{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




In this chapter, you learn how to use CGI programs to interface the Web with databases. Several different types of databases exist, ranging in complexity. I hope to clarify the concept of a database and teach some general strategies for interfacing with these databases.
I am less concerned with specific database implementations and more concerned with basic database concepts. With this in mind, this chapter begins with a short introduction to databases and a brief discussion of the various implementations. You then see a few examples of a CGI program interfacing a database with the Web. Included is a medium-sized, full-featured application written in Perl. Finally, you learn how to use existing database implementations to provide keyword searches for your Web site.
Database is a fancy word describing an organizational model for storing data. Almost every application requires the storage and manipulation of some form of data. A database provides a mechanism for organizing this data so that it is easily accessed and stored.
You can envision several applications that use a database. A rolodex, financial accounting records, and your file cabinet are all examples of databases. Any application in which you need to access and possibly add, delete, or change data uses some form of a database.
You can implement a database in several ways; you learn several later in this chapter. Considering the large number of applications that require some form of database, having a general model of designing and programming a database is extremely useful. Even more useful is a standard, general way of representing and accessing this data.
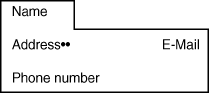
If you program an address book that stores names and addresses,
for example, you can implement a database that stores addresses,
phone numbers, e-mail addresses, and birthdays for every name,
as shown in Figure 12.1. Now, consider
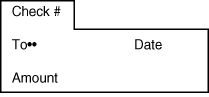
a checking account program that records every check you write.
Each check number is probably associated with a dollar amount,
date, and recipient, as shown in Figure 12.2.
Figure 12.1 : A rolodex database.
Both Figures 12.1 and 12.2 are similar in structure. The name in the rolodex application and the check number in the checking account application are the descriptive attributes (in database lingo, the keys) of their respective databases. Keys for both databases represent a larger structure that contains several attributes or fields such as phone number or dollar amount.
Several types of databases share these same characteristics, and consequently, two major database paradigms have arisen: the relational database and the object-oriented database. These paradigms provide an abstract model for implementing and accessing these databases.
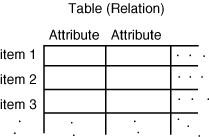
The first and most common database paradigm is the relational
database management system (RDBMS). The RDBMS uses a two-dimensional
table or relation as a model for storing data, as shown
in Figure 12.3. The table represents
a database entity such as your rolodex or your checking account.
Each row of the table represents an item within your database,
and each column represents a certain attribute. You can write
programs that will access and retrieve items from any of your
databases, independent of the actual data stored. If you have
two tables with a common item (row), then you can relate one database
with the other (hence the name "relational").
Figure 12.3 : The RDBMS paradigm.
You can implement a relational database in several ways. You develop some primitive relational databases later in the section on the OODBMS paradigm. Because the structures of relational databases are so similar, having a standard means of describing and querying a database is extremely useful. The standard for RDBMS is called the Structured Query Language (SQL). Many commercial database systems from companies such as Oracle and Sybase are relational and use SQL. Some free SQL implementations are also available, such as mSQL, about which you will learn later.
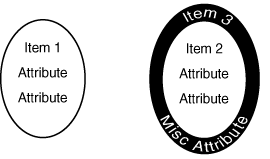
The second major database paradigm is the Object-Oriented Database
Management System (OODBMS). This paradigm, depicted in Figure 12.4,
uses objects to represent data. Objects are a more sophisticated
way of defining types and relating one object with another. Usually,
objects are defined to be as close to their real-world counterparts
as possible. Objects can inherit properties from other objects,
and you can create complex relationships between different objects.
Figure 12.4 : The OODBMS paradigm.
In theory, the OODBMS is faster and more efficient than its relational counterparts and is easily portable and reusable. In reality, programming an OODBMS can be extremely difficult and requires careful planning and forethought. Although scientific and other applications have found OODBMS useful, and although "object-oriented" has been a significant catch phrase for the past decade, the OODBMS is not as common as the RDBMS. Partially because of their relatively limited use and largely because of my own ignorance on the topic, I do not discuss OODBMS implementations in this chapter.
The abstract relational database model is a two-dimensional table; however, several ways of implementing such a model in your software do exist. The implementation that you decide to use depends largely on your needs. The following sections briefly describe a few ways to implement a relational database and the advantages and disadvantages of each.
The simplest implementation of a relational database is to represent a table using a flat file (a text file). For example, a flat-file rolodex database might look like the following:
Eugene Kim:617-555-6218:eekim@hcs.harvard.eduEdward Yang:202-555-2545:edyang@med.cornell.eduJohn Stafford::stafford@mail.navy.mil
Each line represents a different record in the database, and each column represents an attribute of the record-in this case, name, phone number, and e-mail address. The columns are delimited by a colon, a somewhat arbitrary choice. You can choose any character or string to separate the fields. Keep in mind that you must make sure that the delimiter does not appear in any of the fields. That is, if one of the names contains a colon, you must escape that character either by preceding it with some other character or by using some other means of representation (such as hexadecimal encoding).
Parsing through a text file is straightforward in most languages. In Perl, to separate a line into its respective components, you use the split() function. The syntax for split() is
split(regexp,string)
where regexp is the delimiter and string is the string. split() returns a list of each item.
To separate the string into its components in C, you use the strtok() command from <string.h>:
char *strtok(char *s,const char *delim)
The first time you call strtok(), s is the string you want to parse and delim is the delimiter. It returns the first entry in the string. Subsequent calls to strtok() (with NULL as s) return subsequent entries in the string.
Querying this database is equivalent to doing a string search on one or all of the fields on a line. You can either extract each field from the line-using split() in Perl or strtok() in C-and search specific fields, or you can just search the string. Because you need to parse through the entire file to perform searches, flat files are slow for large databases.
Adding records to this database is straightforward in any language: you just append to the file. The processes of deleting and editing the database are a little more complex and require reading a whole copy of the database and selectively writing to a new file. This process is also slow and inefficient for larger databases.
Although a flat-file database is not a good system for large, complex databases, it is excellent for smaller, simpler database storage. It has the added advantage of needing no tools other than a text editor to modify and possibly fix the data.
Another simple means of storing a relational database is by using your operating system's file system. Most file systems closely follow the relational paradigm with a directory representing a table, a file representing a row in the table, and the data in the file representing the column attributes.
Implementing a file system-based database is also fairly straightforward, and has many advantages over the flat-file implementation. Adding or deleting a record means creating or deleting a file. Editing a record does not require parsing through a large text file as the flat-file method does; instead, you need to edit just one file. A file-system database also provides better support for a multiuser database. With a flat-file database, any time users modify the file in any way the file must be locked so that others cannot modify it simultaneously. Because the records are separate entities in a file-system database, you can lock individual records and still allow other users to modify other records simultaneously.
Querying, although often more efficient than looking up each individual
record, is more
challenging using a file-system database. Using the preceding
Perl and C examples, imagine implementing a rolodex application
using the file system. You no longer have the querying flexibility
you had with the flat file unless you are willing to open and
parse each individual file record, a more expensive and far less
efficient means of querying.
First, decide what you want to name the files. Assuming each name in the database is unique (an unrealistic assumption), you could name each file lastname_firstname. Remember, you are also constrained by the file-system naming conventions. On a DOS system, you have only eight characters and a three-letter extension with which to work; on both DOS and UNIX systems, you are not allowed to have certain characters in the filename. Now, to query your database using the name as the key, you compare each filename in the directory with the desired name. After you find it, you access the record.
By itself, this system does not seem more efficient than a flat-file database. However, you can improve this model by taking advantage of the directory hierarchy. You can create a directory for each letter in the alphabet, for example, and store files starting with the same letter in the appropriate directory. Now, when you are querying by name, instead of searching all the records, you search only the records that begin with the same letter.
Depending on your application, you can create a directory structure that makes such queries more efficient. If you are more likely to be querying by phone number, for example, you can create directories for each area code or for three-number prefixes. However, this structure limits your query flexibility. Additionally, because of the file-system naming constraints, naming a file or directory after the content of some field in a record is not always feasible.
You can address some of these flaws by creating in each directory an index file that contains a mapping from certain query fields to filenames. Because this solution is simply adding a flat-file database to improve the querying capability of a file-system database, you introduce other constraints even though you solve some problems.
Accessing data in the preceding two implementations is a linear operation. The more data that exists, the longer parsing through the data takes. UNIX provides a standard set of database routines called the DBM library to store and retrieve data.
| Note |
Several different implementations of the UNIX DBM library exist. Most of the differences are internal, and newer versions overcome size and other constraints in prior versions. I highly recommend the Berkeley DB library (available at URL:ftp://ftp.cs.berkeley.edu/), which offers three different types of structures for storing and retrieving the data. In general, it is a more flexible and usable programming library. |
The DBM library is a single-user database that stores data as key/content pairs. It is used in several standard UNIX applications from sendmail to the vacation program. Both the key and content are represented by the following structure, where dptr is a pointer pointing to the data (a string) and dsize is the size of the data:
typedef struct {
char *dptr;
int dsize;
} datum;
The DBM library provides several routines for opening and closing databases and for adding, modifying, deleting, and retrieving data. Although the function names differ for various implementations of the library, the concept is the same. I use the original DBM function names as an example; consult the documentation for your library for the specific implementation details.
You use a special function called dbminit(char *filename) to open the database. This function searches for the files filename.pag and filename.dir, which store the database information. If the function cannot find these files, it creates them. You are then free to store, delete, or retrieve data from the database using the functions store(datum key, datum content), delete(datum key), and fetch(datum key), respectively. You can parse through each key/content pair in a database using the following:
datum key;
for (key = firstkey(); key.dptr != NULL; key = nextkey(key))
;
Perl 4 offers a nice interface to the DBM library using associative arrays. To open a database, use the function
dbmopen(assoc,dbname,mode)
where assoc is the name of the associative array bound to the database, dbname is the name of the database, and mode is the UNIX protection mode used to open the database. If, for example, you have the DBM database rolodex keyed by last name and opened in Perl using the following line, then retrieving, adding, and deleting records require manipulation of the associative array %rolo:
dbmopen(%rolo,"rolodex",0600);
To retrieve the key "Johnson", for example, you access the value of $rolo{"Johnson"}. To add a new entry keyed by "Schmoe", you assign the value to $rolo{"Schmoe"}, as in the following:
$rolo{"Schmoe"} = "Joe Schmoe:818-555-1212";
After you finish with the database, you close the database using the function dbmclose(assoc), where assoc is the name of the associative array bound to the database.
| Note |
In Perl 5, the dbmopen() and dbmclose() functions are obsolete. Implementing DBM routines in Perl 5 requires object-oriented packages written to interface some of the newer libraries with Perl 5. Although the database open and close functions are different, the concept is the same: the database is bound to some associative array. For specific instructions, consult your Perl manual. |
As with the other implementations, the DBM library has several constraints. First, its querying capability is limited because it allows for only one key. If you want more flexible queries, you need to implement a mapping function that maps query types from one field to database keys. Second, DBM was not designed for associating multiple content with one key. Again, you can get around this constraint by carefully constructing your content; for example, you can use a delimiting character to separate multiple entries in one content field. Third, DBM is not a multi-user database. It does not have any built-in capability for either database locking or individual record locking. This is a fairly large disadvantage for Web programmers, although you can also circumvent this constraint with some clever programming. Debugging DBM libraries is more difficult because the format is binary rather than text. Finally, some versions of the DBM library contain various system constraints.
All the implementations discussed so far in this chapter have several inherent constraints. Depending on your needs, these constraints might be too important to ignore. If you find your needs go beyond those provided by the simple implementations discussed previously, you probably need to invest in a commercial database system. Good databases exist for all platforms and are usually multiuser, multiple-content, client/server databases with no theoretical size limits. The additional power comes at a price: commercial databases range in cost from a few hundred to a few thousand dollars. Several commercial databases come with library support for easy integration into your CGI applications or even direct integration with your Web server.
Every good commercial database comes with support for SQL. As discussed previously, SQL is a standard and powerful language for querying a database. Some databases come with a querying client that interprets SQL commands and returns data from the database; they can be included in your CGI applications using the techniques discussed in Chapter 11, "Gateways." Other databases come with APIs, so you can directly query the databases.
Although part of the querying limitations of the preceding implementations are inherent to the database structure, you do not need a powerful commercial database storage system to take advantage of SQL. One notable example is the shareware mSQL (mini-SQL) database for UNIX systems, a client/server multiuser database that uses a flat file to store the data. mSQL is fairly well used, and CGI, Perl, and Java interfaces are available. mSQL is available at <URL:ftp://bond.edu.au/pub/Minerva/msql/>.
The Web is commonly used as a way to retrieve information from a database. In the following sections, you learn a simple CGI database retrieval program that introduces some important concepts for later applications. Additionally, you learn some methods for implementing a keyword search on your Web site.
Because I am fond of rolodexes, I have designed a simple CGI rolodex application in C. This CGI program is purely for parsing and retrieving information from the database; it has no provisions for modifying the database or for creating new ones. The database must store first and last names and phone numbers, nothing more. For simplicity's sake, assume that no last name contains the colon character, so you can use the colon as a delimiting character. Finally, queries are limited to exact matches of last names.
A flat-file database is well-suited to this kind of small and simple application. The rolodex data file looks like the following:
lastname:firstname:phone
Multiple people can have the same last name; if this is the case, the CGI application will return all matching results. Assume, also, that line length cannot exceed 80 characters so that you can use the fgets() function to parse the text file.
The form for this application requires only one text field, and can be embedded into the CGI application. The text field, called query, accepts the last name to search for in the database. Because the application is written in C, you can use the strtok() function to retrieve the first field of each line in the database, compare the field with the query string, and print the complete field if they match.
The code for rolodex.c appears in Listing 12.1. Although this specific example is somewhat contrived, it is not completely unrealistic. Several applications could use code as simple as or just a little more complicated than rolodex.c. In this example, the code for querying the database is low-level. You could easily modify rolodex.c to use more complex databases and do fancier queries by either using an included query program and using the gateway techniques discussed in Chapter 11 or by using functions provided by the database programming library. Unless you are writing a complex database format from scratch, the code for your CGI application does not need to be much longer than that in rolodex.c, even for more complex database queries.
Listing 12.1. The rolodex.c example.
#include <stdio.h>
#include <string.h>
#include "cgi-lib.h"
#include "html-lib.h"
#include "string-lib.h"
#define dbase_file "/usr/local/etc/httpd/dbases/rolo"
int main()
{
llist *entries;
char *query;
char line[80];
FILE *dbase;
short FOUND = 0;
if (read_cgi_input(&entries)) {
query = newstr(cgi_val(entries,"query"));
html_header();
if ((dbase = fopen(dbase_file,"r")) == 0) {
html_begin("Can't Open Database");
h1("Can't Open Database");
html_end();
exit(1);
}
html_begin("Query Results");
h1("Query Results");
printf("<ul>\n");
while (fgets(line,80,dbase) != NULL) {
if (strcmp(query,strtok(line,":"))) {
FOUND = 1;
printf(" <li>%s %s, %s\n",strtok(NULL,":"),query,strtok(NULL,":"));
}
}
if (!FOUND)
printf(" <li>No items found\n");
printf("</ul>\n");
html_end();
}
else {
html_header();
html_begin("Query Rolodex");
h1("Query Rolodex");
printf("<form>\n");
printf("Enter last name: <input name=\"query\">\n");
printf("</form>\n");
html_end();
}
list_clear(&entries);
}
How can you use the techniques described in the preceding section to implement a keyword search on your Web site? Conceptually, a Web site is a file-system database. Each HTML file is a record that consists of one column: the content of the file. One way, then, to write a keyword search CGI program would be to have the program search all the files in the document tree of your Web server every time the program is called. For small Web sites with relatively low access, this solution may be feasible.
| Tip |
A good Perl utility called htgrep searches your document tree for keywords. It is easily extended to use as a CGI program. You can find htgrep at <URL:http://iamwww.unibe.ch/~scg/Src/Doc/htgrep.html>. |
| Tip |
One way to determine the time it takes to search for a keyword in your document tree on a UNIX system is to use the grep and find commands. Assuming your document root is /usr/local/etc/httpd/htdocs/, you can search all your HTML files for the keyword cat using the following command: grep cat 'find /usr/local/etc/httpd/htdocs -type f' |
For any Web site with a large document tree or many hits, the GREP utility as a solution is inadequate. You can greatly speed the process of searching for keywords if you index the keywords of your documents into one central index and use a CGI program to search that index. Essentially, this process entails converting your file-system database into a more efficient flat-file or other kind of database. This new database would contain keywords and the location of all the documents containing that keyword.
Developing a good indexing tool is a challenging project. At this time, reinventing the wheel is almost certainly not worth the time and effort. If, for some reason, none of the existing packages provides the functionality you need, you should have a strong enough conceptual understanding at this point to develop your own indexing and CGI query tool.
Several good indexing tools currently exist. Some common tools
are listed in Table 12.1. Most of them come with two programs:
an indexing tool and a query program. To use these applications,
configure the indexing application and run it periodically on
the appropriate document tree. Creating a CGI program that queries
this database usually is a matter of running the included querying
tool and parsing the results.
| Isite and Isearch | http://www.cnidr.org/
(free implementations of WAIS) |
| SWISH | http://www.eit.com/software/swish/swish.html |
| Harvest | http://harvest.cs.colorado.edu/ |
| Glimpse | ftp://ftp.cs.arizona.edu/glimpse/ |
The most common of these indexing tools is WAIS (Wide Area Information Server). WAIS was designed to serve searchable databases of information to clients on the Internet. Although you rarely find people who use the WAIS client to access WAIS databases on the Internet, Web-to-WAIS applications are common. WAIS is complex and very powerful, and you might find that many of its features are unnecessary. A simpler, WAIS-like indexing program is EIT's SWISH, a program specifically designed to index Web sites and to be easily configurable. EIT also has a Web interface to both SWISH and WAIS indices called WWWWAIS. Two other tools you might want to consider are Harvest and Glimpse, both of which were designed for creating easy-to-search archives over the Internet.
This chapter ends with a full-featured CGI application that performs all sorts of database applications. This past year, my dormitory obtained funding to start a movie collection. The two house tutors who maintain this video library keep a list of all the movies in the collection with their annotations. They want this list on the Web.
The simplest way to put this list on the Web would be for the tutors to convert the list to HTML manually, updating the list when necessary. This solution is undesirable for several reasons. First, the list is fairly long; converting it to HTML would be time-consuming. Second, both tutors, although computer-literate, are unfamiliar with HTML and UNIX. We need a better, easier way to allow the tutors to modify this list of movies easily. Third, we can think of no reason why only the tutors should be able to annotate each video. We want a mechanism that will easily enable students and others to contribute comments about individual movies.
The best solution is to design a CGI application that will enable anyone to see the list of movies, read the descriptions, and add comments. Additionally, we need a separate application that enables the administrators to add new entries, delete old entries, and modify existing ones. Because the application will require a lot of parsing and because I want to write this application quickly, I decided to write the application in Perl.
Before I design any of the applications, I need to determine how to store the information. Each movie has the following attributes:
Additionally, each movie can also store the following:
We have several movies, and the collection is growing. Adding, deleting, and editing fields in records are going to be common tasks. Because each record is somewhat large (definitely longer than an 80-character line) and because we need to modify records easily, a file-system database seems ideal. Each file will contain the preceding attributes with one file per movie. Adding a movie means adding another file; deleting a movie means removing a file. We can easily edit two different records in the database simultaneously because we won't need to lock the entire database to edit individual records.
What should I call each individual file? People will query the database only for movie titles, so it seems appropriate to make the filename the movie title. However, most movie titles have several words and often contain punctuation marks that are not valid characters in filenames. I have decided to use an index file that maps title names to the filenames. When we create new records, the filename will be generated using a combination of the current time and the process ID of the CGI application, as follows:
$filename = time.".".$$;
while (-e $dbasedir.$filename) {
$filename = time.".".$$;
}
Although it is unlikely that the filename already exists, I will add the while loop to check to see whether the filename does exist just in case.
The index file contains the filename and the title of the movie separated by two pipe characters (||). The likelihood of a movie title containing two consecutive pipes is slim, and the likelihood of the filename containing this delimiting string is nil. Although this assumption is safe for this application, we filter out these characters from the title just in case. The index file looks like the following:
12879523.1234||Star Wars
98543873.2565||The Shawshank Redemption
Parsing the index file means using the split() function:
($filename,$title) = split(/\|\|/,$line);
The index file and the records are all stored in the same directory, stored in the variable $dbasedir. The name of the index file is stored in $indexfile. Both these variables are stored in a global header file, video.ph.
Each record contains a field identifier directly followed by an equal sign (=) and the value of the field surrounded by braces ({}). Once again, although it is unlikely that any item in the record contains braces, filtering them out is necessary. As an exercise, instead of filtering out the braces, I will encode the braces character using hexadecimal encoding (the same encoding scheme URL encoding uses). Encoding braces using hexadecimal notation means encoding the percent symbol as well. Listing 12.2 contains the hexadecimal encoding and decoding functions.
Listing 12.2. The hexadecimal encode and decode functions.
sub encode {
local($data) = @_;
$data =~ s/([\%\{\}])/uc sprintf("%%%02x",ord($1))/eg;
return $data;
}
sub decode {
local($data) = @_;
$data =~ s/%([0-9a-fA-F]{2})/pack("c",hex($1))/ge;
return $data;
}
Listing 12.3 contains a sample record file. Both the LINK and ANNOTATE fields are optional. In Chapter 10, "Basic Applications," I use some Perl code to parse a similar-looking configuration file. Slightly modifying that code produces the Perl record parser in Listing 12.4.
Listing 12.3. A sample record file.
TITLE={Rumble in the Bronx}
DIRECTORS={Stanley Tong}
ACTORS={Jackie Chan}
DESCRIPTION={A fast-paced action film, Jackie Chan displays his
incredible athleticism in this non-stop, beautifully choreographed
film. Fun to watch; we give it a two thumbs up!}
LINK={http://www.rumble.com/}
ANNOTATE={Jackie Chan is nothing compared to Arnold! Go Arnold!
Terminator forever!}
Listing 12.4. Code to parse database records.
# read fields of each record
open(RECORD,$dbasedir.$filename)
|| &CgiDie("Error","Couldn't Open Record");
$/ = '}';
while ($field = <RECORD>) {
$field =~ s/^[\r\n]//;
if ($field =~ /^TITLE=\{/) {
($TITLE = $field) =~ s/^TITLE=\{//;
$TITLE =~ s/\}//;
$TITLE = &decode($TITLE);
}
elsif ($field =~ /^DIRECTORS=\{/) {
($DIRECTORS = $field) =~ s/^DIRECTORS=\{//;
$DIRECTORS =~ s/\}//;
$DIRECTORS = &decode($DIRECTORS);
}
elsif ($field =~ /^ACTORS=\{/) {
($ACTORS = $field) =~ s/^ACTORS=\{//;
$ACTORS =~ s/\}//;
$ACTORS = &decode($ACTORS);
}
elsif ($field =~ /^DESCRIPTION=\{/) {
# doesn't handle multi paragraphs correctly
($DESCRIPTION = $field) =~ s/^DESCRIPTION=\{//;
$DESCRIPTION =~ s/\}//;
$DESCRIPTION =~ s/</<\;/g;
$DESCRIPTION =~ s/>/>\;/g;
$DESCRIPTION = &decode($DESCRIPTION);
}
elsif ($field =~ /^LINK=\{/) {
($LINK = $field) =~ s/^LINK=\{//;
$LINK =~ s/\}//;
push(@links,$LINK);
}
elsif ($field =~ /^ANNOTATE=\{/) {
($ANNOTATE = $field) =~ s/^ANNOTATE=\{//;
$ANNOTATE =~ s/\}//;
$ANNOTATE =~ s/</<\;/g;
$ANNOTATE =~ s/>/>\;/g;
push(@annotations,$ANNOTATE);
}
}
$/ = '\n';
close(RECORD);
Because records and the index are constantly being updated, I need to make sure that all the programs can read and write to the records. The Web server in question runs as user nobody group httpd. I will create the database directory, group-owned by httpd, and make it user- and group-readable, writeable, and executable. To make sure that the permissions on any modified or created file are correct, I must include the following command in the header file video.ph to set the permissions:
umask(017);
Now that I have created a database, I am ready to design the query engine. The query engine will do two things: it will display the list of movies available, and it will enable users to select movies to see more detailed information. Listing the movies is a matter of parsing the index file and displaying the data using the <select> form type. The user then can select the films about which he or she wants more details. After the user clicks the Submit button, the program reads and parses the selected records and displays them in HTML.
I have separated some common variables and functions into the
file video.ph, shown in Listing 12.5. The main query engine-video-is
in Listing 12.6. If called with no input, video reads the database
index file and displays a form. If there is input, it reads each
record, parsing the record using the code in Listing 12.4, and
displays it. Sample output from video is shown in Figures 12.5
and 12.6.
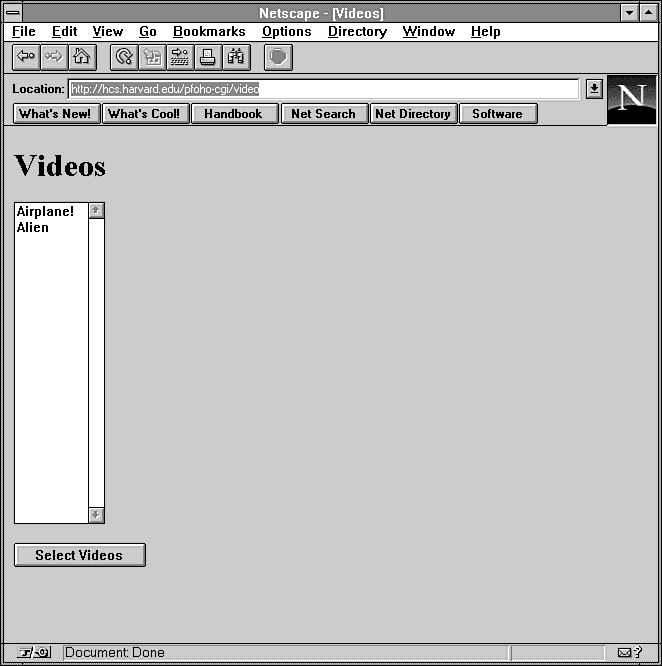
Figure 12.5 : The video query engine lists available movies.
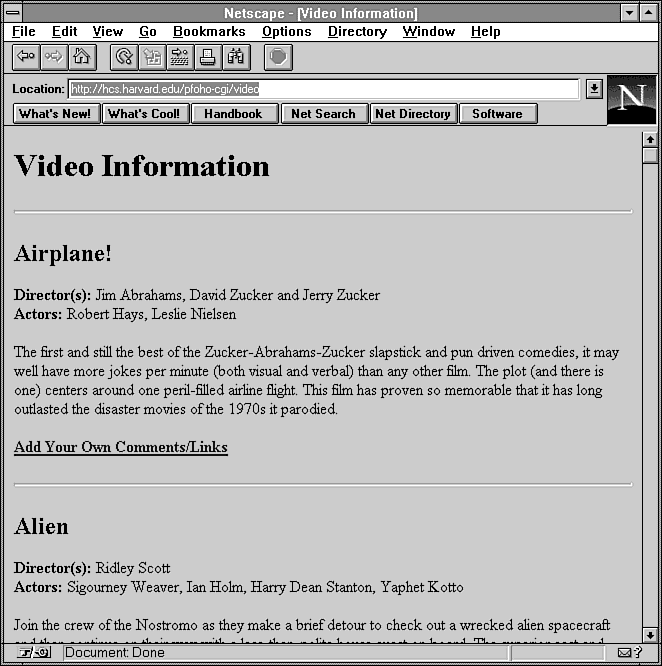
Figure 12.6 : The video query engine lists detailed descriptions of the movies.
Listing 12.5. The video.ph example.
# header file for video, annotate
$dbasedir = '/casa/groups/pfoho/vdbase/';
$indexfile = 'index';
$passwdfile = 'passwd';
$cgibin = '/pfoho-cgi';
# set default umask (-rw-rw----)
umask(017);
sub wait_for_lock {
local($file) = @_;
while (-e "$dbasedir$file.LOCK") {
sleep 2;
}
}
sub lock_file {
local($file) = @_;
open(LOCK,">$dbasedir$file.LOCK");
print LOCK "$$\n";
close(LOCK);
}
sub unlock_file {
local($file) = @_;
unlink("$dbasedir$file.LOCK");
}
sub encode {
local($data) = @_;
$data =~ s/([\%\{\}])/uc sprintf("%%%02x",ord($1))/eg;
return $data;
}
sub decode {
local($data) = @_;
$data =~ s/%([0-9a-fA-F]{2})/pack("c",hex($1))/ge;
return $data;
}
Listing 12.6. The main query engine-video.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
require 'video.ph';
# open index and map to associative array
open(INDEX,$dbasedir.$indexfile) || &CgiDie("Error","Couldn't Open Index");
while ($line = <INDEX>) {
$line =~ s/[\r\n]//g;
($filename,$title) = split(/\|\|/,$line);
$index{$title} = $filename;
}
close(INDEX);
if (&ReadParse(*input)) { # retrieve dbase items
print &PrintHeader,&HtmlTop("Video Information");
print "<hr>\n";
foreach $filename (split("\0",$input{'video'})) {
# clear @links and @annotations
@links = ();
@annotations = ();
# read fields of each record
open(RECORD,$dbasedir.$filename)
|| &CgiDie("Error","Couldn't Open Record");
$/ = '}';
while ($field = <RECORD>) {
$field =~ s/^[\r\n]//;
if ($field =~ /^TITLE=\{/) {
($TITLE = $field) =~ s/^TITLE=\{//;
$TITLE =~ s/\}//;
$TITLE = &decode($TITLE);
}
elsif ($field =~ /^DIRECTORS=\{/) {
($DIRECTORS = $field) =~ s/^DIRECTORS=\{//;
$DIRECTORS =~ s/\}//;
$DIRECTORS = &decode($DIRECTORS);
}
elsif ($field =~ /^ACTORS=\{/) {
($ACTORS = $field) =~ s/^ACTORS=\{//;
$ACTORS =~ s/\}//;
$ACTORS = &decode($ACTORS);
}
elsif ($field =~ /^DESCRIPTION=\{/) {
# doesn't handle multi paragraphs correctly
($DESCRIPTION = $field) =~ s/^DESCRIPTION=\{//;
$DESCRIPTION =~ s/\}//;
$DESCRIPTION =~ s/</<\;/g;
$DESCRIPTION =~ s/>/>\;/g;
$DESCRIPTION = &decode($DESCRIPTION);
}
elsif ($field =~ /^LINK=\{/) {
($LINK = $field) =~ s/^LINK=\{//;
$LINK =~ s/\}//;
push(@links,$LINK);
}
elsif ($field =~ /^ANNOTATE=\{/) {
($ANNOTATE = $field) =~ s/^ANNOTATE=\{//;
$ANNOTATE =~ s/\}//;
$ANNOTATE =~ s/</<\;/g;
$ANNOTATE =~ s/>/>\;/g;
push(@annotations,$ANNOTATE);
}
}
$/ = '\n';
close(RECORD);
# print fields
print "<h2>$TITLE</h2>\n";
print "<p><b>Director(s):</b> $DIRECTORS<br>\n";
print "<b>Actors:</b> $ACTORS</p>\n\n";
print "<p>$DESCRIPTION</p>\n\n";
if ($#links != -1) {
print "<h3>Links</h3>\n";
print "<ul>\n";
foreach $link (@links) {
print " <li><a href=\"$link\">$link</a>\n";
}
print "</ul>\n\n";
}
if ($#annotations != -1) {
print "<h3>Other Comments</h3>\n";
foreach $annotation (@annotations) {
print "<p>$annotation</p>\n\n";
}
}
print "<p><b><a href=\"$cgibin/annotate?$index{$TITLE}\">";
print "Add Your Own Comments/Links</a></b></p>\n\n";
print "<hr>\n\n";
}
print &HtmlBot;
}
else { # show list
# print list
print &PrintHeader,&HtmlTop("Videos");
print "<form method=POST>\n";
print "<select name=\"video\" size=20 MULTIPLE>\n";
foreach $key (sort(keys %index)) {
print "<option value=\"$index{$key}\">$key\n";
}
print "</select>\n";
print "<p><input type=submit value=\"Select Videos\"></p>\n";
print "</form>\n";
print &HtmlBot;
}
When video displays the detailed information of each record, it also gives the option of adding a user-contributed annotation or link. To do so, it calls the program annotate. The program annotate uses a strategy commonly used in CGI multipart forms, which is briefly discussed in Chapter 6, "Programming Strategies," and discussed in great detail in Chapter 13, "Multipart Forms and Maintaining State." The first form that annotate displays gets the annotation and/or links from the user for a specific film. When the user clicks the Submit button, the same link is called. However, because the Web is stateless, you need to somehow pass the appropriate state information-in this case, the filename of the record-to the CGI program. This state can be passed in several ways (all of which are discussed in Chapter 13).
In annotate, I pass the filename in the URL. To process the information,
the CGI program first checks to see if information exists in the
QUERY_STRING environment
variable. If state information appears in QUERY_STRING,
annotate then determines whether additional information has been
submitted via the POST method.
If it has, then the environment variable REQUEST_METHOD
is set to POST; otherwise,
it is equal to GET. The cgi-lib.pl
function &MethGet returns
True if the CGI is called
using method GET and False
if the CGI is called using the POST
method. Listing 12.7 contains the skeleton code for passing state
information to the CGI application; I use this basic format several
times throughout the remote administration application. Listing
12.8 contains the full source code for the annotate program, and
Figure 12.7 shows what annotate looks
like.
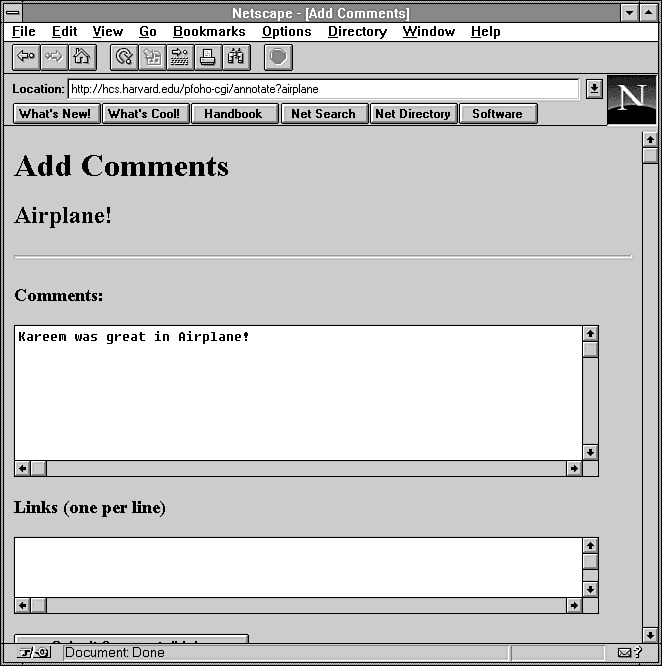
Figure 12.7 : The annotate program in use.
Listing 12.7. Skeleton code for multipart forms.
if ($ENV{'QUERY_STRING'}) { # can add some sort of state condition here as well
if (!&MethGet && &ReadParse(*input)) {
# state + additional input submitted
}
else {
# state and no additional input passed; probably just need
# to display form here
}
}
Because annotate is actually modifying a record, it needs to check to make sure that no one else is using the record, create a lock, perform the action, and then unlock the file. Reusing some of the code used in Chapter 5, "Input," I created the &wait_for_lock, &lock_file, and &unlock_file functions, located in video.ph in Listing 12.5.
Listing 12.8. The full source code for annotate.
#!/usr/local/bin/perl
require 'cgi-lib.pl';
require 'video.ph';
$recordname = $ENV{'QUERY_STRING'};
if ($recordname) {
if (!&MethGet && &ReadParse(*input)) { # add info to database
$comment = $input{'comments'};
$comment = &encode($comment);
@templinks = split(/\n/,$input{'links'});
@links = grep(!/^$/,@templinks);
&wait_for_lock($recordname);
&lock_file($recordname);
open(RECORD,">>$dbasedir$recordname") ||
&CgiDie("Error","Couldn't Open Record");
print RECORD "ANNOTATE={$comment}\n" unless (!$comment);
foreach $link (@links) {
print RECORD "LINK={$link}\n";
}
close(RECORD);
&unlock_file($recordname);
print &PrintHeader,&HtmlTop("Added!");
print &HtmlBot;
}
else { # show form
# check index; map filename to title
open(INDEX,$dbasedir.$indexfile)
|| &CgiDie("Error","Couldn't Open Index");
while ($line = <INDEX>) {
$line =~ s/[\r\n]//g;
($filename,$title,$sum,$num) = split(/\|\|/,$line);
$index{$filename} = $title;
}
close(INDEX);
# print form
print &PrintHeader,&HtmlTop("Add Comments");
print "<h2>$index{$recordname}</h2>\n";
print "<hr>\n";
print "<form action=\"$cgibin/annotate?$recordname\" ";
print "method=POST>\n";
print "<h3>Comments:</h3>\n";
print "<textarea name=\"comments\" rows=8 cols=70></textarea>\n";
print "<h3>Links (one per line)</h3>\n";
print "<textarea name=\"links\" rows=3 cols=70></textarea>\n";
print "<p><input type=submit value=\"Submit Comments/Links\">\n";
print "</form>\n";
print &HtmlBot;
}
}
The most difficult application in the video library is the administration tool. Video is a straightforward application; it simply queries and displays records from the database. Although annotate is slightly more complex, it too did not require a lot of complex coding.
The administration tool-called vadmin-has several requirements:
Password protecting the CGI program means using the server file access feature. The program runs on an NCSA server, so I created a special administrator's directory in the cgi-bin and protected it using the .htaccess file in Listing 12.9.
Listing 12.9. The .htaccess file.
AuthUserFile /casa/groups/pfoho/vdbase/passwd
AuthGroupFile /casa/groups/pfoho/vdbase/group
AuthName VideoAdministration
AuthType Basic
<Limit GET POST>
require group vadmin
</Limit>
The .htaccess file specifies the location of a file containing usernames and passwords for authentication and a group file containing group information for users. The password file (in Listing 12.10) contains two fields: the username and the encrypted password separated by a colon. Passwords are encrypted using the standard crypt() function provided on UNIX systems. The group file (in Listing 12.11) contains the users authorized to access the vadmin administrator's program.
Listing 12.10. The password file.
jschmoe:2PldoDpQHpVvA
eekim:rsNjOB6tfy0rM
Listing 12.11. The group file.
vadmin: jschmoe eekim
| Note |
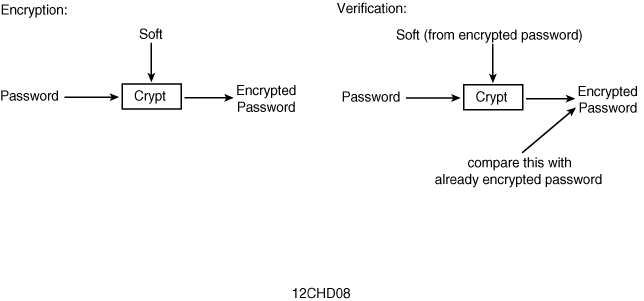
The standard crypt() function, available on all UNIX systems, uses DES encryption, which is a one-way encrypting algorithm. This means that you need the password to decode the password (see Figure 12.8). crypt() takes two parameters: the password and something called the salt. The salt is a two-character alphanumeric string that is used to encrypt the password. The salt value is the first two characters of the encrypted password. @saltchars = ('a' 'z','A' 'Z','0' '9',' ','/'); To verify a password, you encrypt the given password using the two-character salt from the encrypted password. Both encrypted passwords should be equal: $salt = substr($npasswd,0,2); |
Figure 12.8 : crypt () in a nusthell.
Using the state framework presented in Listing 12.7 and some of
the common routines used in both video and annotate, I can write
the code for vadmin as listed in Listing 12.12. The various looks
of vadmin are shown in Figures 12.9 through
12.12.
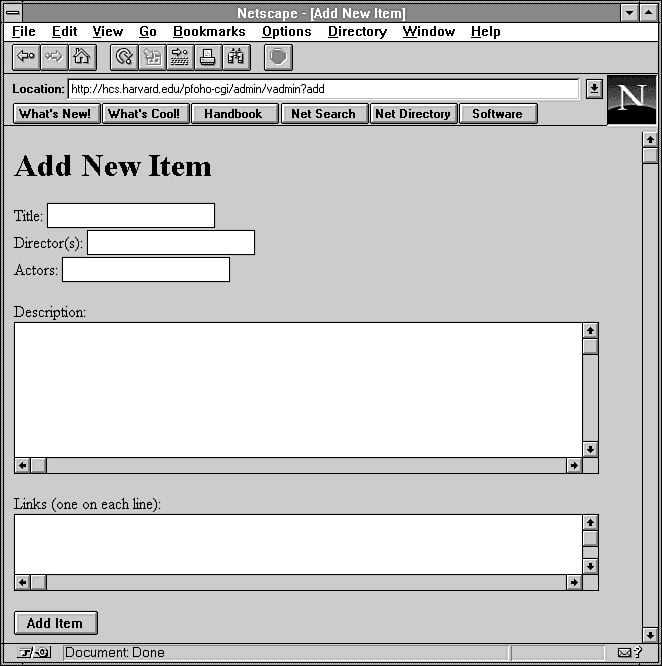
Figure 12.9 : Using vadmin to add a new entry.
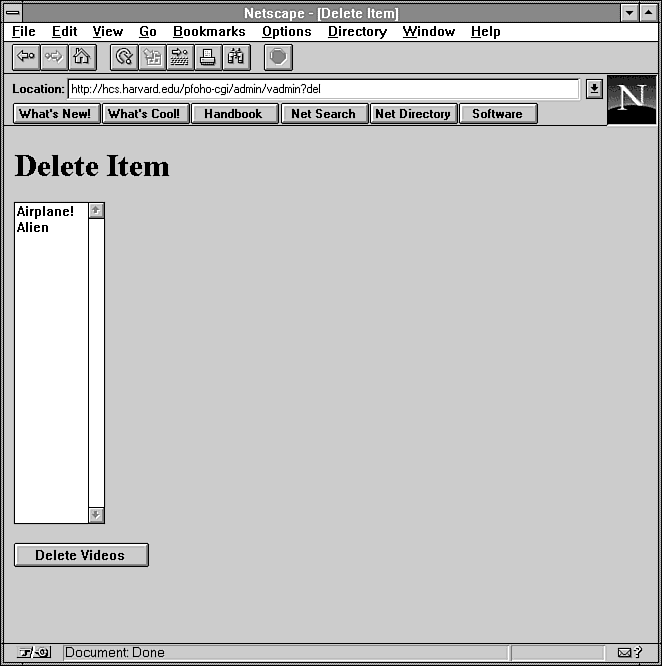
Figure 12.10 : Using vadmin to delete entries.
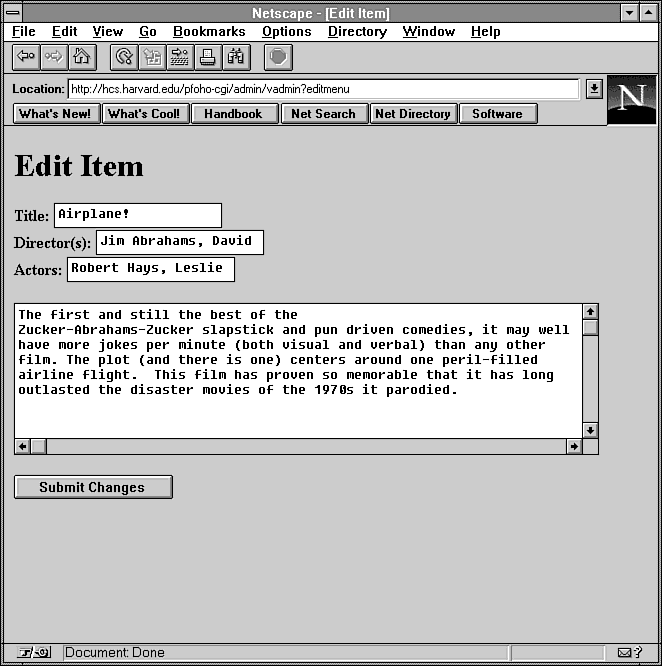
Figure 12.11 : Using vadmin to edit an old entry.
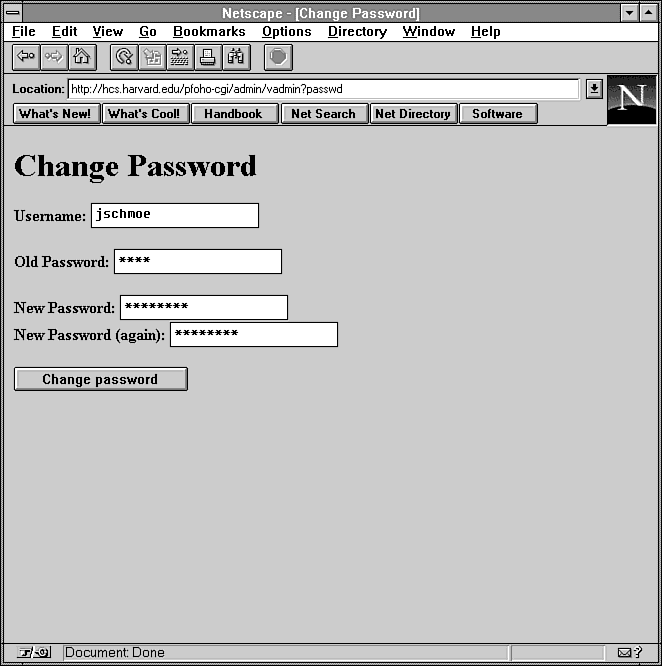
Figure 12.12 : Using vadmin to change the administrator's password.
Listing 12.12. The administrator's program-vadmin.
#!/usr/local/bin/perl
require '../cgi-lib.pl';
require '../video.ph';
$command = $ENV{'QUERY_STRING'};
if ($command eq "add") {
if (!&MethGet && &ReadParse(*input)) {
# create new record
$filename = time.".".$$;
while (-e $dbasedir.$filename) {
$filename = time.".".$$;
}
&wait_for_lock($filename);
&lock_file($filename);
open(RECORD,">$dbasedir$filename")
|| &CgiDie("Error","Couldn't Write New Record");
$input{'title'} =~ s/\|\|//g; # remove double pipes just in case
print RECORD "TITLE=\{".&encode($input{'title'})."\}\n";
print RECORD "DIRECTORS=\{".&encode($input{'directors'})."\}\n";
print RECORD "ACTORS=\{".&encode($input{'actors'})."\}\n";
print RECORD "DESCRIPTION=\{".&encode($input{'description'})."\}\n";
if ($input{'links'}) {
@templinks = split(/\n/,$input{'links'});
@links = grep(!/^$/,@templinks);
foreach $link (@links) {
print RECORD "LINK={$link}\n";
}
}
close(RECORD);
&unlock_file($filename);
# update index
&wait_for_lock($indexfile);
&lock_file($indexfile);
open(INDEX,">>$dbasedir$indexfile")
|| &CgiDie("Error","Can't update index");
print INDEX "$filename||$input{'title'}||||\n";
close(INDEX);
&unlock_file($indexfile);
# send success message
print &PrintHeader,&HtmlTop("Record Added");
print &HtmlBot;
}
else {
&form_add;
}
}
elsif ($command eq "del") {
if (!&MethGet && &ReadParse(*input)) {
open(INDEX,$dbasedir.$indexfile)
|| &CgiDie("Error","Couldn't Open Index");
while ($line = <INDEX>) {
$filename = (split(/\|\|/,$line))[0];
$index{$filename} = $line;
}
close(INDEX);
# delete file and update array
foreach $filename (split("\0",$input{'video'})) {
&wait_for_lock($filename);
unlink($dbasedir.$filename)
|| &CgiDie("Error","Can't delete record");
delete $index{$filename};
}
# backup and update index file
&wait_for_lock($indexfile);
&lock_file($indexfile);
rename($dbasedir.$indexfile,"$dbasedir$indexfile.bak");
open(INDEX,">$dbasedir$indexfile")
|| &CgiDie("Error","Couldn't Open Index");
foreach $key (sort(keys(%index))) {
print INDEX $index{$key};
}
close(INDEX);
&unlock_file($indexfile);
# send success message
print &PrintHeader,&HtmlTop("Records Deleted");
print &HtmlBot;
}
else {
&form_del;
}
}
elsif ($command eq "editmenu") {
if (!&MethGet && &ReadParse(*input)) {
# open file
open(RECORD,$dbasedir.$input{'video'})
|| &CgiDie("Error","Can't Open Record");
$/ = '}';
while ($field = <RECORD>) {
$field =~ s/^[\r\n]//;
if ($field =~ /^TITLE=\{/) {
($TITLE = $field) =~ s/^TITLE=\{//;
$TITLE =~ s/\}//;
$TITLE = &decode($TITLE);
}
elsif ($field =~ /^DIRECTORS=\{/) {
($DIRECTORS = $field) =~ s/^DIRECTORS=\{//;
$DIRECTORS =~ s/\}//;
$DIRECTORS = &decode($DIRECTORS);
}
elsif ($field =~ /^ACTORS=\{/) {
($ACTORS = $field) =~ s/^ACTORS=\{//;
$ACTORS =~ s/\}//;
$ACTORS = &decode($ACTORS);
}
elsif ($field =~ /^DESCRIPTION=\{/) {
# doesn't handle multi paragraphs correctly
($DESCRIPTION = $field) =~ s/^DESCRIPTION=\{//;
$DESCRIPTION =~ s/\}//;
$DESCRIPTION =~ s/</<\;/g;
$DESCRIPTION =~ s/>/>\;/g;
$DESCRIPTION = &decode($DESCRIPTION);
}
elsif ($field =~ /^LINK=\{/) {
($LINK = $field) =~ s/^LINK=\{//;
$LINK =~ s/\}//;
push(@links,$LINK);
}
elsif ($field =~ /^ANNOTATE=\{/) {
($ANNOTATE = $field) =~ s/^ANNOTATE=\{//;
$ANNOTATE =~ s/\}//;
$ANNOTATE =~ s/</<\;/g;
$ANNOTATE =~ s/>/>\;/g;
push(@annotations,$ANNOTATE);
}
}
$/ = '\n';
close(RECORD);
# print edit form
print &PrintHeader,&HtmlTop("Edit Item");
print "<form action=\"$cgibin/admin/vadmin?edit\" method=POST>\n";
print "<input type=hidden name=\"record\" ";
print "value=\"$input{'video'}\">\n";
print "<p><b>Title:</b> ";
print "<input name=\"title\" value=\"$TITLE\"><br>\n";
print "<b>Director(s):</b> ";
print "<input name=\"directors\" value=\"$DIRECTORS\"><br>\n";
print "<b>Actors:</b> ";
print "<input name=\"actors\" value=\"$ACTORS\"></p>\n\n";
print "<p><textarea name=\"description\" rows=8 cols=70>\n";
print "$DESCRIPTION</textarea></p>\n\n";
if ($#links != -1) {
print "<h3>Edit Links</h3>\n";
print "<p>Check off items you want to delete.</p>\n";
print "<p>";
$i = 0;
foreach $link (@links) {
print "<input type=checkbox name=\"dl\" value=\"$i\">";
print "<input name=\"l$i\" value=\"$link\"><br>\n";
$i++;
}
print "</p>\n";
}
if ($#annotations != -1) {
print "<h3>Edit Annotations</h3>\n";
print "<p>Check off items you want to delete.</p>\n";
$i = 0;
foreach $annotation (@annotations) {
print "<p><input type=checkbox name=\"da\" value=\"$i\">";
print "<textarea name=\"a$i\" rows=8 cols=70>\n";
print "$annotation</textarea></p>\n";
$i++;
}
}
print "<p><input type=submit value=\"Submit Changes\"></p>\n";
print "</form>\n";
print &HtmlBot;
}
else {
&form_editmenu;
}
}
elsif ($command eq "edit") {
if (!&MethGet && &ReadParse(*input)) {
$filename = $input{'record'};
undef %dellinks;
undef %delnotes;
foreach $dlink (split("\0",$input{'dl'})) {
$dellinks{$dlink} = 1;
}
foreach $dnote (split("\0",$input{'da'})) {
$delnotes{$dnote} = 1;
}
$input{'title'} =~ s/\|\|//g; # remove double pipes just in case
# backup old record
rename($dbasedir.$filename,"$dbasedir$filename.bak")
|| &CgiDie("Error","Couldn't backup record");
# write new record
&wait_for_lock($filename);
&lock_file($filename);
open(RECORD,">$dbasedir$filename")
|| &CgiDie("Error","Couldn't Update Record");
print RECORD "TITLE=\{".&encode($input{'title'})."\}\n";
print RECORD "DIRECTORS=\{".&encode($input{'directors'})."\}\n";
print RECORD "ACTORS=\{".&encode($input{'actors'})."\}\n";
print RECORD "DESCRIPTION=\{".&encode($input{'description'})."\}\n";
$i = 0;
while ($input{"l$i"} && !$dellinks{$i}) {
print RECORD "LINK=\{".$input{"l$i"}."\}\n";
$i++;
}
$i = 0;
while ($input{"a$i"} && !$delnotes{$i}) {
print RECORD "ANNOTATE=\{".$input{"a$i"}."\}\n";
$i++;
}
close(RECORD);
&unlock_file($filename);
# update index with new title
# backup and update index file
&wait_for_lock($indexfile);
&lock_file($indexfile);
rename($dbasedir.$indexfile,"$dbasedir$indexfile.bak")
|| &CgiDie("Error","Can't backup index");
open(INDEX,"$dbasedir$indexfile.bak")
|| &CgiDie("Error","Can't Open Old Index");
open(NINDEX,">$dbasedir$indexfile")
|| &CgiDie("Error","Couldn't Open Index");
while ($line = <INDEX>) {
if ($line =~ /^$filename\|\|/) {
($fn,$ti) = split(/\|\|/,$line);
print NINDEX "$filename||$input{'title'}||$num||$sum";
}
else {
print NINDEX $line;
}
}
close(INDEX);
close(NINDEX);
&unlock_file($indexfile);
# send success message
print &PrintHeader,&HtmlTop("Record Updated");
print &HtmlBot;
}
else {
print "Location: $cgibin/admin/vadmin?editmenu\n\n";
}
}
elsif ($command eq "passwd") {
if (!&MethGet && &ReadParse(*input)) {
$uname = $input{'uname'};
$old = $input{'old'};
$new = $input{'new'};
$confirm = $input{'confirm'};
# open password file
$FOUND = 0;
open(PASSWD,$dbasedir.$passwdfile)
|| &CgiDie("Error","Can't open password file");
# check username
while (!$FOUND && ($line = <PASSWD>)) {
$line =~ s/[\r\n]//g;
($username,$password) = split(/:/,$line);
if ($username eq $uname) {
$FOUND = 1;
}
}
&CgiDie("Error","Invalid Username") unless ($FOUND);
# check old password
$salt = substr($password,0,2);
if (crypt($old,$salt) ne $password) {
&CgiDie("Error","Invalid Password");
}
# new=confirm?
&CgiDie("Error","New passwords don't match") unless ($new eq $confirm);
# change that badboy!
@saltchars = ('a'..'z','A' 'Z','0' '9',' ','/');
srand(time|$$);
$salt = splice(@saltchars,rand @saltchars,1);
$salt .= splice(@saltchars,rand @saltchars,1);
$npasswd = crypt($new,$salt);
# backup passwd file
&wait_for_lock($passwdfile);
&lock_file($passwdfile);
rename($dbasedir.$passwdfile,"$dbasedir$passwdfile.bak")
|| &CgiDie("Error","Can't backup password file");
open(PASSWD,"$dbasedir$passwdfile.bak")
|| &CgiDie("Error","Can't open password file");
open(NPASSWD,">$dbasedir$passwdfile")
|| &CgiDie("Error","Can't change password file");
while ($line = <PASSWD>) {
if ($line =~ /^$uname:/) {
print NPASSWD "$uname:$npasswd\n";
}
else {
print NPASSWD $line;
}
}
close(PASSWD);
close(NPASSWD);
&unlock_file($passwdfile);
# print success message
print &PrintHeader,&HtmlTop("Password changed!");
print &HtmlBot;
}
else {
&form_passwd;
}
}
else {
&form_menu;
}
sub form_menu {
print &PrintHeader,&HtmlTop("Welcome Admin!");
print <<EOM;
<ul>
<li><a href="$cgibin/admin/vadmin?add">Add New Item</a>
<li><a href="$cgibin/admin/vadmin?del">Delete Item</a>
<li><a href="$cgibin/admin/vadmin?editmenu">Edit Item</a>
<li><a href="$cgibin/admin/vadmin?passwd">Change password</a>
</ul>
EOM
print &HtmlBot;
}
sub form_add {
print &PrintHeader,&HtmlTop("Add New Item");
print <<EOM;
<form action="$cgibin/admin/vadmin?add" method=POST>
<p>Title: <input name="title"><br>
Director(s): <input name="directors"><br>
Actors: <input name="actors"></p>
<p>Description:<br>
<textarea name="description" rows=8 cols=70>
</textarea></p>
<p>Links (one on each line):<br>
<textarea name="links" rows=3 cols=70>
</textarea></p>
<p><input type=submit value="Add Item"></p>
</form>
EOM
print &HtmlBot;
}
sub form_del {
open(INDEX,$dbasedir.$indexfile)
|| &CgiDie("Error","Couldn't Open Index");
while ($line = <INDEX>) {
$line =~ s/[\r\n]//g;
($filename,$title) = split(/\|\|/,$line);
$index{$title} = $filename;
}
close(INDEX);
# print list
print &PrintHeader,&HtmlTop("Delete Item");
print "<form action=\"$cgibin/admin/vadmin?del\" method=POST>\n";
print "<select name=\"video\" size=20 MULTIPLE>\n";
foreach $key (sort(keys %index)) {
print "<option value=\"$index{$key}\">$key\n";
}
print "</select>\n";
print "<p><input type=submit value=\"Delete Videos\"></p>\n";
print "</form>\n";
print &HtmlBot;
}
sub form_editmenu {
open(INDEX,$dbasedir.$indexfile)
|| &CgiDie("Error","Couldn't Open Index");
while ($line = <INDEX>) {
$line =~ s/[\r\n]//g;
($filename,$title) = split(/\|\|/,$line);
$index{$title} = $filename;
}
close(INDEX);
print &PrintHeader,&HtmlTop("Edit Which Item?");
print "<form action=\"$cgibin/admin/vadmin?editmenu\" method=POST>\n";
print "<select name=\"video\" size=20>\n";
foreach $key (sort(keys %index)) {
print "<option value=\"$index{$key}\">$key\n";
}
print "</select>\n";
print "<p><input type=submit value=\"Edit Video\"></p>\n";
print "</form>\n";
print &HtmlBot;
}
sub form_passwd {
print &PrintHeader,&HtmlTop("Change Password");
print <<EOM;
<form action="$cgibin/admin/vadmin?passwd" method=POST>
<p><b>Username:</b> <input name="uname" value="$ENV{'REMOTE_USER'}"></p>
<p><b>Old Password:</b> <input type=password name="old"></p>
<p><b>New Password:</b> <input type=password name="new"><br>
<b>New Password (again):</b> <input type=password name="confirm"></p>
<p><input type=submit value=\"Change password\"></p>
</form>
EOM
print &HtmlBot;
}
Using some of the basic techniques discussed in this chapter, I can design and write a reasonably powerful, full-featured database CGI application. Although implementing many of the features is easy thanks to the text processing capability of Perl, using Perl has its drawbacks. Because I used Perl 4, which does not have strong typing, I cannot easily move commonly used code such as that used for parsing the record files into their own separate functions. Additionally, the many global variables make debugging a difficult endeavor for the administration program, a fairly large program considering it is barely modularized.
Given more time and decent motivation, I would like to rewrite this entire application in C. Not only would it improve performance, it would improve the quality of the source code at the cost, of course, of more coding. This is about as large a Perl application as you probably want to write without seriously modularizing it.
Although the combination of a file-system database with a flat-file index works well, as the video library grows very large, a faster database format for the index might be desirable. Modifying the code to use a DBM database for the index file rather than a flat file is fairly trivial. Given the proper tools, modifying this application to use a more powerful database implementation would not require too much additional work either.
If you're interested in seeing the real application in action, the URL is http://hcs.harvard.edu/pfoho-cgi/video.
A database is an organizational model for both representing and accessing data. Although several complex and powerful databases are available, you can use some relatively simple database implementations for some fairly powerful applications as shown in the example of the Online Video Library database. Properly programming a CGI interface to a database requires knowing how to open and close the database and how to retrieve information.
In this chapter, you saw how to use CGI programs to interface the Web with databases. Several different types of databases exist, ranging in complexity. You saw how to create a database, and then you were taken through the steps of designing the query engine.