. Although there is not much utility in such a tool, this demonstrates the most crucial aspect of CGI programming: input and output.
You use the same form as described previously, calling the fields name and age. For now, don't worry about robustness or efficiency; solve the problem at hand using the simplest possible solution. The Perl and C solutions are shown in Listings 2.6 and 2.7, respectively.
Listing 2.6. nameage.cgi in Perl.
#!/usr/local/bin/perl
# nameage.cgi
require 'cgi-lib.pl'
&ReadParse(*input);
print "Content-Type: text/html\r\n\r\n";
print "<html> <head>\n";
print "<title>Name and Age</title>\n";
print "</head>\n";
print "<body>\n";
print "Hello, " . $input{'name'} . ". You are\n";
print $input{'age'} . " years old.<p>\n";
print "</body> </html>\n";
Listing 2.7. nameage.cgi in C.
/* nameage.cgi.c */
#include <stdio.h>
#include "cgi-lib.h"
int main()
{
llist input;
read_cgi_input(&input);
printf("Content-Type: text/html\r\n\r\n");
printf("<html> <head>\n");
printf("<title>Name and Age</title>\n");
printf("</head>\n");
printf("<body>\n");
printf("Hello, %s. You are\n",cgi_val(input,"name"));
printf("%s years old.<p>\n",cgi_val(input,"age"));
printf("</body> </html>\n");
}
Note these two programs are almost exactly equivalent. They both contain parsing routines that occupy only one line and handle all the input (thanks to the respective library routines). The output is essentially a glorified version of your basic Hello, world! program.
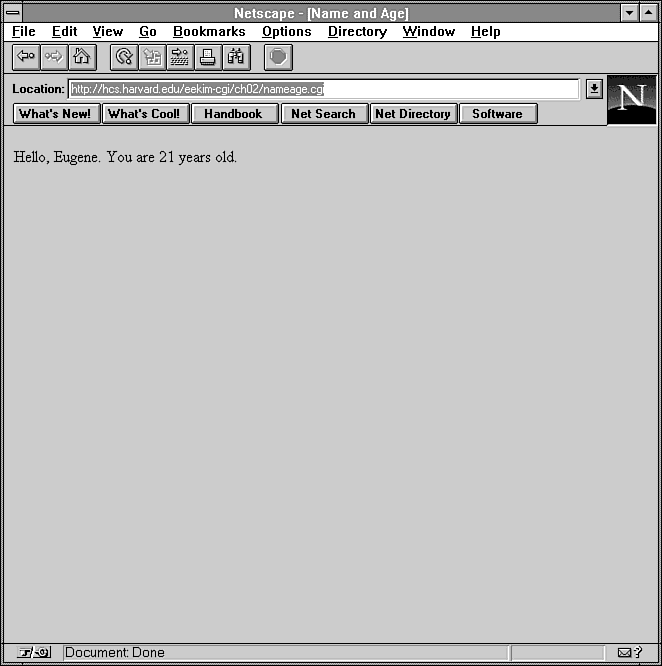
Try running the program by filling out the form and pressing the
Submit button. Assuming you enter Eugene
for name, and 21
for age, your result should
resemble Figure 2.4.
Figure 2.4 : The result of the CGI nameage cgi program.
You now know all of the basic concepts necessary to program CGI. When you understand how CGI receives information and how it sends it back to the browser, the actual quality of your final product depends on your general programming abilities. Namely, when you program CGI (or anything for that matter), keep the following qualities in mind:
The first two qualities are fairly common: try to make the code as readable and as efficient as possible. Generality applies more to CGI programs than to other applications. You will find as you start developing your own CGI programs that there are a few basic applications that you and everyone else want to do. For example, one of the most common and obvious tasks of a CGI program is to process a form and e-mail the results to a certain recipient. You might have several different forms you want processed, each with a different recipient. Instead of writing a CGI program for each different form, you can save time by writing a more general CGI program that works for all of the forms.
By touching upon all of the basic features of CGI, I have provided you with enough information to start programming CGI. However, in order to become an effective CGI developer, you need to have a deeper understanding of how CGI communicates with the server and the browser. The rest of this book focuses on the details that are skimmed over in this chapter and discusses strategies for application development and the advantages and limitations of the protocol.
This chapter rapidly introduced the basics behind CGI programming. You create output by formatting your data correctly and printing to stdout. Receiving CGI input is slightly more complex because it must be parsed before it can be used. Fortunately, several libraries already exist that do the parsing for you.
You should feel comfortable programming CGI applications at this point. The rest of this book is devoted to providing more details about the specification and offering tips and strategies for programming advanced, sophisticated applications.